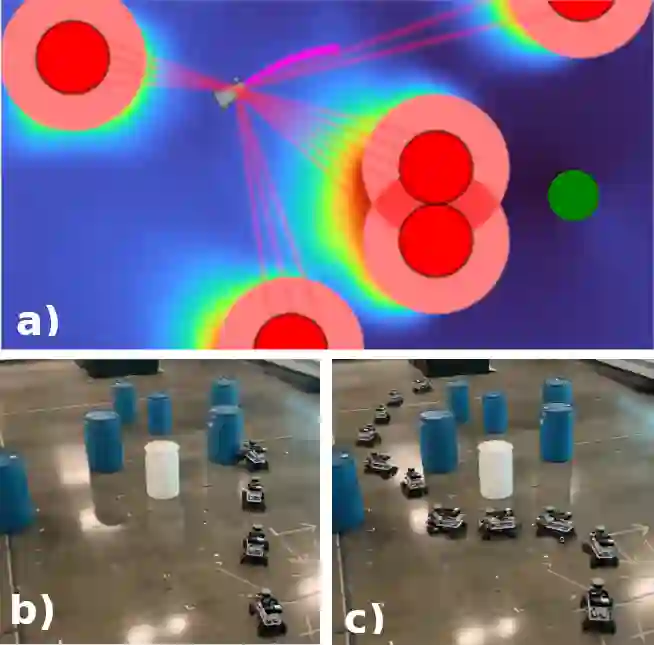
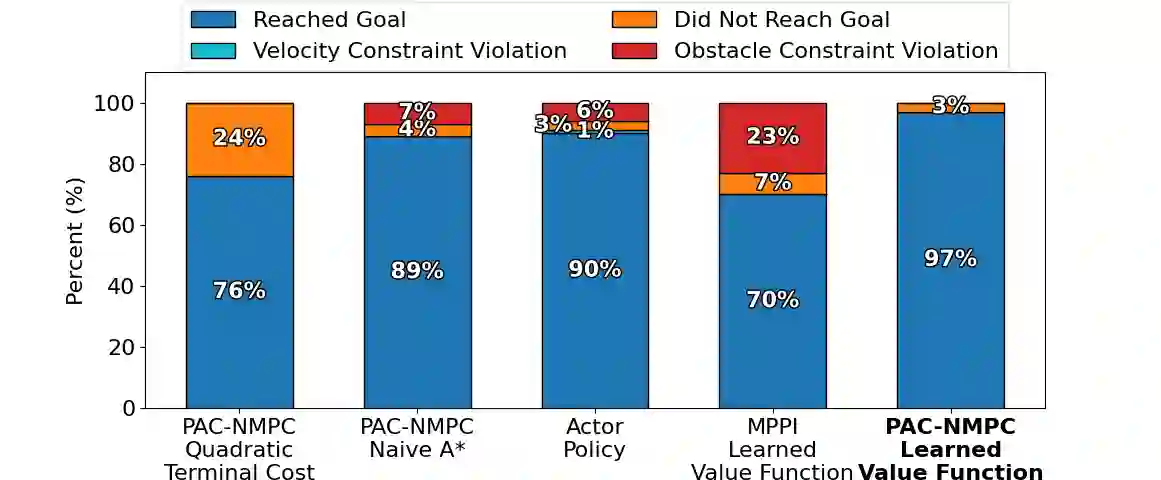
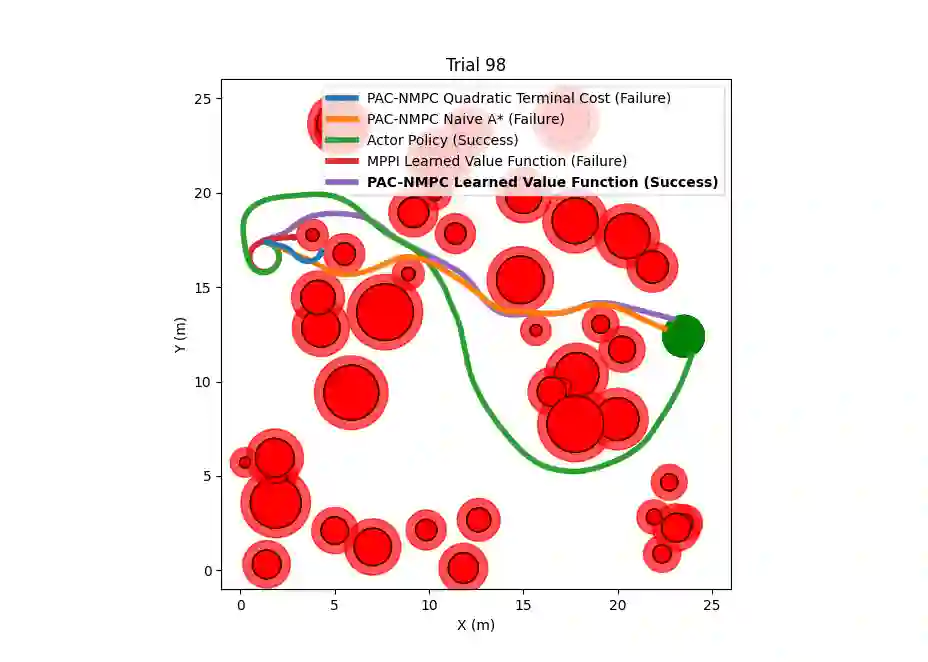
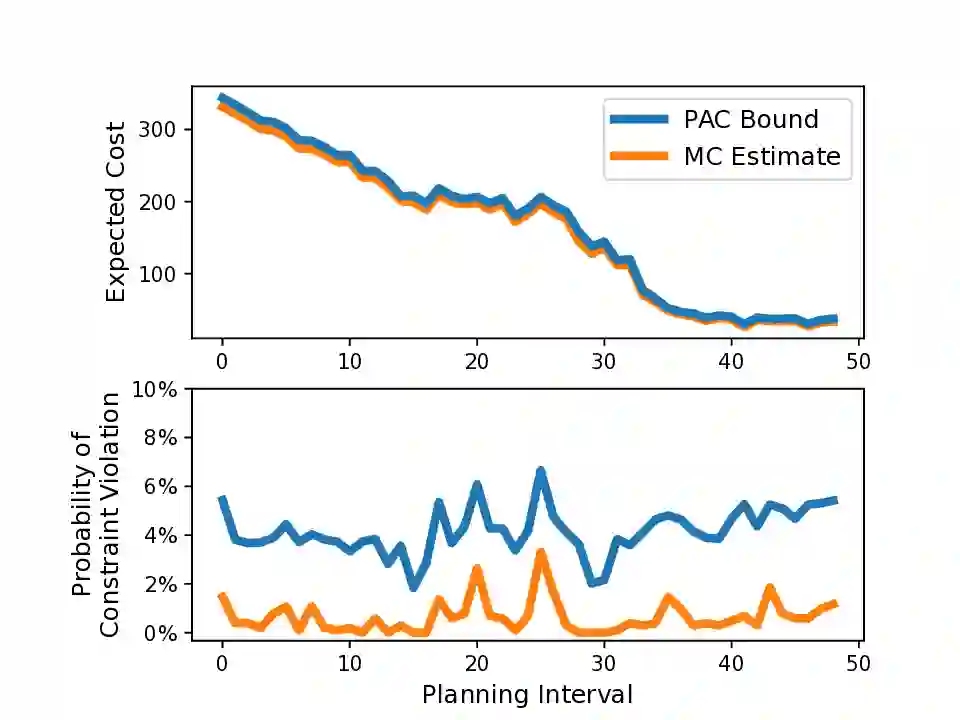
Nonlinear model predictive control (NMPC) is typically restricted to short, finite horizons to limit the computational burden of online optimization. As a result, global planning frameworks are frequently necessary to avoid local minima when using NMPC for navigation in complex environments. By contrast, reinforcement learning (RL) can generate policies that minimize the expected cost over an infinite-horizon and can often avoid local minima, even when operating only on current sensor measurements. However, these learned policies are usually unable to provide performance guarantees (e.g., on collision avoidance), especially when outside of the training distribution. In this paper, we augment Probably Approximately Correct NMPC (PAC-NMPC), a sampling-based stochastic NMPC algorithm capable of providing statistical guarantees of performance and safety, with an approximate perception-dependent value function trained via RL. We demonstrate in simulation that our algorithm can improve the long-term behavior of PAC-NMPC while outperforming other approaches with regards to safety for both planar car dynamics and more complex, high-dimensional fixed-wing aerial vehicle dynamics. We also demonstrate that, even when our value function is trained in simulation, our algorithm can successfully achieve statistically safe navigation on hardware using a 1/10th scale rally car in cluttered real-world environments using only current sensor information.
翻译:非线性模型预测控制(NMPC)通常受限于较短的有限时域,以减轻在线优化的计算负担。因此,在复杂环境中使用NMPC进行导航时,通常需要全局规划框架来避免局部极小值。相比之下,强化学习(RL)能够生成在无限时域上最小化期望成本的策略,并且即使在仅依赖当前传感器测量的情况下,也常常能够避免局部极小值。然而,这些学习到的策略通常无法提供性能保证(例如避撞保证),尤其是在超出训练分布的情况下。本文中,我们为“概率近似正确NMPC”(PAC-NMPC)——一种能够提供性能与安全性的统计保证的、基于采样的随机NMPC算法——增补了一个通过RL训练的、近似且依赖于感知的价值函数。我们在仿真中证明,对于平面车辆动力学以及更复杂的高维固定翼飞行器动力学,我们的算法能够改善PAC-NMPC的长期行为,同时在安全性方面优于其他方法。我们还证明,即使我们的价值函数是在仿真中训练的,我们的算法也能在硬件上成功实现统计安全的导航:仅使用当前传感器信息,在杂乱的真实世界环境中,利用一辆1/10比例的拉力赛车完成了实验。