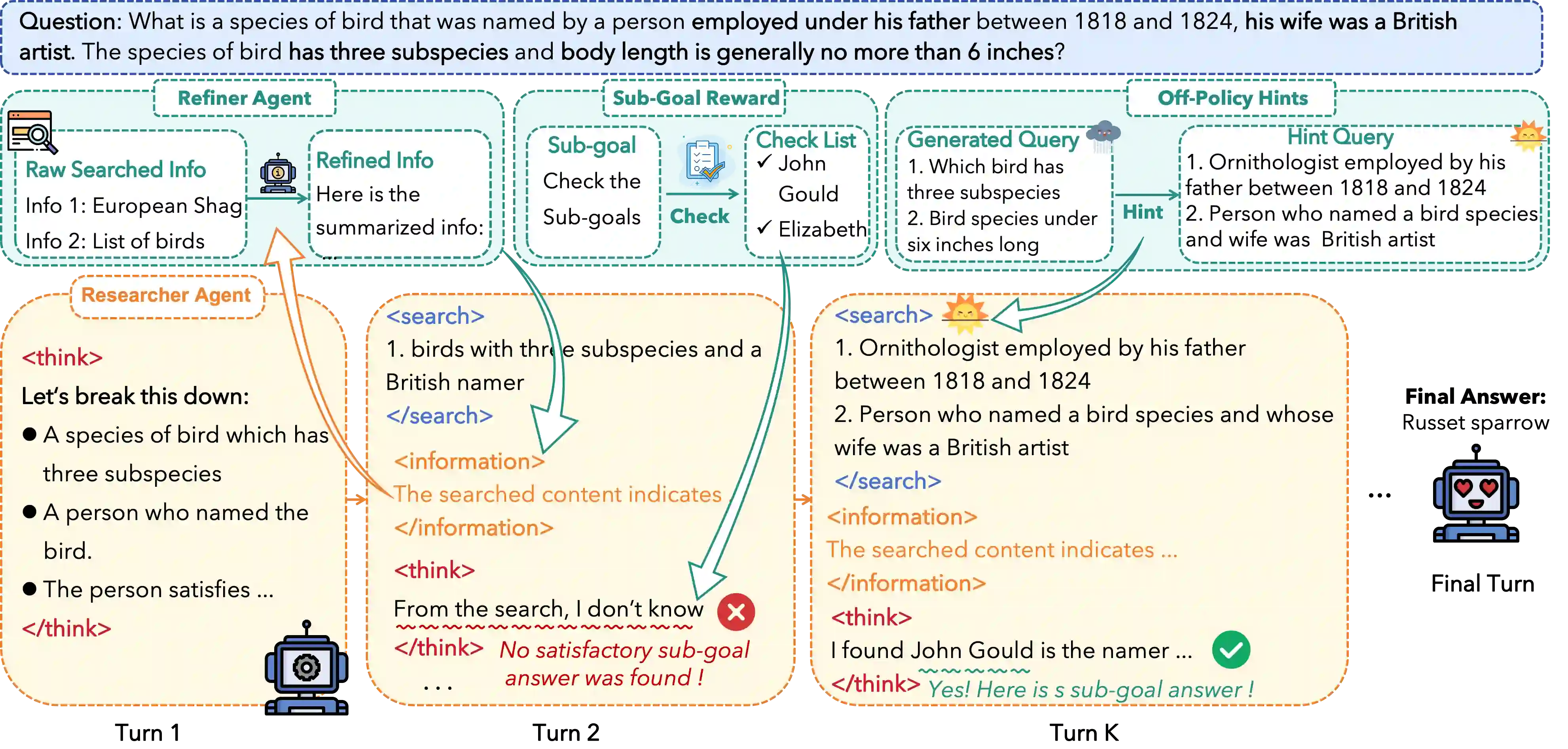
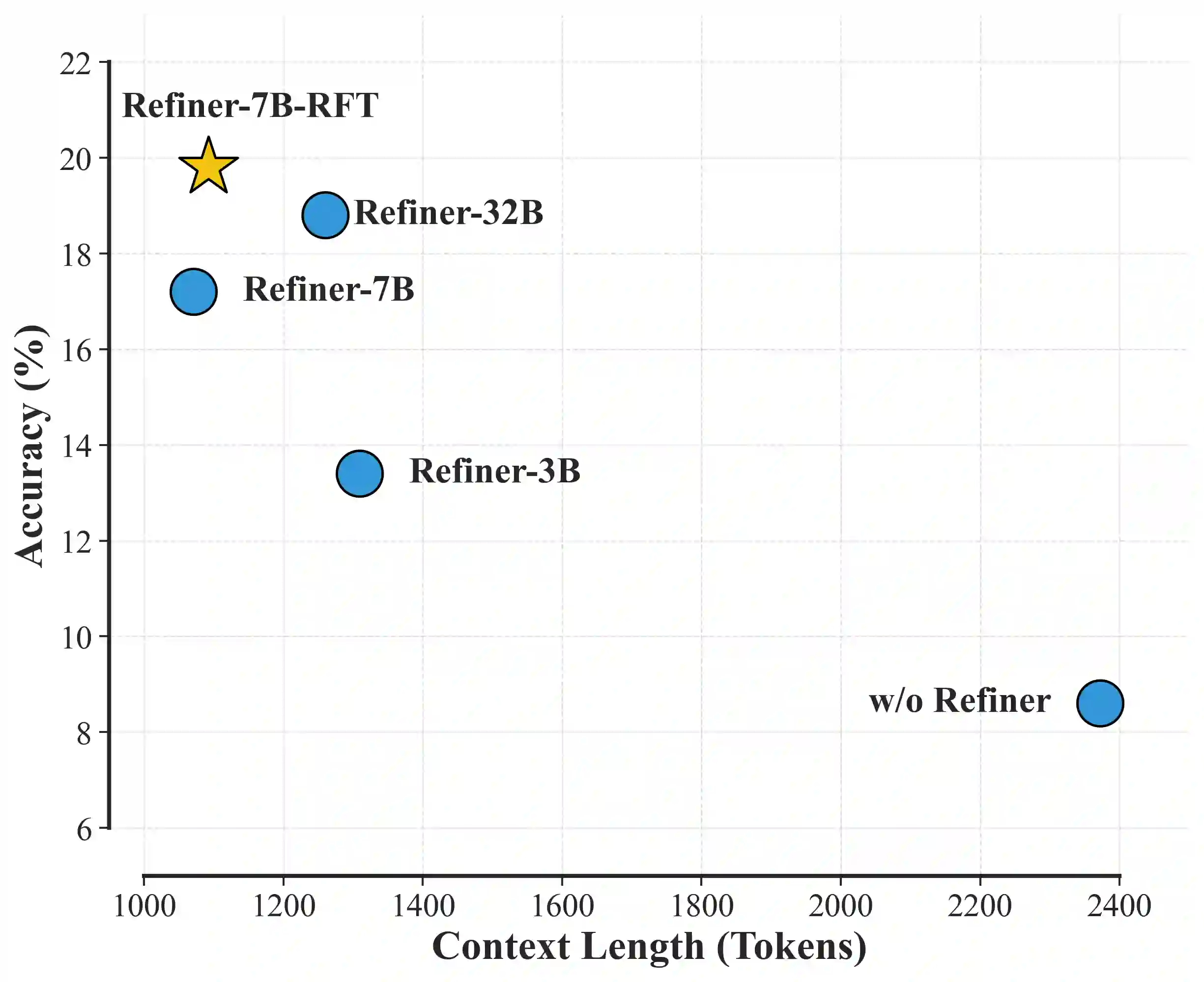
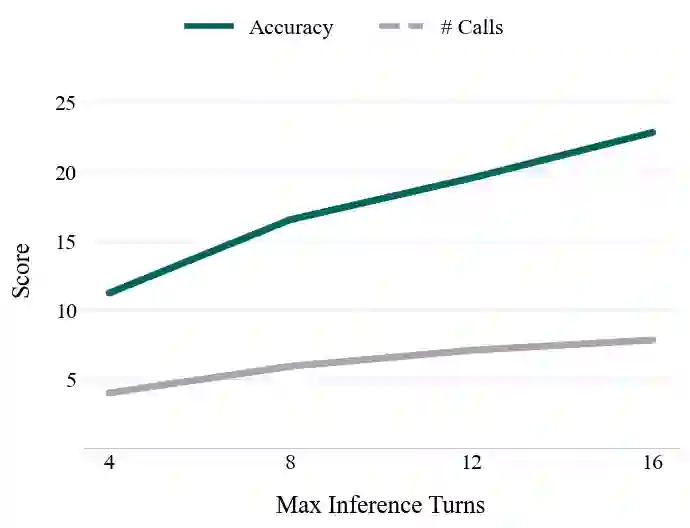
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
翻译:可验证奖励强化学习(RLVR)是增强智能体深度搜索能力的一种有前景的方法。然而,其在深度搜索场景中的应用常受低**奖励密度**的制约,即智能体需付出大量探索成本,却仅获得稀疏甚至为零的最终奖励。本文将此挑战形式化为**奖励密度优化**问题,其目标在于提升单位探索成本所获的奖励。本文提出**InfoFlow**,一个从三方面系统性地解决该问题的框架:1) **子问题分解**:将长程任务拆解以分配过程奖励,从而提供更密集的学习信号;2) **失败引导提示**:向停滞的轨迹注入纠正性引导,以提高成功结果的概率;3) **双智能体精炼**:采用双智能体架构以分担深度探索的认知负荷。其中,精炼智能体综合搜索历史,有效压缩研究者感知的轨迹,从而降低探索成本并提升整体奖励密度。我们在多个智能体搜索基准测试中评估InfoFlow,其表现显著优于强基线方法,使轻量级大语言模型能够达到与先进专有大语言模型相当的性能。