
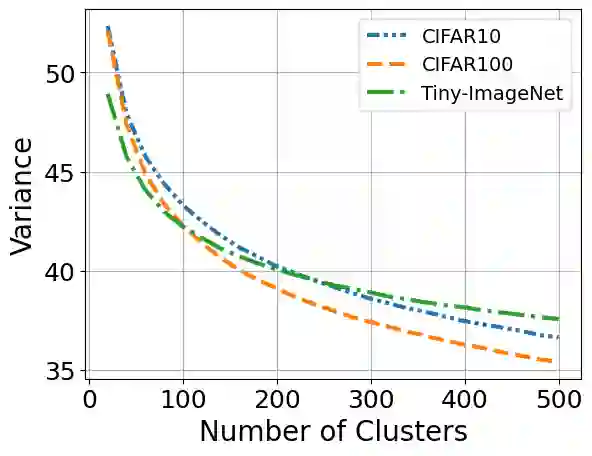
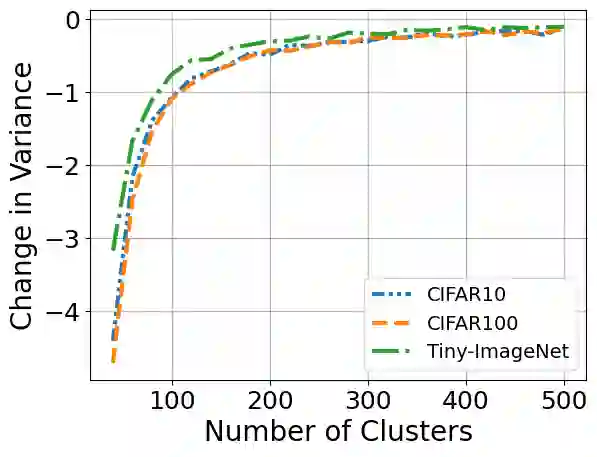
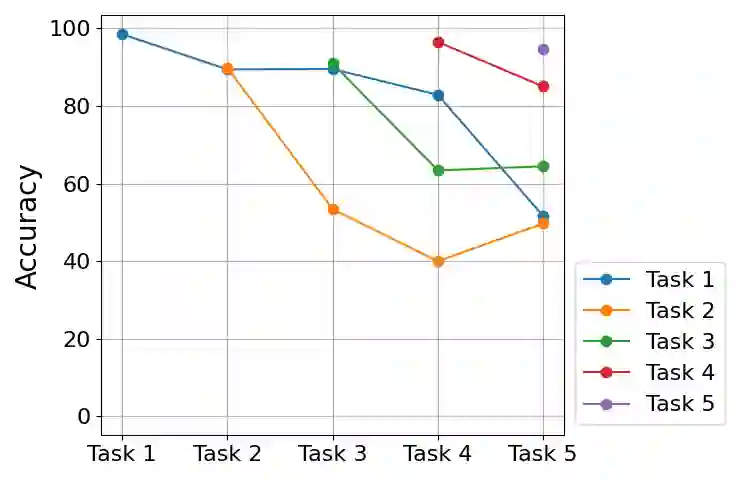
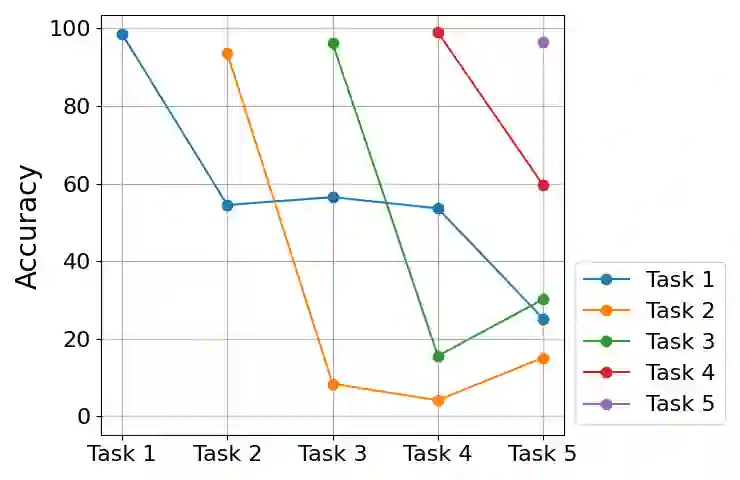
Continual learning seeks to enable deep learners to train on a series of tasks of unknown length without suffering from the catastrophic forgetting of previous tasks. One effective solution is replay, which involves storing few previous experiences in memory and replaying them when learning the current task. However, there is still room for improvement when it comes to selecting the most informative samples for storage and determining the optimal number of samples to be stored. This study aims to address these issues with a novel comparison of the commonly used reservoir sampling to various alternative population strategies and providing a novel detailed analysis of how to find the optimal number of stored samples.
翻译:持续学习旨在使深度学习者能够在未知长度的任务序列上进行训练,同时避免对先前任务产生灾难性遗忘。一种有效的解决方案是回放,即在内存中存储少量先前经验,并在学习当前任务时重放它们。然而,在如何选择最具信息量的样本进行存储以及确定最优存储样本数量方面仍有改进空间。本研究旨在通过将常用的蓄水池采样与多种替代的种群策略进行新颖对比,并针对如何找到最优存储样本数量提供详细创新分析,从而解决这些问题。
相关内容

Source: Apple - iOS 8


