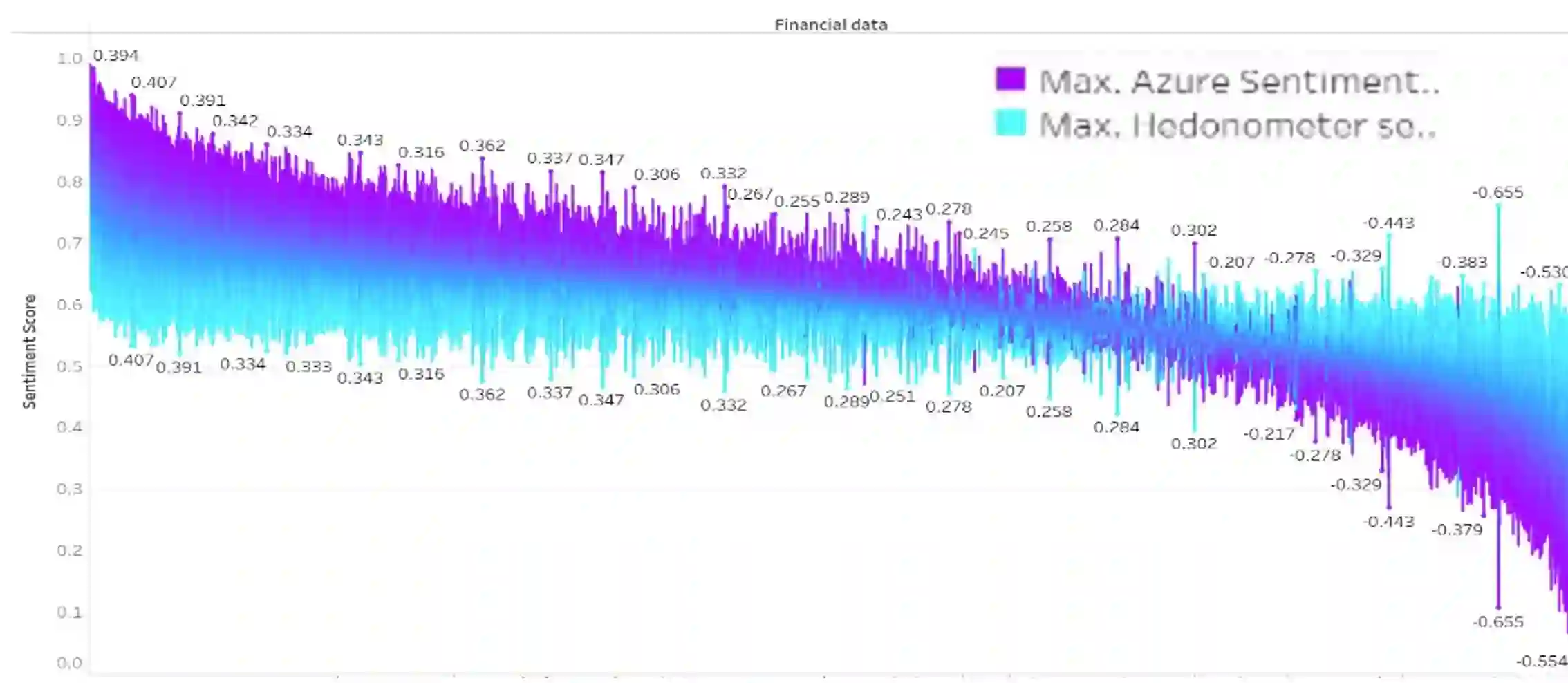
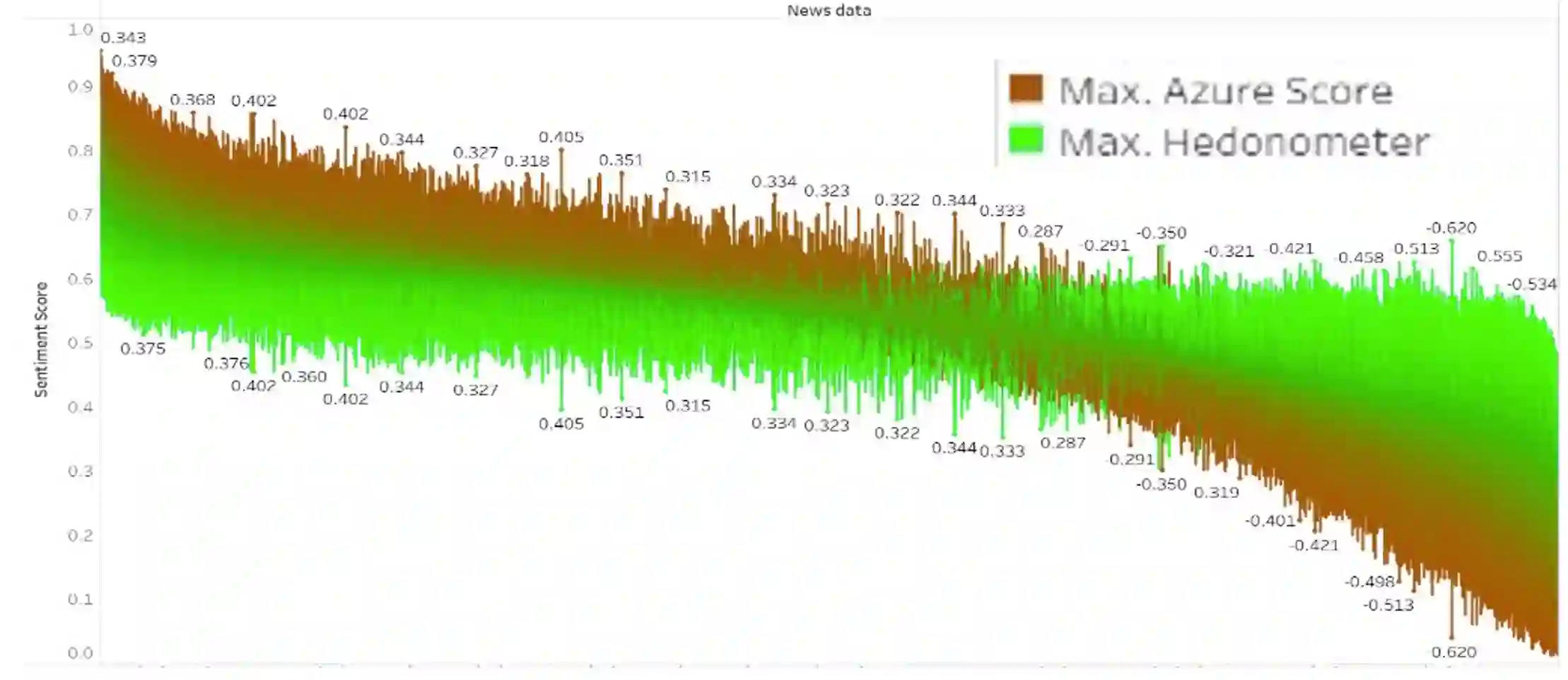
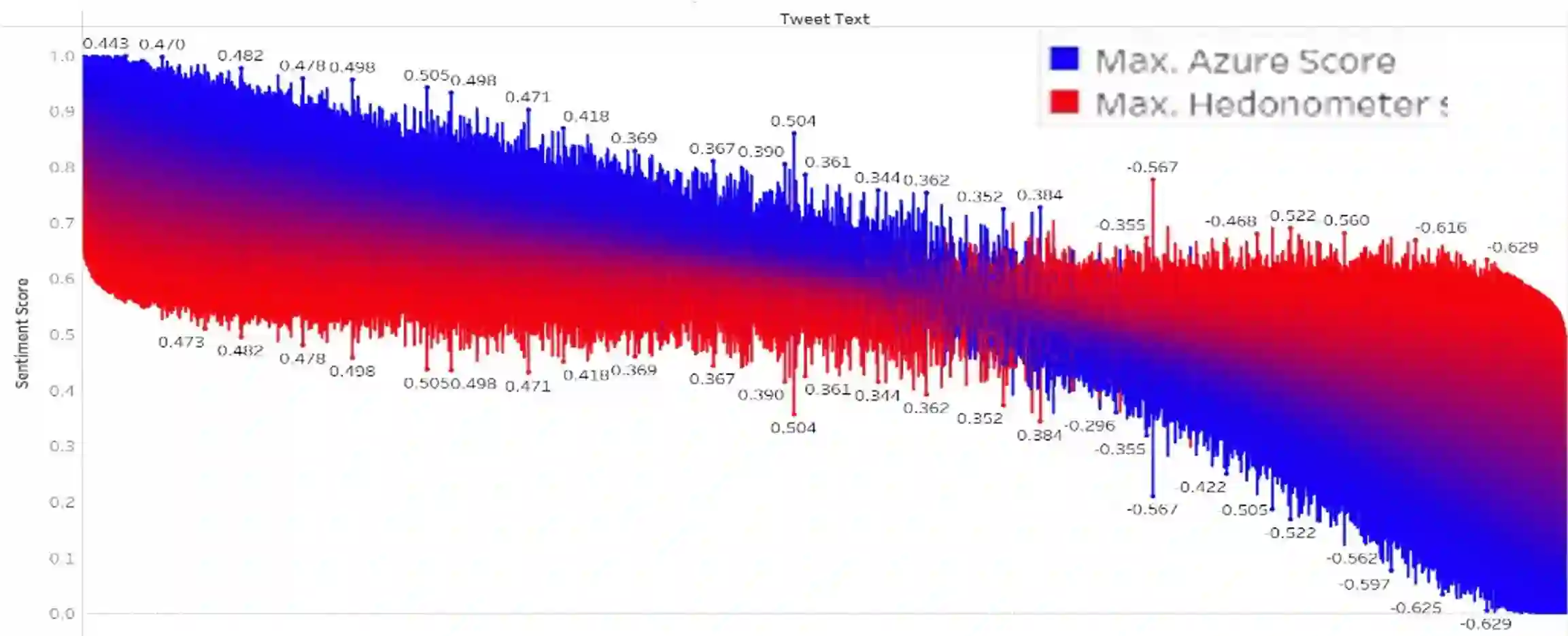
Lexicon-based approaches to sentiment analysis of text are based on each word or lexical entry having a pre-defined weight indicating its sentiment polarity. These are usually manually assigned but the accuracy of these when compared against machine leaning based approaches to computing sentiment, are not known. It may be that there are lexical entries whose sentiment values cause a lexicon-based approach to give results which are very different to a machine learning approach. In this paper we compute sentiment for more than 150,000 English language texts drawn from 4 domains using the Hedonometer, a lexicon-based technique and Azure, a contemporary machine-learning based approach which is part of the Azure Cognitive Services family of APIs which is easy to use. We model differences in sentiment scores between approaches for documents in each domain using a regression and analyse the independent variables (Hedonometer lexical entries) as indicators of each word's importance and contribution to the score differences. Our findings are that the importance of a word depends on the domain and there are no standout lexical entries which systematically cause differences in sentiment scores.
翻译:基于词典的文本情感分析方法依赖于每个单词或词汇条目具有预定义的权重,该权重表示其情感极性。这些权重通常是人工分配的,但与基于机器学习的情感计算方法相比,其准确性尚不可知。可能存在某些词汇条目的情感值导致基于词典的方法得到与机器学习方法截然不同的结果。本文使用Hedonometer(一种基于词典的技术)和Azure(一种现代基于机器学习的方法,属于易于使用的Azure认知服务API系列),对来自4个领域的超过15万篇英文文本进行了情感计算。我们通过回归模型对每个领域内文档在两种方法之间的情感得分差异进行建模,并将独立变量(Hedonometer词汇条目)作为每个单词重要性和对得分差异贡献的指标进行分析。研究结果表明,单词的重要性取决于具体领域,且不存在系统性地导致情感得分差异的突出词汇条目。