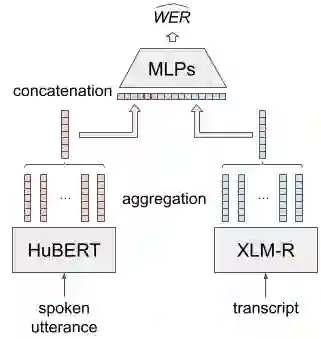
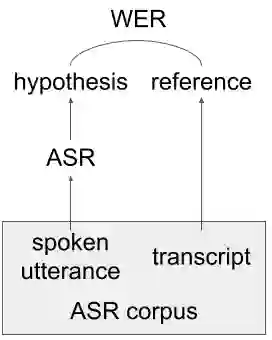
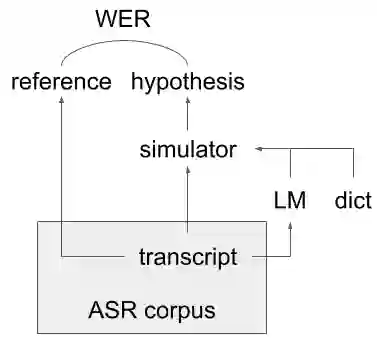
Word error rate (WER) is a metric used to evaluate the quality of transcriptions produced by Automatic Speech Recognition (ASR) systems. In many applications, it is of interest to estimate WER given a pair of a speech utterance and a transcript. Previous work on WER estimation focused on building models that are trained with a specific ASR system in mind (referred to as ASR system-dependent). These are also domain-dependent and inflexible in real-world applications. In this paper, a hypothesis generation method for ASR System-Independent WER estimation (SIWE) is proposed. In contrast to prior work, the WER estimators are trained using data that simulates ASR system output. Hypotheses are generated using phonetically similar or linguistically more likely alternative words. In WER estimation experiments, the proposed method reaches a similar performance to ASR system-dependent WER estimators on in-domain data and achieves state-of-the-art performance on out-of-domain data. On the out-of-domain data, the SIWE model outperformed the baseline estimators in root mean square error and Pearson correlation coefficient by relative 17.58% and 18.21%, respectively, on Switchboard and CALLHOME. The performance was further improved when the WER of the training set was close to the WER of the evaluation dataset.
翻译:词错误率(WER)是用于评估自动语音识别(ASR)系统生成的转录质量的指标。在许多应用中,给定一对语音片段及其转录,估计WER具有重要意义。以往关于WER估计的研究主要集中于构建针对特定ASR系统训练模型(即ASR系统依赖方法)。这些方法存在领域依赖性强、在实际应用中灵活性不足等问题。本文提出了一种用于ASR系统无关WER估计(SIWE)的假设生成方法。与以往工作不同,本文的WER估计器使用模拟ASR系统输出的数据进行训练。假设通过使用语音相似或语言上更可能的替代词生成。在WER估计实验中,所提方法在域内数据上达到了与ASR系统依赖的WER估计器相近的性能,并在域外数据上实现了最优性能。在域外数据上(Switchboard和CALLHOME数据集),SIWE模型的均方根误差和皮尔逊相关系数相较于基线估计器分别相对提升了17.58%和18.21%。当训练集的WER与评估数据集的WER接近时,性能进一步提升。