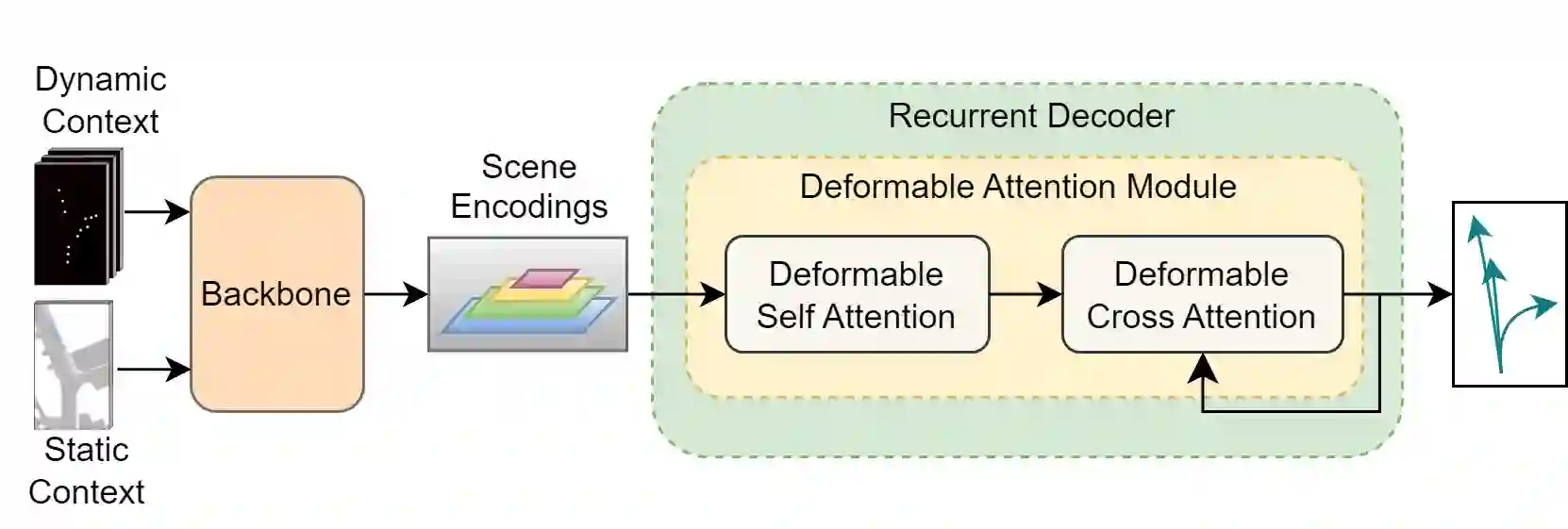
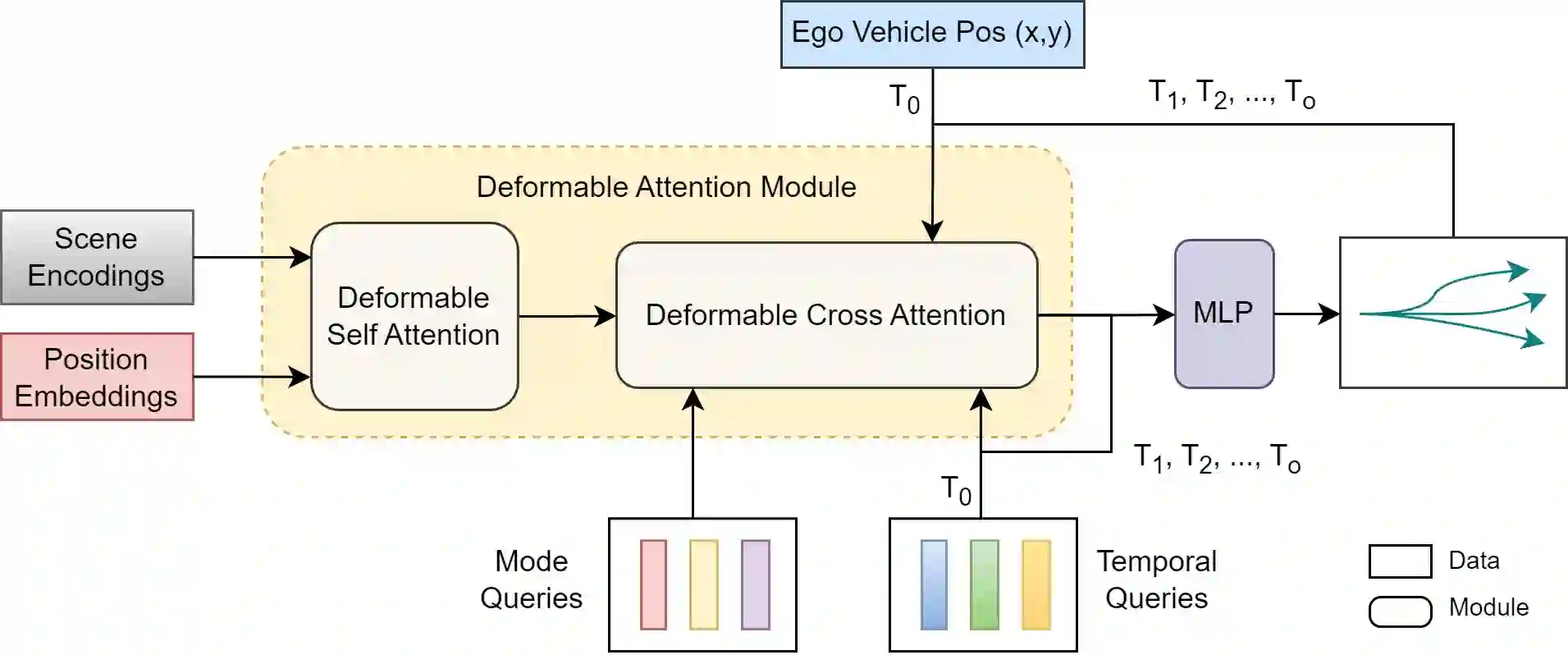
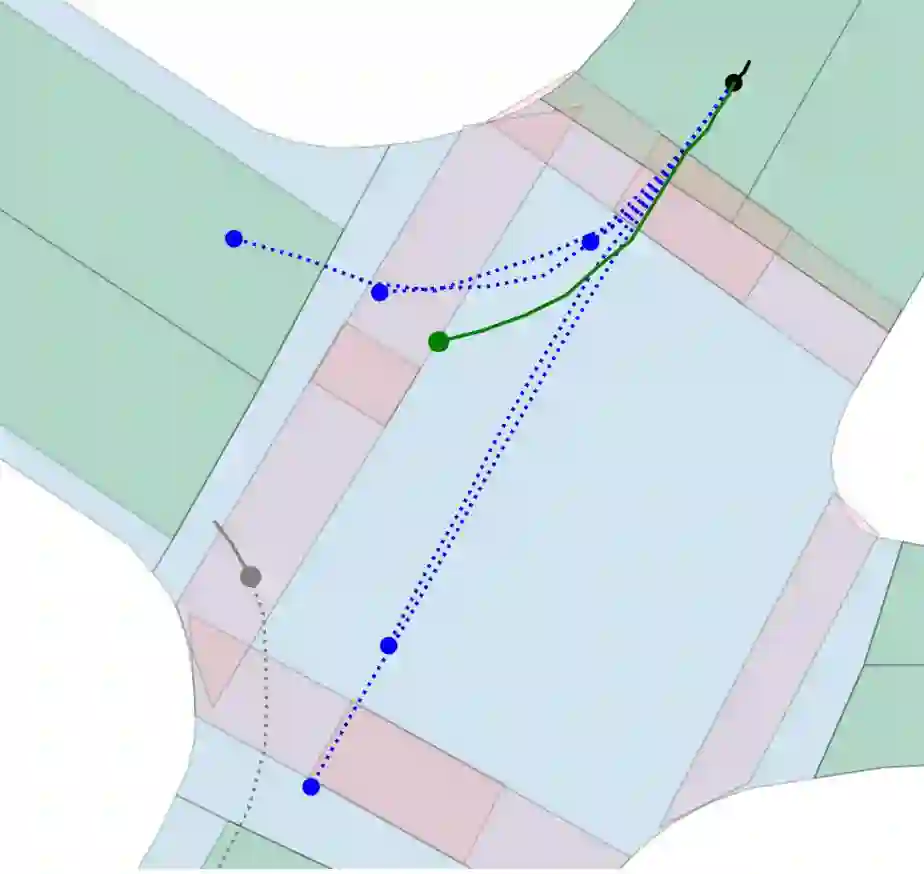
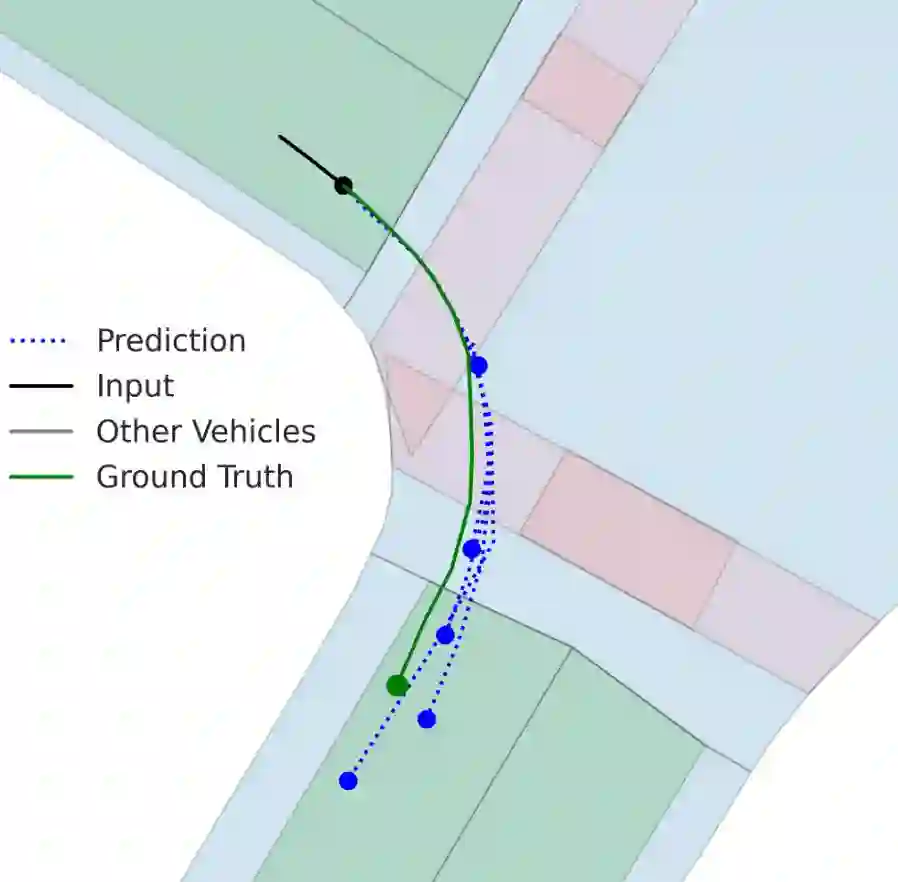
Motion prediction is an important aspect for Autonomous Driving (AD) and Advance Driver Assistance Systems (ADAS). Current state-of-the-art motion prediction methods rely on High Definition (HD) maps for capturing the surrounding context of the ego vehicle. Such systems lack scalability in real-world deployment as HD maps are expensive to produce and update in real-time. To overcome this issue, we propose Context Aware Scene Prediction Transformer (CASPFormer), which can perform multi-modal motion prediction from rasterized Bird-Eye-View (BEV) images. Our system can be integrated with any upstream perception module that is capable of generating BEV images. Moreover, CASPFormer directly decodes vectorized trajectories without any postprocessing. Trajectories are decoded recurrently using deformable attention, as it is computationally efficient and provides the network with the ability to focus its attention on the important spatial locations of the BEV images. In addition, we also address the issue of mode collapse for generating multiple scene-consistent trajectories by incorporating learnable mode queries. We evaluate our model on the nuScenes dataset and show that it reaches state-of-the-art across multiple metrics
翻译:运动预测是自动驾驶(AD)和高级驾驶辅助系统(ADAS)的重要环节。当前最先进的运动预测方法依赖高精(HD)地图来捕捉自车周围环境。此类系统在实际部署中缺乏可扩展性,因为高精地图的实时制作与更新成本高昂。为解决这一问题,我们提出上下文感知场景预测Transformer(CASPFormer),该系统能够基于栅格化鸟瞰(BEV)图像进行多模态运动预测。我们的系统可与任何能够生成BEV图像的上游感知模块集成。此外,CASPFormer无需任何后处理即可直接解码矢量化轨迹。通过采用计算高效的可变形注意力机制对轨迹进行循环解码,使网络能够将注意力聚焦于BEV图像的关键空间位置。同时,我们通过引入可学习的模态查询,解决了生成多个场景一致轨迹时的模态坍塌问题。我们在nuScenes数据集上评估了模型,结果表明其在多项指标上均达到最先进水平。