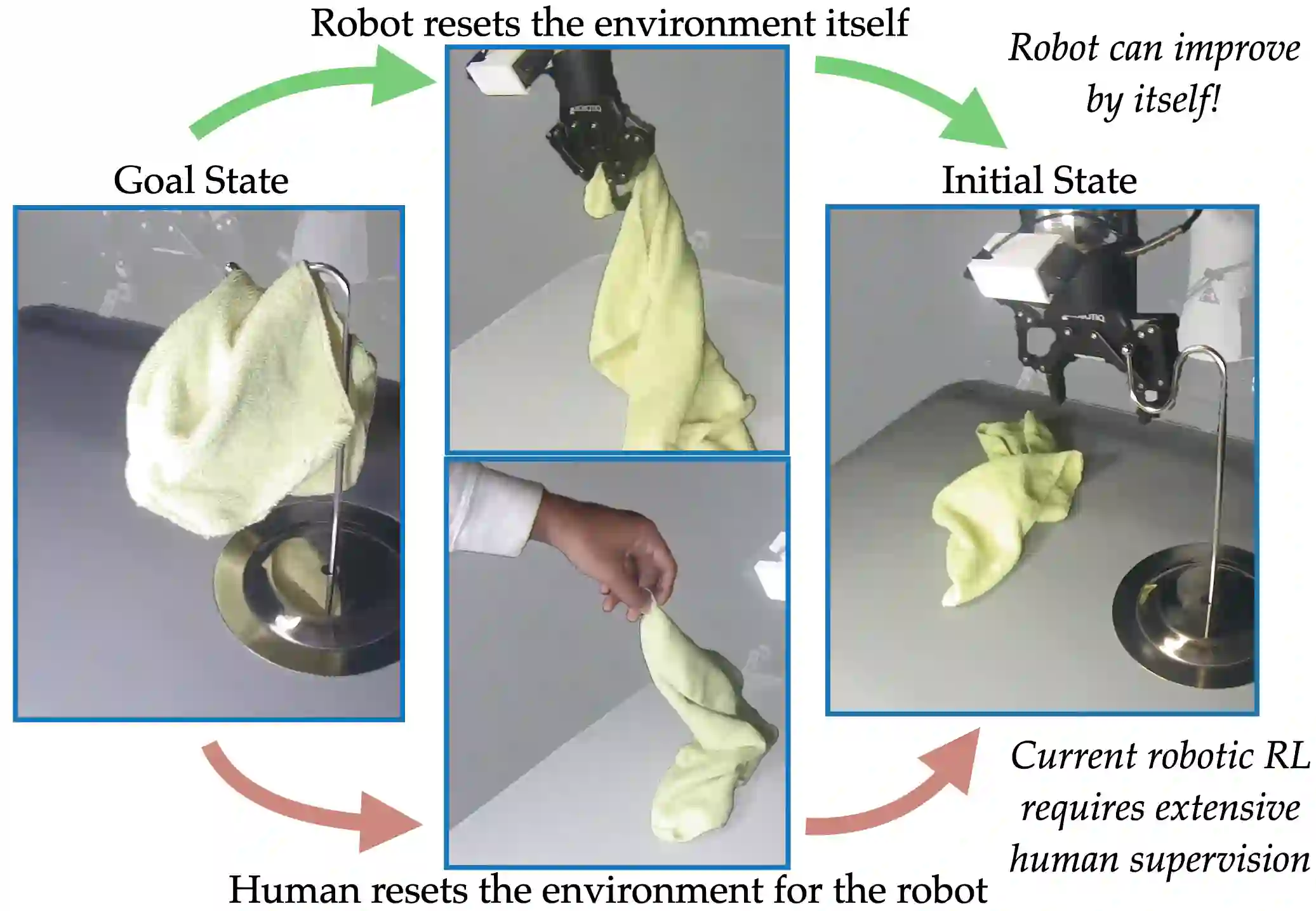
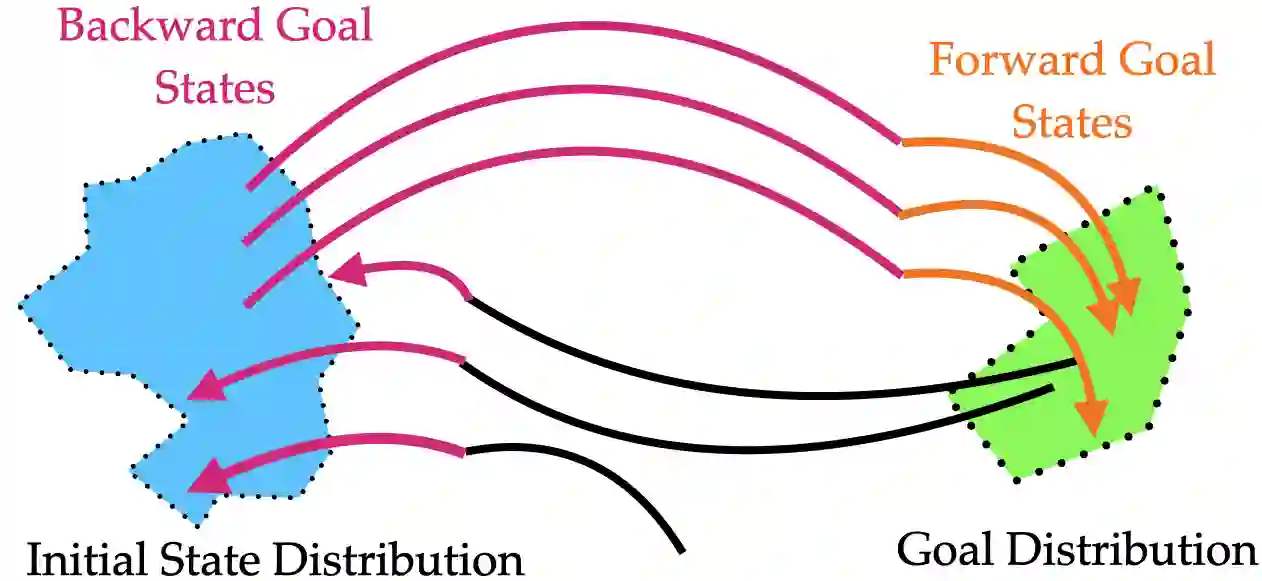
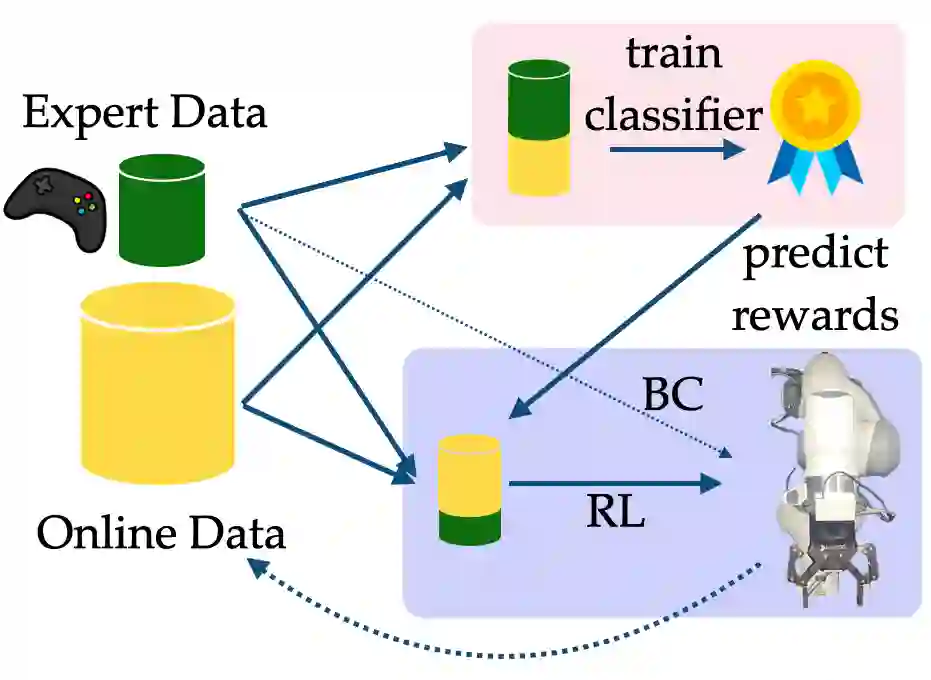
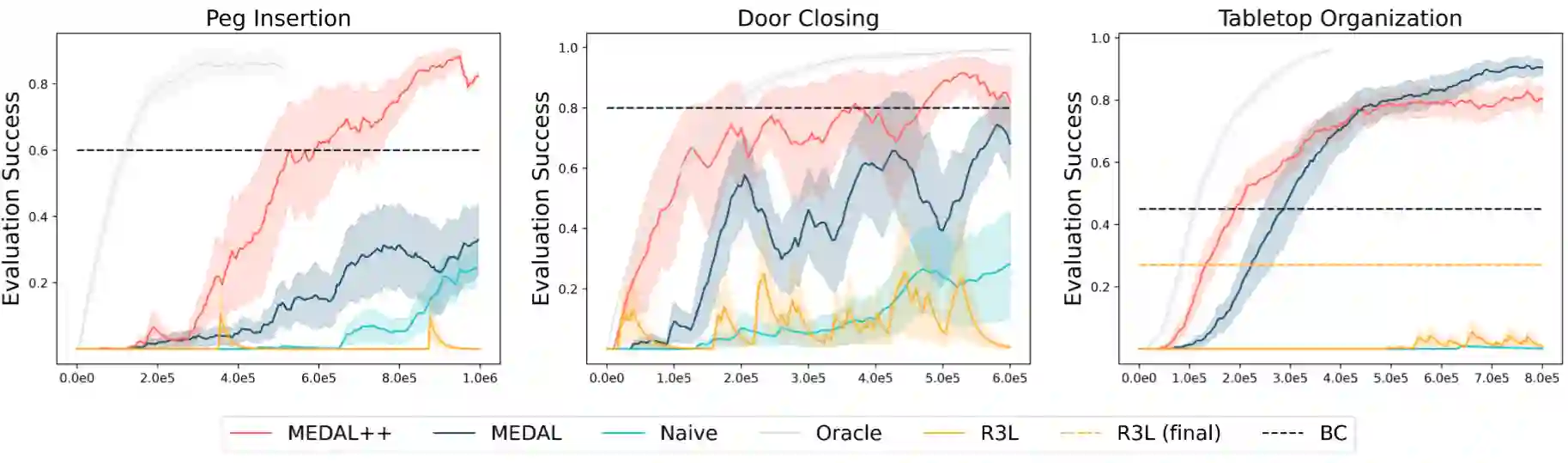
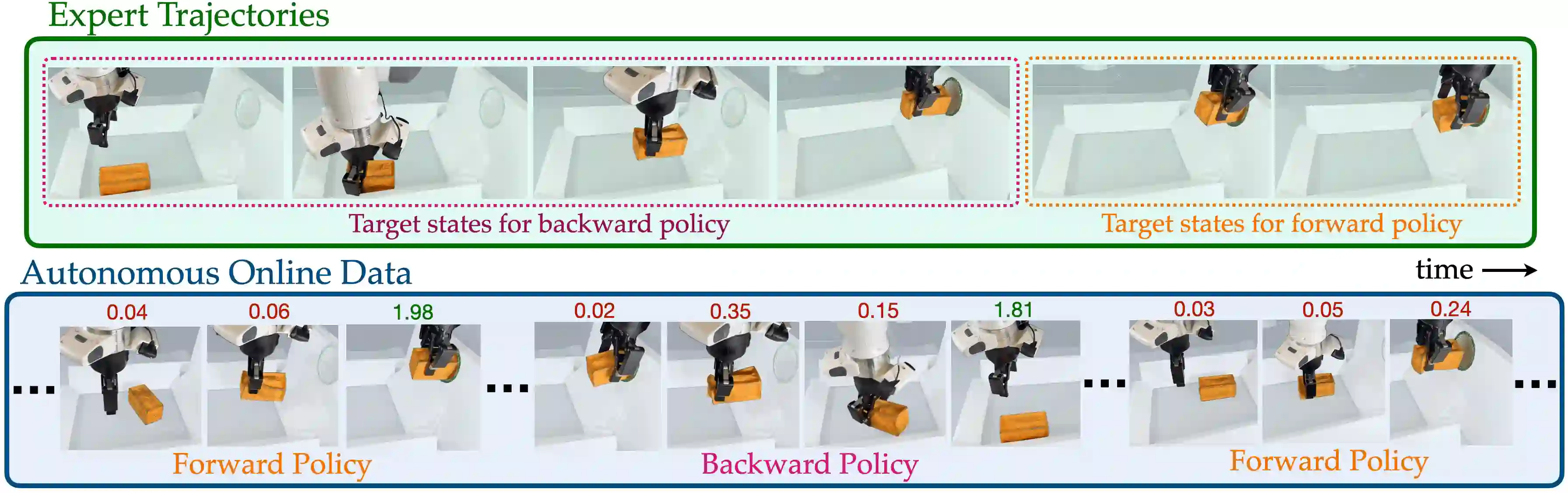
In imitation and reinforcement learning, the cost of human supervision limits the amount of data that robots can be trained on. An aspirational goal is to construct self-improving robots: robots that can learn and improve on their own, from autonomous interaction with minimal human supervision or oversight. Such robots could collect and train on much larger datasets, and thus learn more robust and performant policies. While reinforcement learning offers a framework for such autonomous learning via trial-and-error, practical realizations end up requiring extensive human supervision for reward function design and repeated resetting of the environment between episodes of interactions. In this work, we propose MEDAL++, a novel design for self-improving robotic systems: given a small set of expert demonstrations at the start, the robot autonomously practices the task by learning to both do and undo the task, simultaneously inferring the reward function from the demonstrations. The policy and reward function are learned end-to-end from high-dimensional visual inputs, bypassing the need for explicit state estimation or task-specific pre-training for visual encoders used in prior work. We first evaluate our proposed algorithm on a simulated non-episodic benchmark EARL, finding that MEDAL++ is both more data efficient and gets up to 30% better final performance compared to state-of-the-art vision-based methods. Our real-robot experiments show that MEDAL++ can be applied to manipulation problems in larger environments than those considered in prior work, and autonomous self-improvement can improve the success rate by 30-70% over behavior cloning on just the expert data. Code, training and evaluation videos along with a brief overview is available at: https://architsharma97.github.io/self-improving-robots/
翻译:在模仿学习和强化学习中,人类监督的成本限制了机器人可训练的数据量。一个具有抱负的目标是构建自我改进机器人:这类机器人能够通过自主交互,在极少量人类监督或干预下自行学习与提升。此类机器人能收集并训练更大规模数据集,从而习得更鲁棒且高性能的策略。尽管强化学习通过试错机制为这种自主学习提供了框架,但实际实现中仍需大量人类监督:设计奖励函数,以及在交互回合间反复重置环境。本研究提出MEDAL++,一种面向自我改进机器人的新型设计:给定初始少量专家演示后,机器人通过同时学习执行任务与撤销任务来自主练习,并从演示中推断奖励函数。策略与奖励函数从高维视觉输入中端到端学习,无需显式状态估计或先前文献中视觉编码器的特定任务预训练。我们首先在模拟非回合制基准EARL上评估算法,发现MEDAL++相比最先进的基于视觉的方法,数据效率更高且最终性能提升达30%。真实机器人实验表明,MEDAL++可应用于比先前工作更大规模环境中的操控问题,且自主改进使成功率相比仅使用专家数据的模仿学习提升30-70%。代码、训练与评估视频及简要概述见:https://architsharma97.github.io/self-improving-robots/