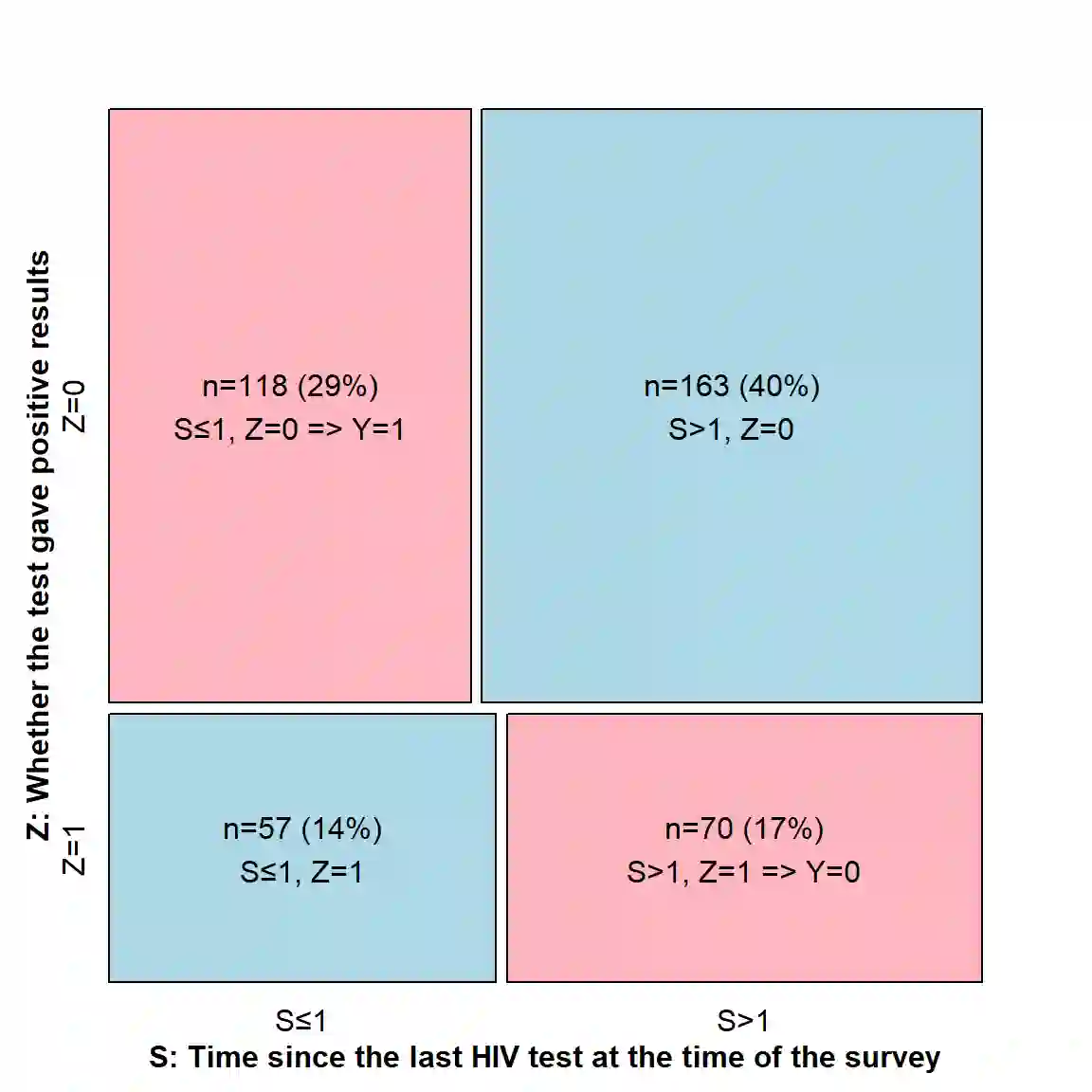
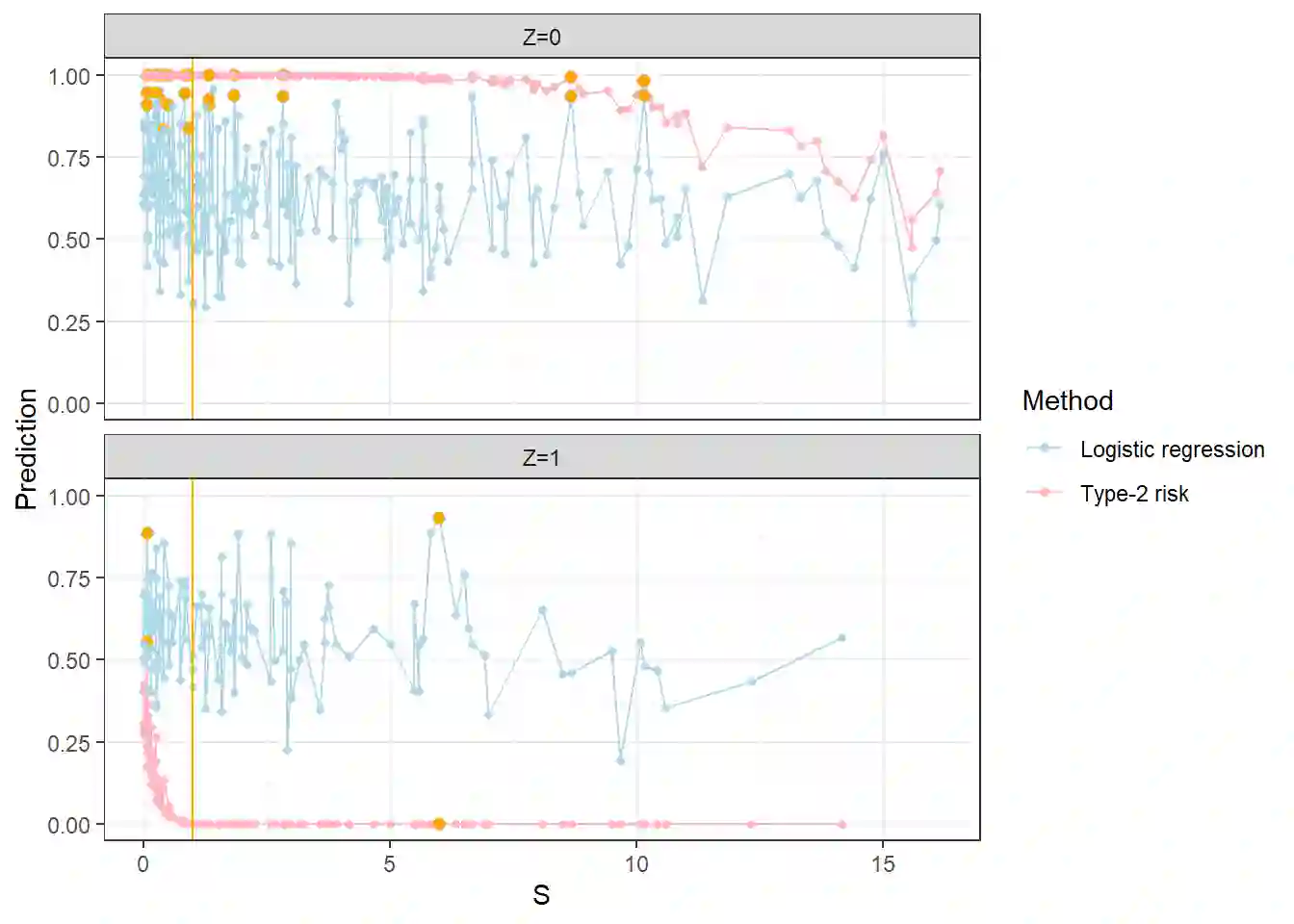
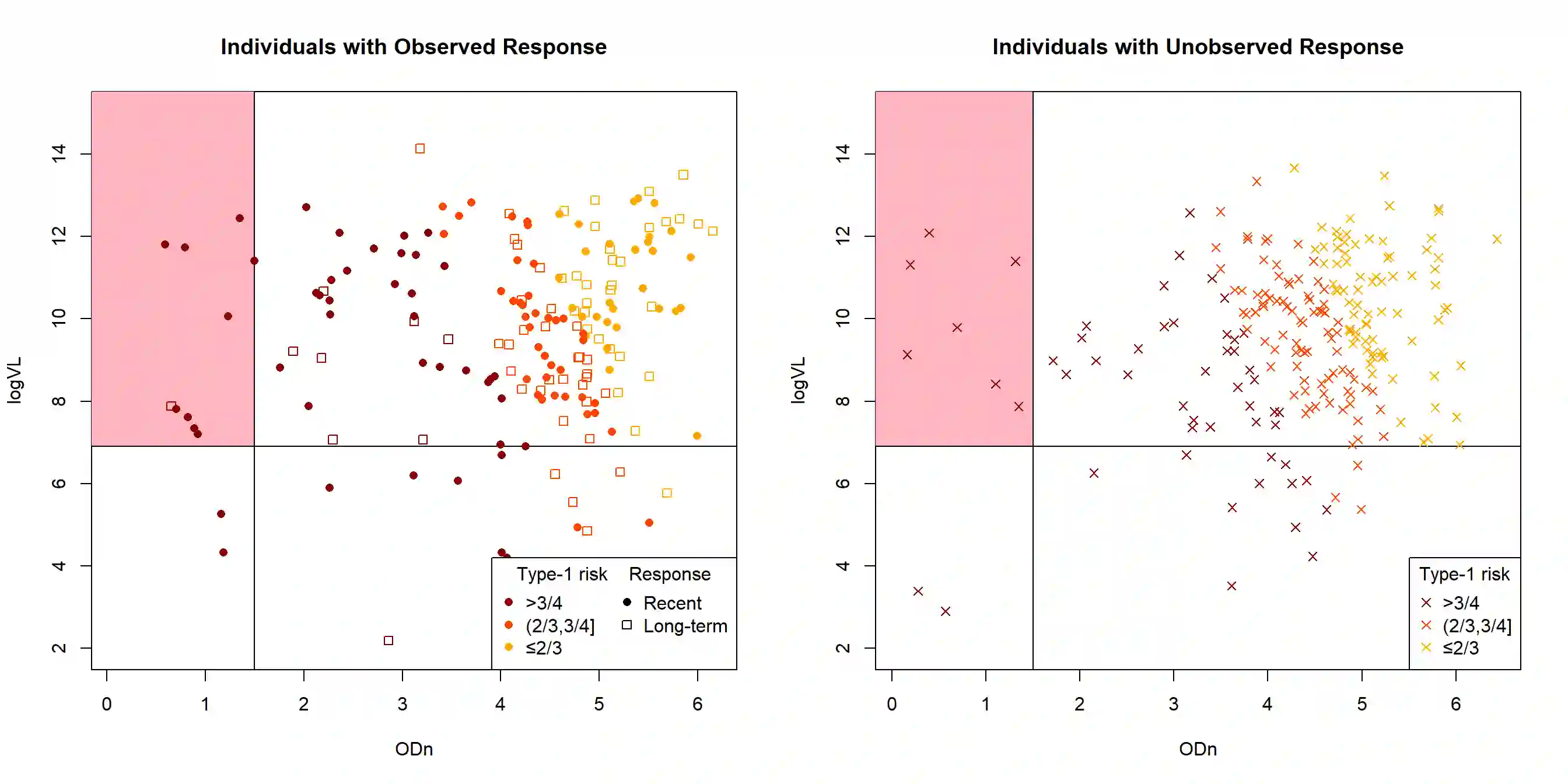
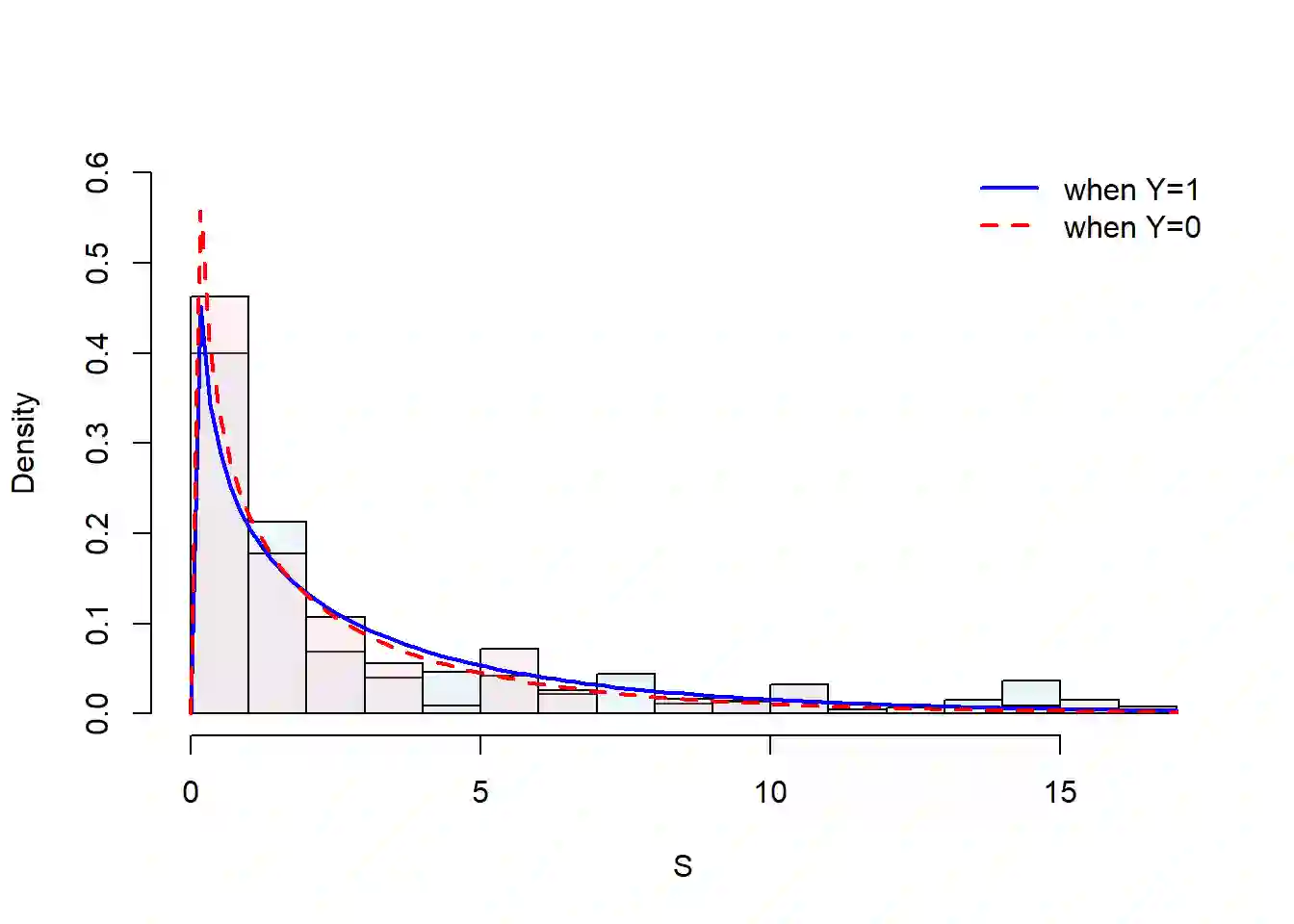
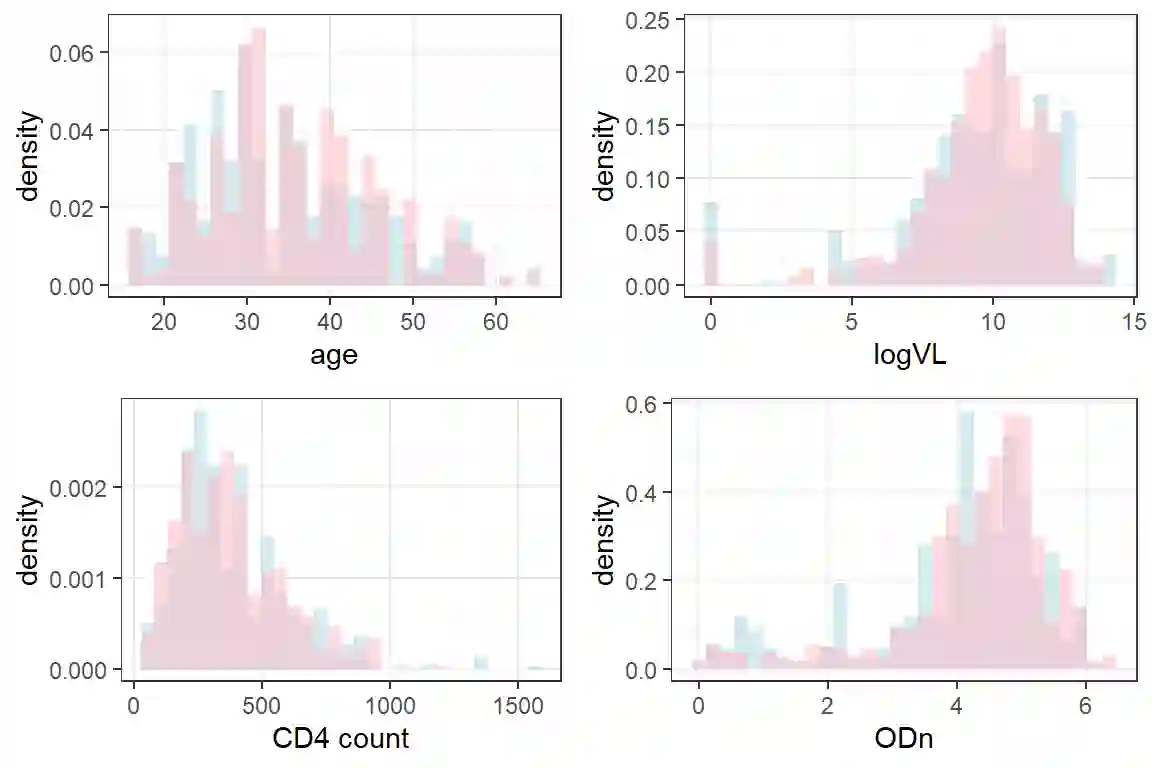
Estimating new HIV infections is significant yet challenging due to the difficulty in distinguishing between recent and long-term infections. We demonstrate that HIV recency status (recent v.s. long-term) could be determined from the combination of self-report testing history and biomarkers, which are increasingly available in bio-behavioral surveys. HIV recency status is partially observed, given the self-report testing history. For example, people who tested positive for HIV over one year ago should have a long-term infection. Based on the nationally representative samples collected by the Population-based HIV Impact Assessment (PHIA) Project, we propose a likelihood-based probabilistic model for HIV recency classification. The model incorporates both labeled and unlabeled data and integrates the mechanism of how HIV recency status depends on biomarkers and the mechanism of how HIV recency status, together with the self-report time of the most recent HIV test, impacts the test results, via a set of logistic regression models. We compare our method to logistic regression and the binary classification tree (current practice) on Malawi, Zimbabwe, and Zambia PHIA data, as well as on simulated data. Our model obtains more efficient and less biased parameter estimates and is relatively robust to potential reporting error and model misspecification.
翻译:估计新发HIV感染数量具有重要意义,但由于难以区分近期感染与长期感染,这一任务充满挑战。我们证明,结合自我报告检测史和生物标志物(其在生物行为调查中的可获取性日益增加)可判断HIV感染的新近状态(近期vs长期)。鉴于自我报告检测史,HIV感染新近状态仅部分可观测。例如,一年前即检测出HIV阳性者应为长期感染。基于人口HIV影响评估项目(PHIA)收集的全国代表性样本,我们提出一种基于似然的概率模型用于HIV新近感染分类。该模型同时纳入标记数据与未标记数据,通过一组逻辑回归模型整合两方面机制:一是HIV新近状态如何依赖于生物标志物,二是HIV新近状态与最近一次HIV检测自我报告时间如何共同影响检测结果。我们将该方法与逻辑回归及二元分类树(当前实践)在马拉维、津巴布韦和赞比亚的PHIA数据以及模拟数据上进行对比。我们的模型能获得更高效且偏倚更小的参数估计,并对潜在报告误差和模型误设具有相对稳健性。