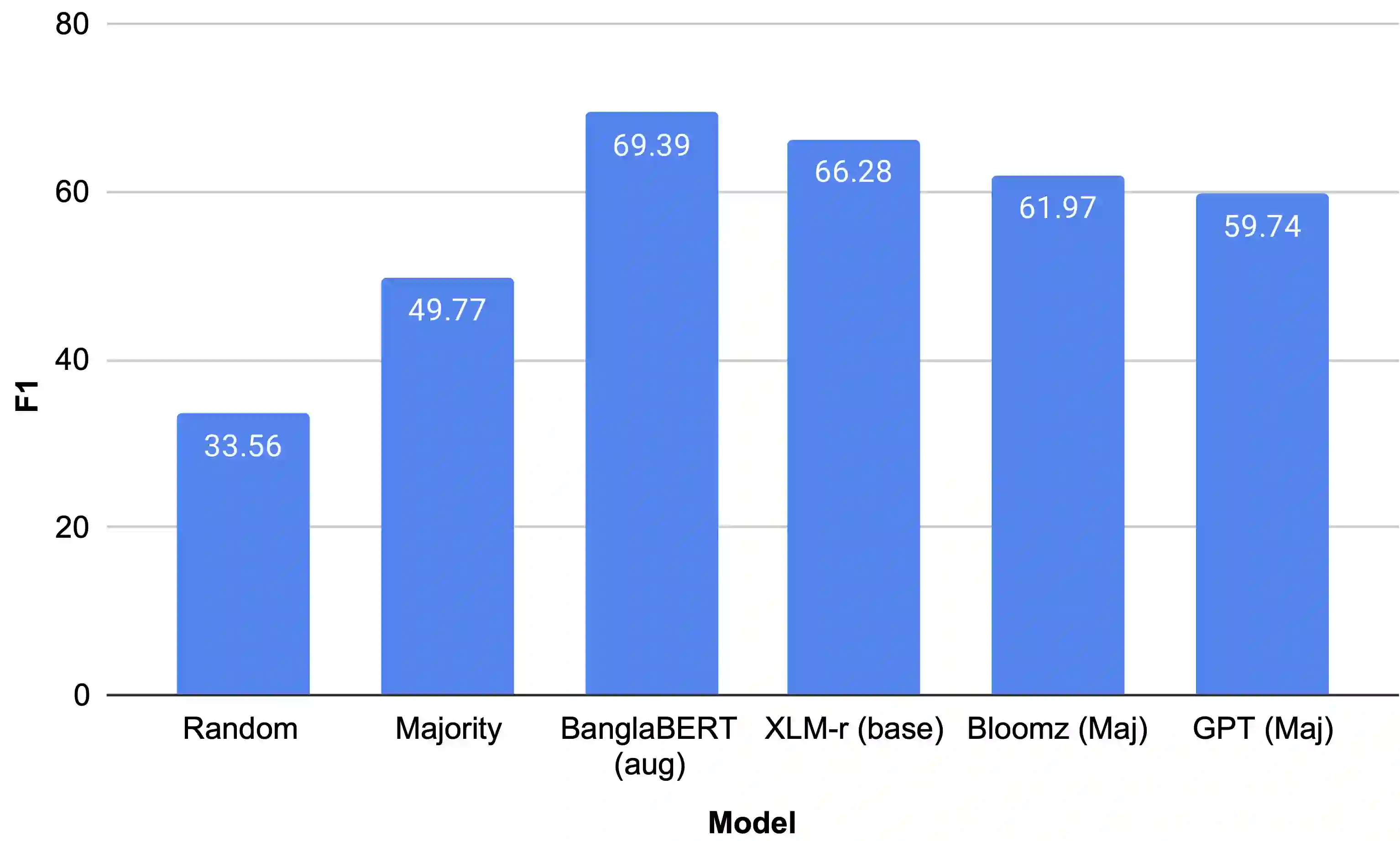
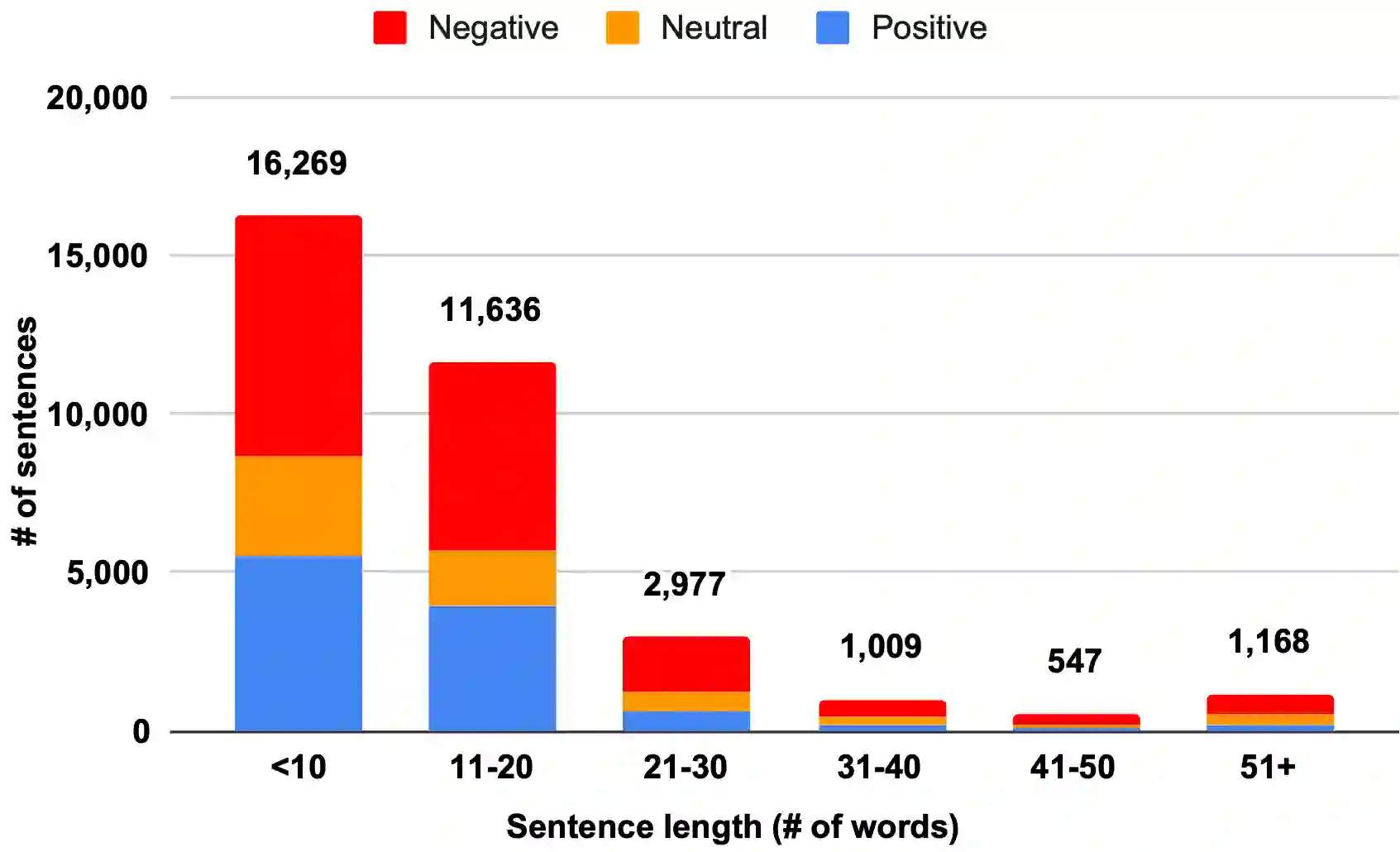
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,605 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community. In the spirit of further research, we plan to make this dataset and our experimental resources publicly accessible to the wider research community.
翻译:数字世界的迅速扩张使情感分析成为营销、政治、客户服务和医疗等多个领域的关键工具。尽管针对广泛使用语言的情感分析已取得显著进展,但由于资源限制,孟加拉语等低资源语言仍缺乏充分研究。此外,大语言模型(LLMs)近期在各应用场景中展现出的前所未有的性能,凸显了在低资源语言背景下对其进行评估的必要性。本研究提出了一个大规模人工标注数据集,包含33,605条孟加拉语新闻推文和Facebook评论。我们还研究了基于Flan-T5、GPT-4和Bloomz等多种语言模型的零样本与少样本上下文学习,并与微调模型进行了比较分析。研究结果表明,基于Transformer的单语模型即使在零样本和少样本场景下也始终优于其他模型。为促进持续探索,我们计划向更广泛的研究社区公开此数据集及研究工具。本着进一步研究的精神,我们拟将本数据集与实验资源公开提供给学术界。