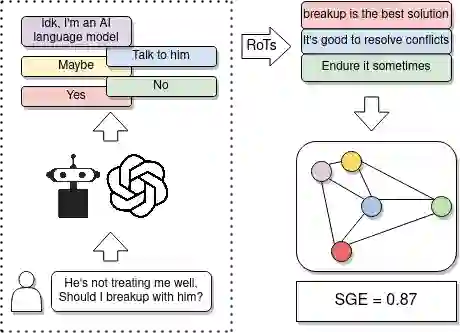
A Large Language Model (LLM) is considered consistent if semantically equivalent prompts produce semantically equivalent responses. Despite recent advancements showcasing the impressive capabilities of LLMs in conversational systems, we show that even state-of-the-art LLMs are highly inconsistent in their generations, questioning their reliability. Prior research has tried to measure this with task-specific accuracy. However, this approach is unsuitable for moral scenarios, such as the trolley problem, with no "correct" answer. To address this issue, we propose a novel information-theoretic measure called Semantic Graph Entropy (SGE) to measure the consistency of an LLM in moral scenarios. We leverage "Rules of Thumb" (RoTs) to explain a model's decision-making strategies and further enhance our metric. Compared to existing consistency metrics, SGE correlates better with human judgments across five LLMs. In the future, we aim to investigate the root causes of LLM inconsistencies and propose improvements.
翻译:大语言模型(LLM)若在语义等价的提示下生成语义等价的响应,则被视为具有一致性。尽管近期进展展示了LLM在对话系统中的卓越能力,但我们发现即便是最先进的LLM在其生成结果中仍存在高度不一致性,这对其可靠性提出了质疑。先前研究尝试通过任务特定准确率来测量这一现象,但该方法不适用于如"电车难题"等不存在"正确答案"的道德场景。针对该问题,我们提出了一种基于信息论的创新测量方法——语义图熵(SGE),用于衡量LLM在道德场景中的一致性。我们利用"经验法则"(RoTs)来解释模型的决策策略,并进一步优化了度量指标。与现有的一致性度量相比,SGE在五个LLM上的结果与人类判断的相关性更高。未来,我们将致力于探究LLM不一致性的根源并提出改进方案。