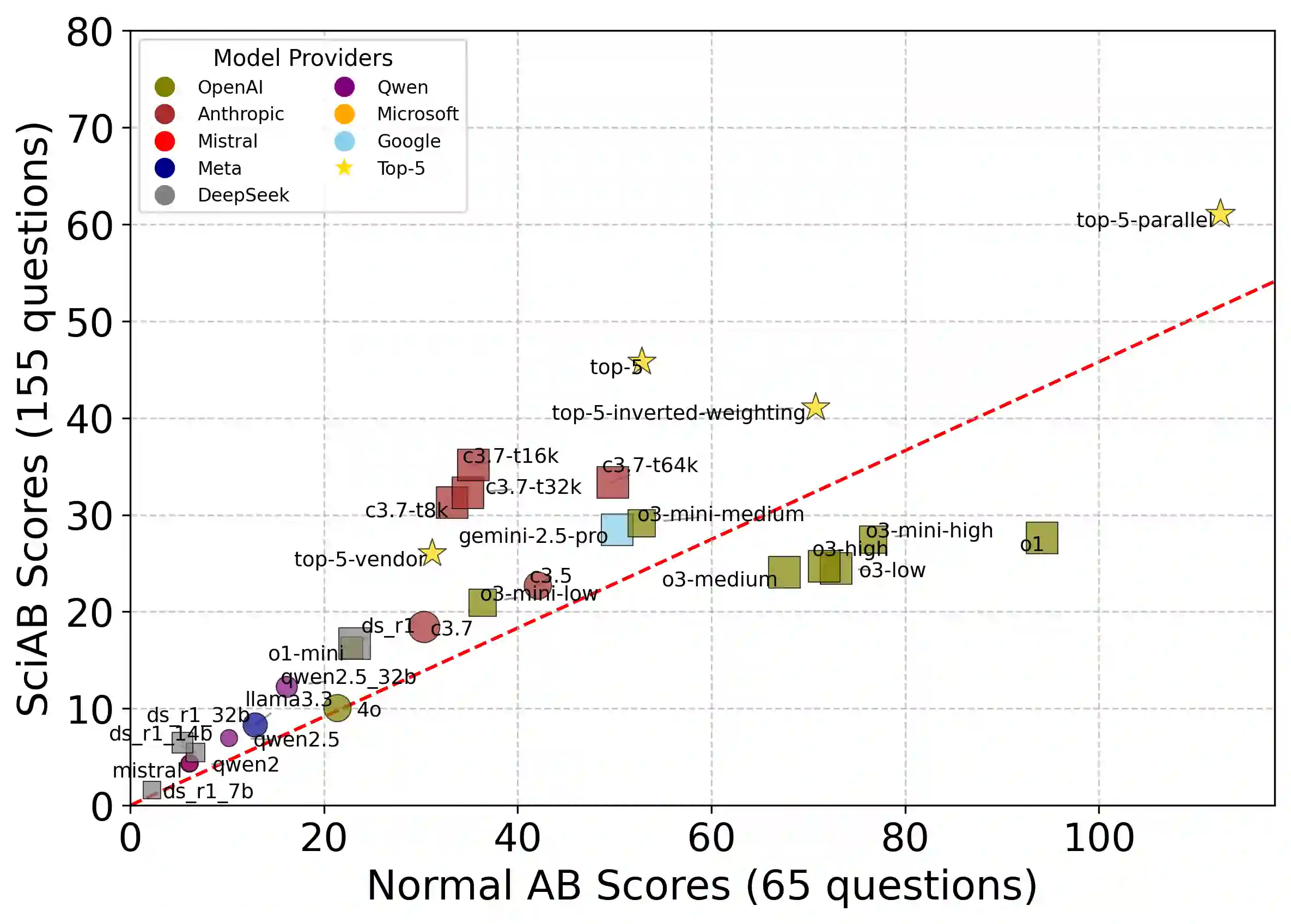
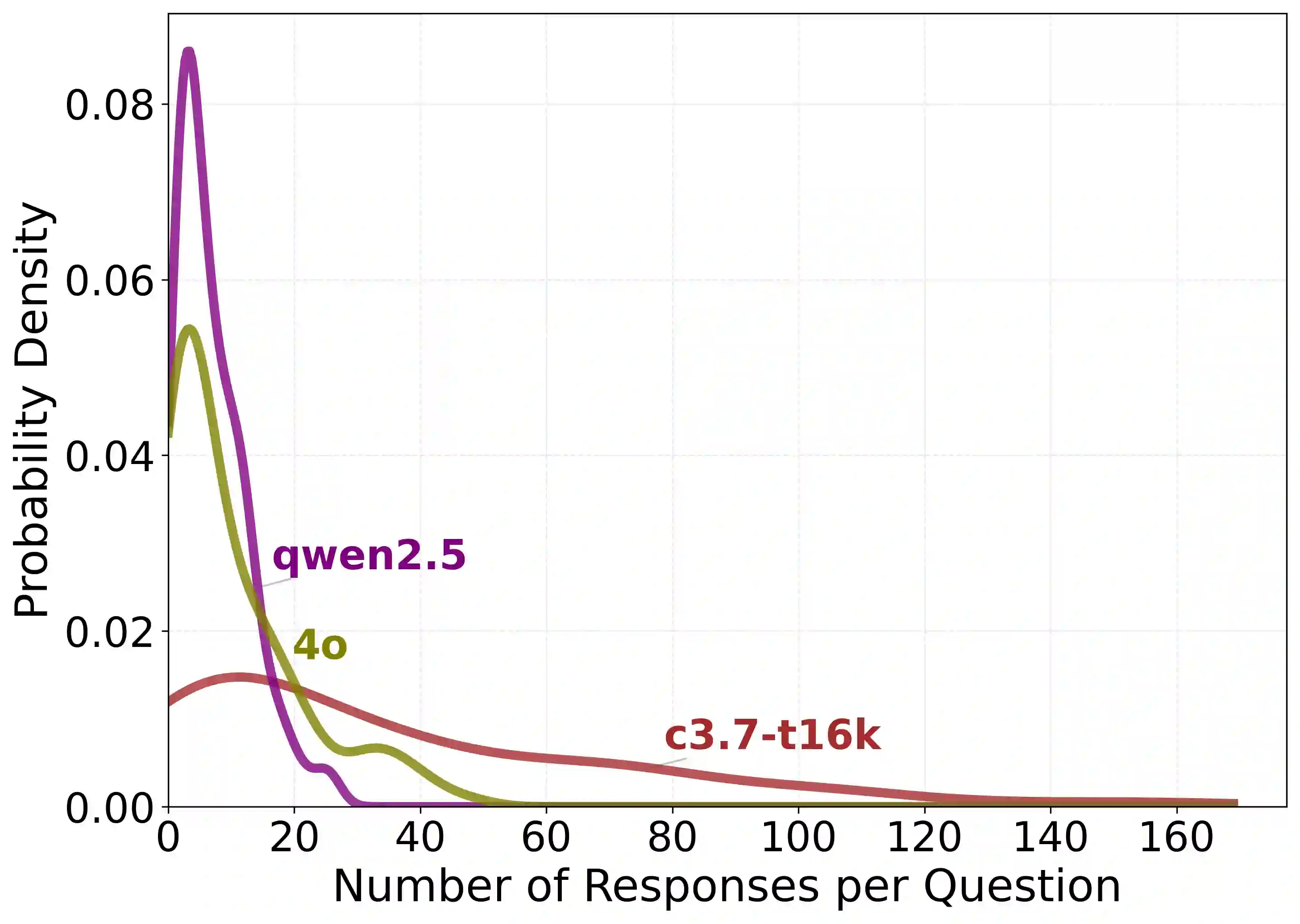
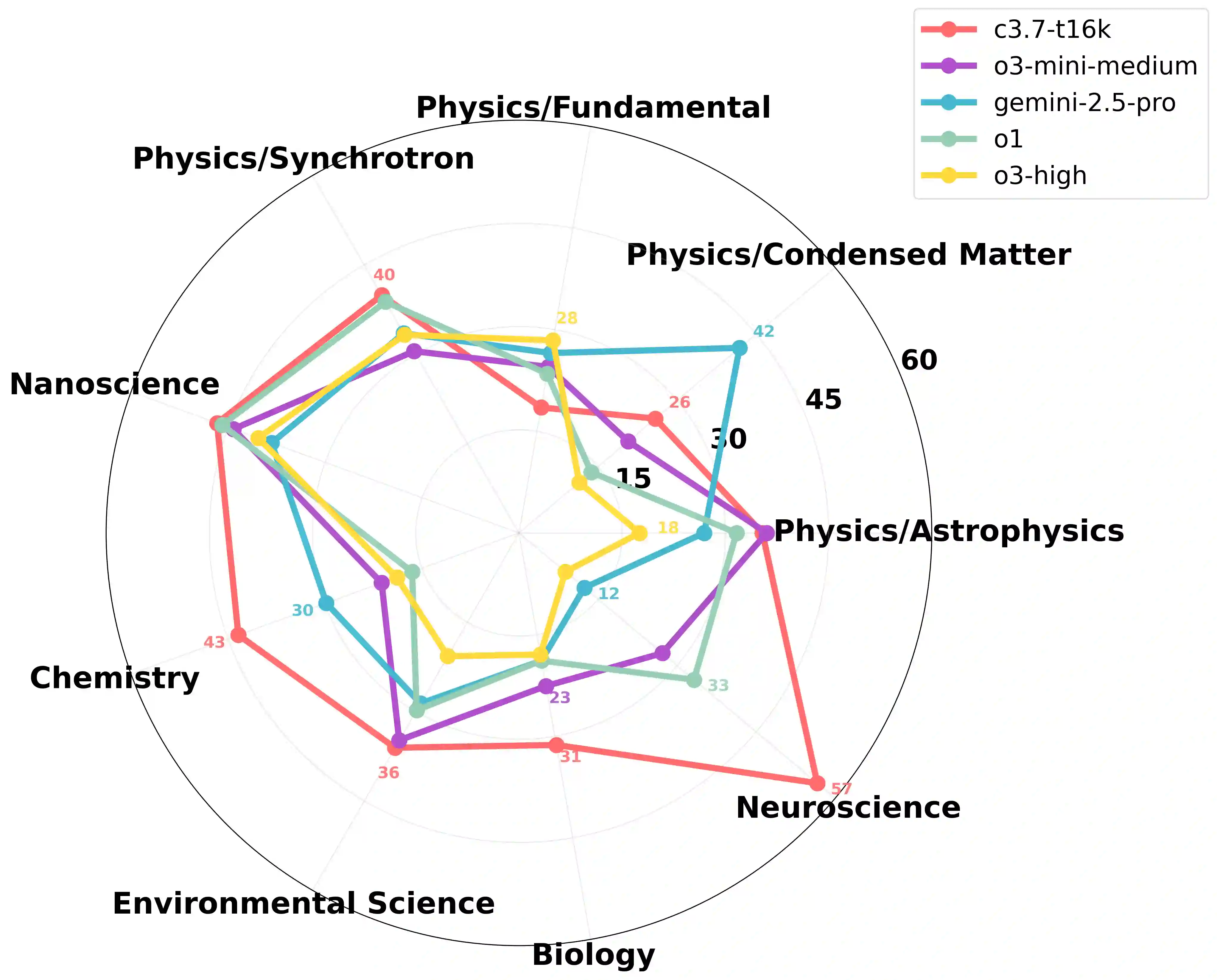
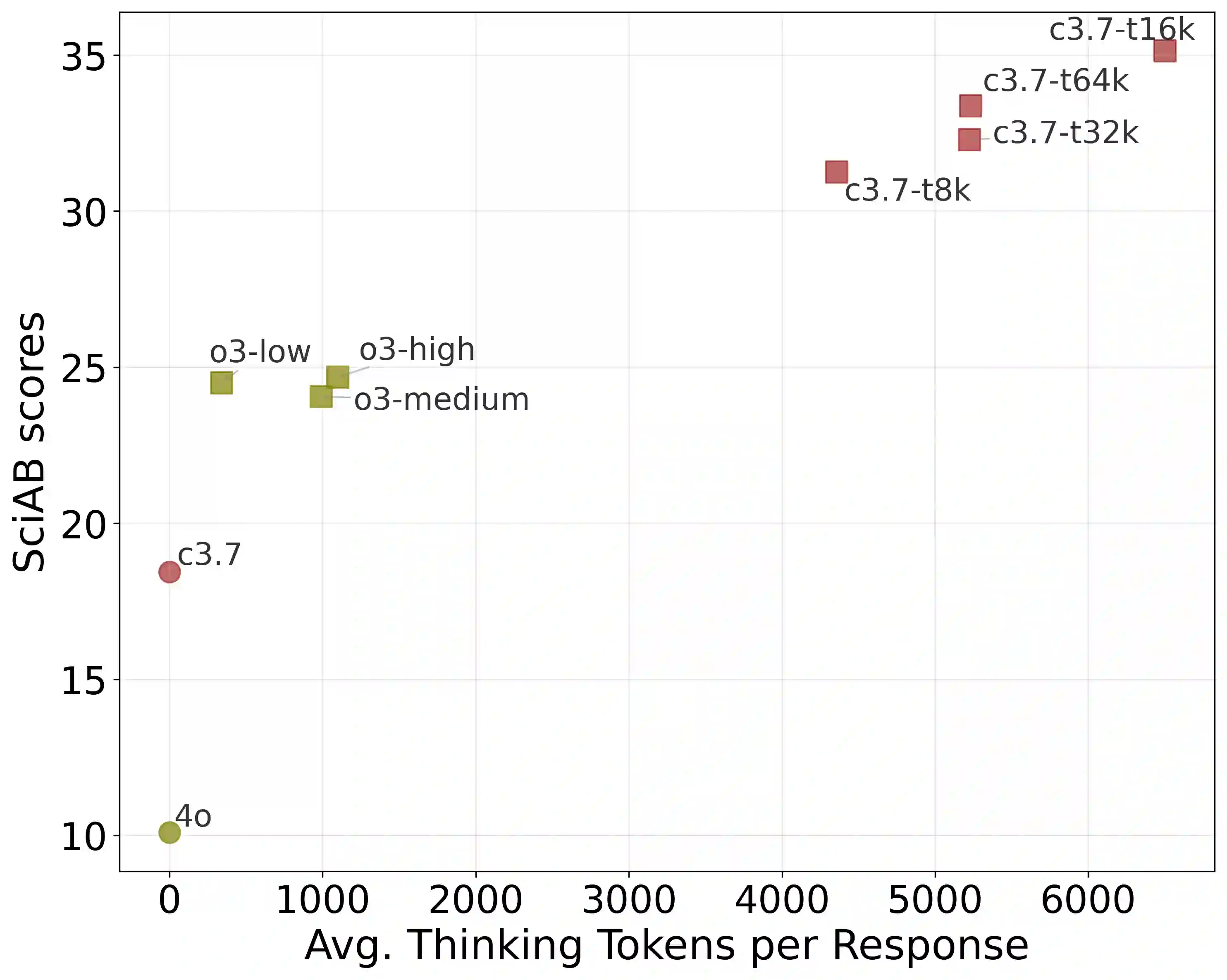
As artificial intelligence advances, models are not improving uniformly. Instead, progress unfolds in a jagged fashion, with capabilities growing unevenly across tasks, domains, and model scales. In this work, we examine this dynamic jaggedness through the lens of scientific idea generation. We introduce SciAidanBench, a benchmark of open-ended scientific questions designed to measure the scientific creativity of large language models (LLMs). Given a scientific question, models are asked to generate as many unique and coherent ideas as possible, with the total number of valid responses serving as a proxy for creative potential. Evaluating 19 base models across 8 providers (30 total variants including reasoning versions), we find that jaggedness manifests both across models and within models. First, in a cross-task comparison between general and scientific creativity, improvements in general creativity do not translate uniformly to scientific creativity, revealing divergent capability profiles across models. Second, at the prompt level, stronger models do not improve uniformly; instead, they exhibit high variability, with bursts of creativity on some questions and limited performance on others. Third, at the domain level, individual models display uneven strengths across scientific subfields, reflecting fragmented internal capability profiles. Finally, we show that this jaggedness can be harnessed. We explore mechanisms of inference-time compute, knowledge pooling, and brainstorming to combine models effectively and construct meta-model ensembles that outperform any single model. Our results position jaggedness not as a limitation, but as a resource, a structural feature of AI progress that, when understood and leveraged, can amplify LLM-driven scientific creativity.
翻译:随着人工智能的进步,模型并非均匀提升。相反,其进展呈现出锯齿状特征,不同任务、领域和模型规模下的能力增长参差不齐。本研究通过科学创意生成的视角审视这种动态锯齿性。我们推出了SciAidanBench,一个开放式科学问题基准,旨在衡量大语言模型(LLM)的科学创造力。给定一个科学问题,模型需生成尽可能多且独立连贯的创意,以有效响应总数作为创造性潜力的代理指标。通过评估来自8个提供商的19个基础模型(含推理版本共30个变体),我们发现锯齿性既存在于模型间也存在于模型内部。首先,在通用创造力与科学创造力的跨任务比较中,通用创造力的提升并未均匀转化为科学创造力,揭示了不同模型间能力轮廓的差异性。其次,在提示层面,更强的模型并非均匀提升;相反,它们表现出高度变异性,在部分问题上创意迸发,而其他问题上表现受限。第三,在领域层面,单个模型在科学子领域展现出不均衡的优势,反映出碎片化的内部能力轮廓。最后,我们证明这种锯齿性可以被利用。我们探索了推理时计算、知识池化与头脑风暴等机制,通过有效组合模型构建出优于任何单一模型的元模型集成。我们的研究结果将锯齿性定位为一种资源而非限制——它是AI进展的结构性特征,一旦被理解并加以利用,即可增强LLM驱动的科学创造力。