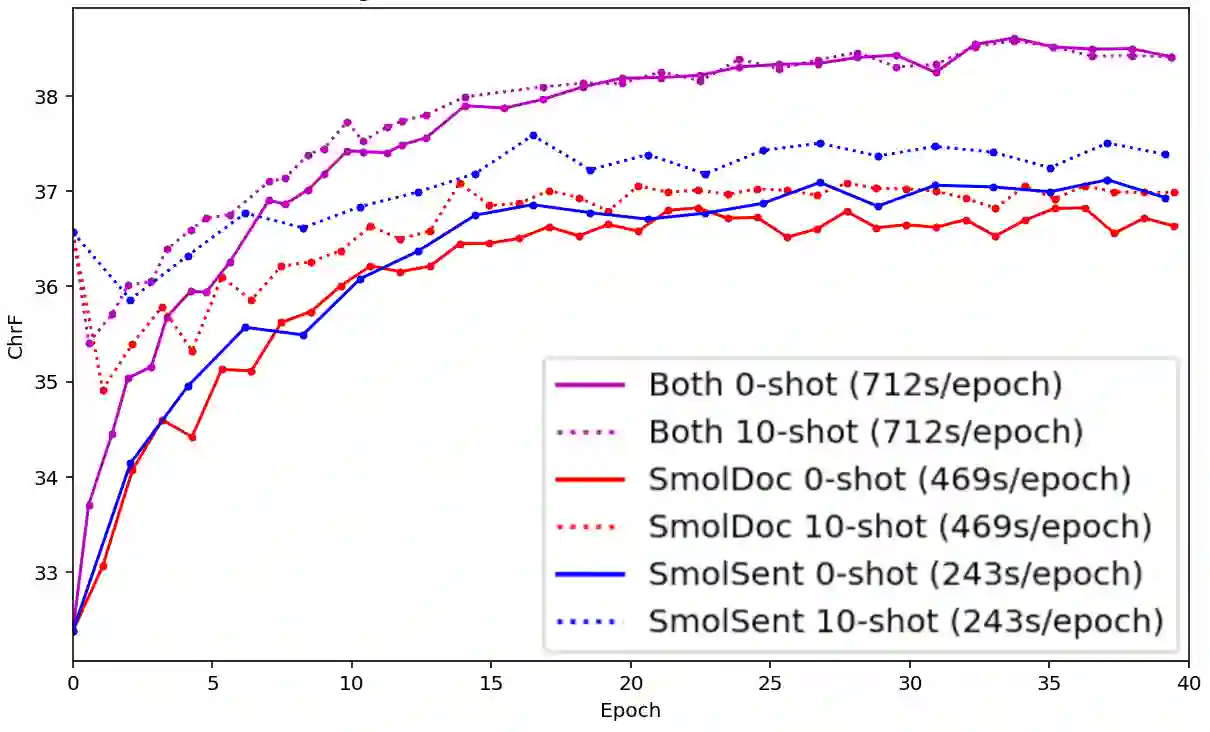
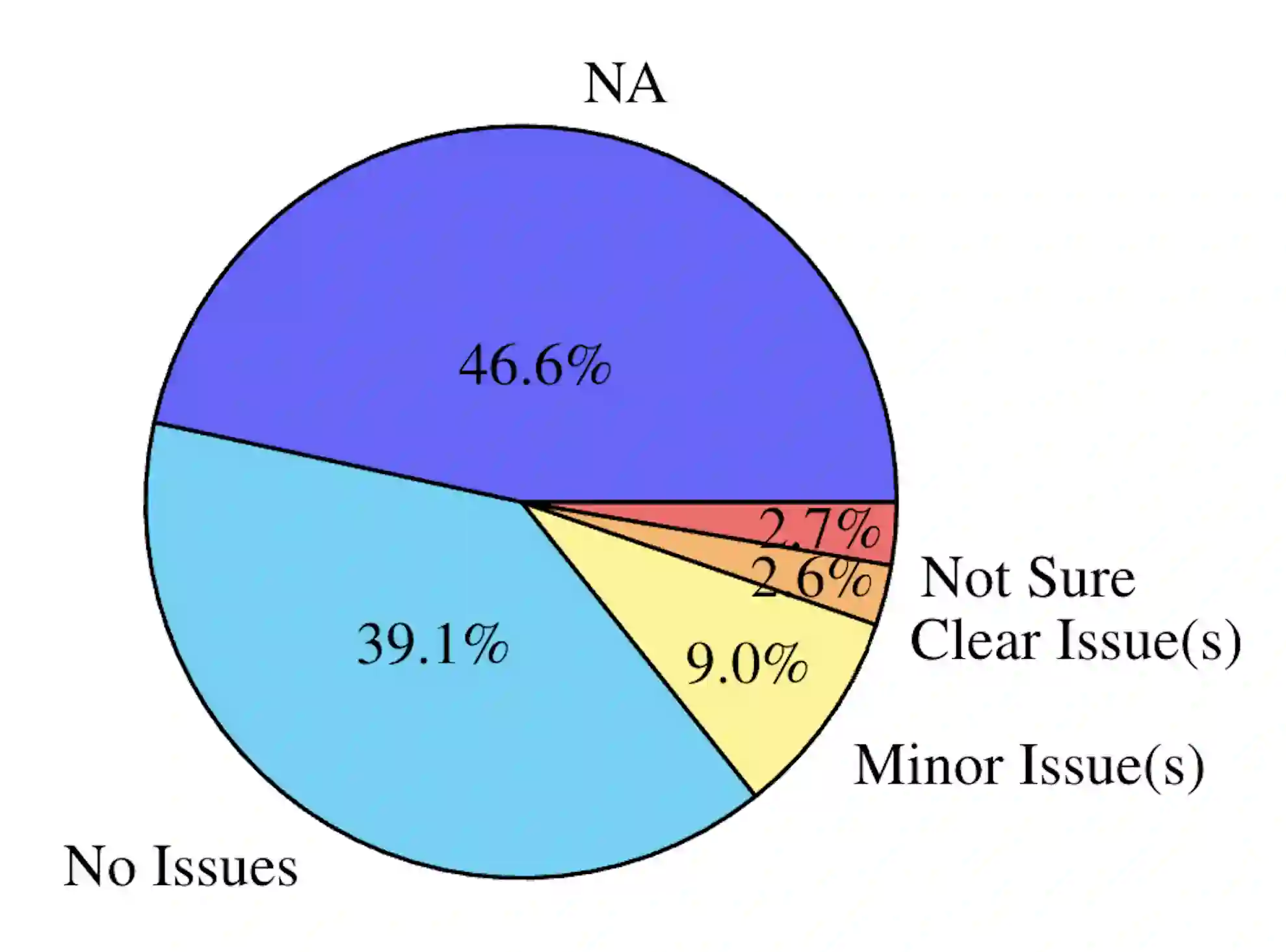
We open-source SMOL (Set of Maximal Overall Leverage), a suite of training data to unlock machine translation for low-resource languages. SMOL has been translated into 124 (and growing) under-resourced languages (125 language pairs), including many for which there exist no previous public resources, for a total of 6.1M translated tokens. SMOL comprises two sub-datasets, each carefully chosen for maximum impact given its size: SMOLSENT, a set of sentences chosen for broad unique token coverage, and SMOLDOC, a document-level resource focusing on a broad topic coverage. They join the already released GATITOS for a trifecta of paragraph, sentence, and token-level content. We demonstrate that using SMOL to prompt or fine-tune Large Language Models yields robust chrF improvements. In addition to translation, we provide factuality ratings and rationales for all documents in SMOLDOC, yielding the first factuality datasets for most of these languages.
翻译:我们开源了SMOL(最大全局效用数据集),这是一套旨在解锁低资源语言机器翻译能力的训练数据。SMOL已涵盖124种(持续增加中)资源匮乏语言(对应125个语言对),其中包含许多此前无公开资源的语种,总计达610万已翻译词元。该数据集包含两个精心设计以最大化规模效益的子集:SMOLSENT(通过广泛唯一词元覆盖度筛选的句子集)与SMOLDOC(专注于多元主题覆盖的文档级资源)。它们与此前发布的GATITOS数据集共同构成段落、句子和词元层级的完整内容体系。实验表明,使用SMOL进行提示工程或微调大语言模型能带来显著的chrF指标提升。除翻译数据外,我们还为SMOLDOC所有文档提供了事实性评分与依据说明,为其中大多数语言构建了首个事实性评估数据集。