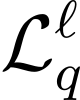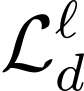Automatic Speech Recognition (ASR) systems, despite large multilingual training, struggle in out-of-domain and low-resource scenarios where labeled data is scarce. We propose BEARD (BEST-RQ Encoder Adaptation with Re-training and Distillation), a novel framework designed to adapt Whisper's encoder using unlabeled data. Unlike traditional self-supervised learning methods, BEARD uniquely combines a BEST-RQ objective with knowledge distillation from a frozen teacher encoder, ensuring the encoder's complementarity with the pre-trained decoder. Our experiments focus on the ATCO2 corpus from the challenging Air Traffic Control (ATC) communications domain, characterized by non-native speech, noise, and specialized phraseology. Using about 5,000 hours of untranscribed speech for BEARD and 2 hours of transcribed speech for fine-tuning, the proposed approach significantly outperforms previous baseline and fine-tuned model, achieving a relative improvement of 12% compared to the fine-tuned model. To the best of our knowledge, this is the first work to use a self-supervised learning objective for domain adaptation of Whisper.
翻译:尽管经过大规模多语言训练,自动语音识别(ASR)系统在标注数据稀缺的领域外和低资源场景中仍面临挑战。我们提出了BEARD(基于BEST-RQ的编码器自适应与重训练及蒸馏),这是一种利用未标注数据对Whisper编码器进行自适应的新型框架。与传统自监督学习方法不同,BEARD创新性地将BEST-RQ目标与冻结教师编码器的知识蒸馏相结合,确保编码器与预训练解码器的互补性。我们的实验聚焦于具有挑战性的空中交通管制(ATC)通信领域——ATCO2语料库,其特点包括非母语语音、噪声及专业术语。使用约5,000小时的未转录语音进行BEARD训练,并结合2小时的转录语音进行微调,该方法显著超越了先前的基线模型和微调模型,相比微调模型实现了12%的相对性能提升。据我们所知,这是首次采用自监督学习目标实现Whisper领域自适应的工作。