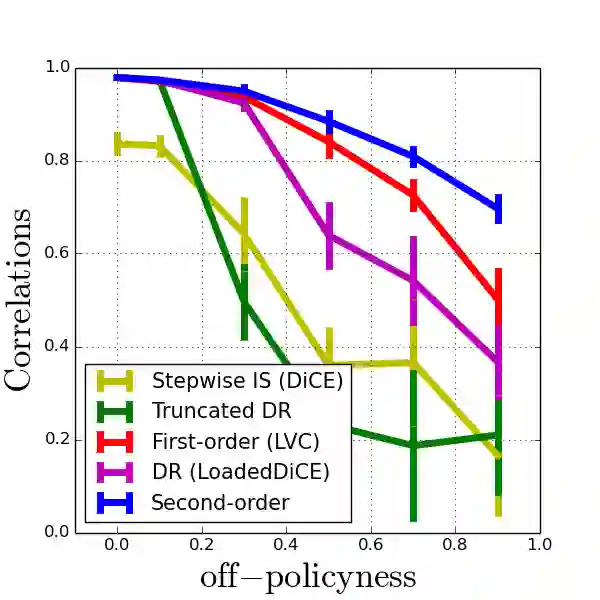
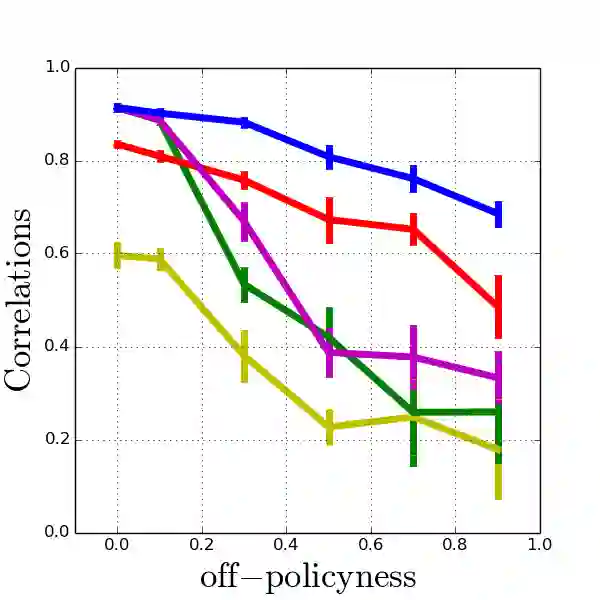
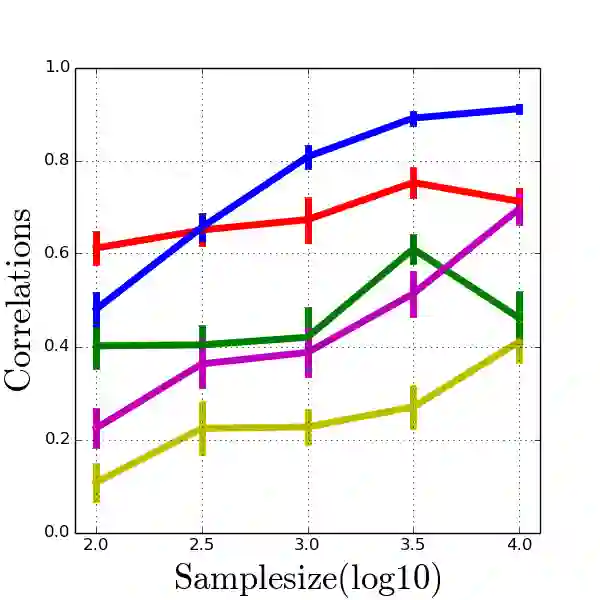
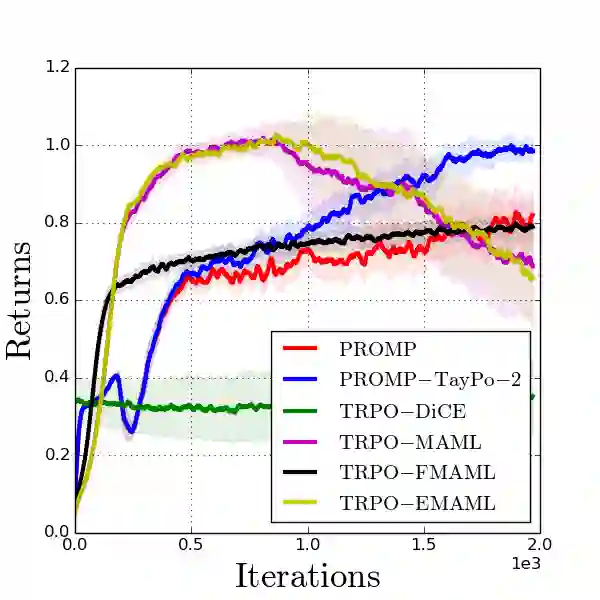
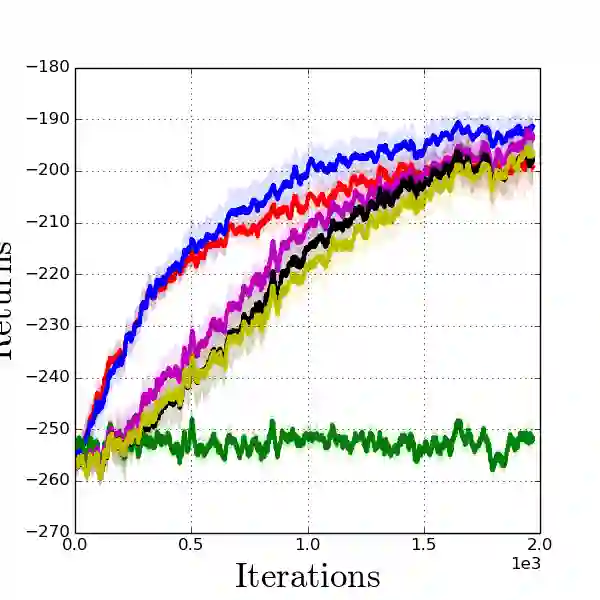
Model-agnostic meta-reinforcement learning requires estimating the Hessian matrix of value functions. This is challenging from an implementation perspective, as repeatedly differentiating policy gradient estimates may lead to biased Hessian estimates. In this work, we provide a unifying framework for estimating higher-order derivatives of value functions, based on off-policy evaluation. Our framework interprets a number of prior approaches as special cases and elucidates the bias and variance trade-off of Hessian estimates. This framework also opens the door to a new family of estimates, which can be easily implemented with auto-differentiation libraries, and lead to performance gains in practice.
翻译:从执行角度看,这具有挑战性,因为反复区分政策梯度估计可能导致偏颇的黑森估计。在这项工作中,我们根据非政策评价,为估算价值函数的较高级衍生物提供了一个统一框架。我们的框架将以前的一些方法解释为特殊案例,并阐明了赫森估计的偏差和差异权衡。这个框架还打开了新一轮估计数的大门,这种估计数可以很容易地由自动差异图书馆执行,并导致实践中的业绩收益。