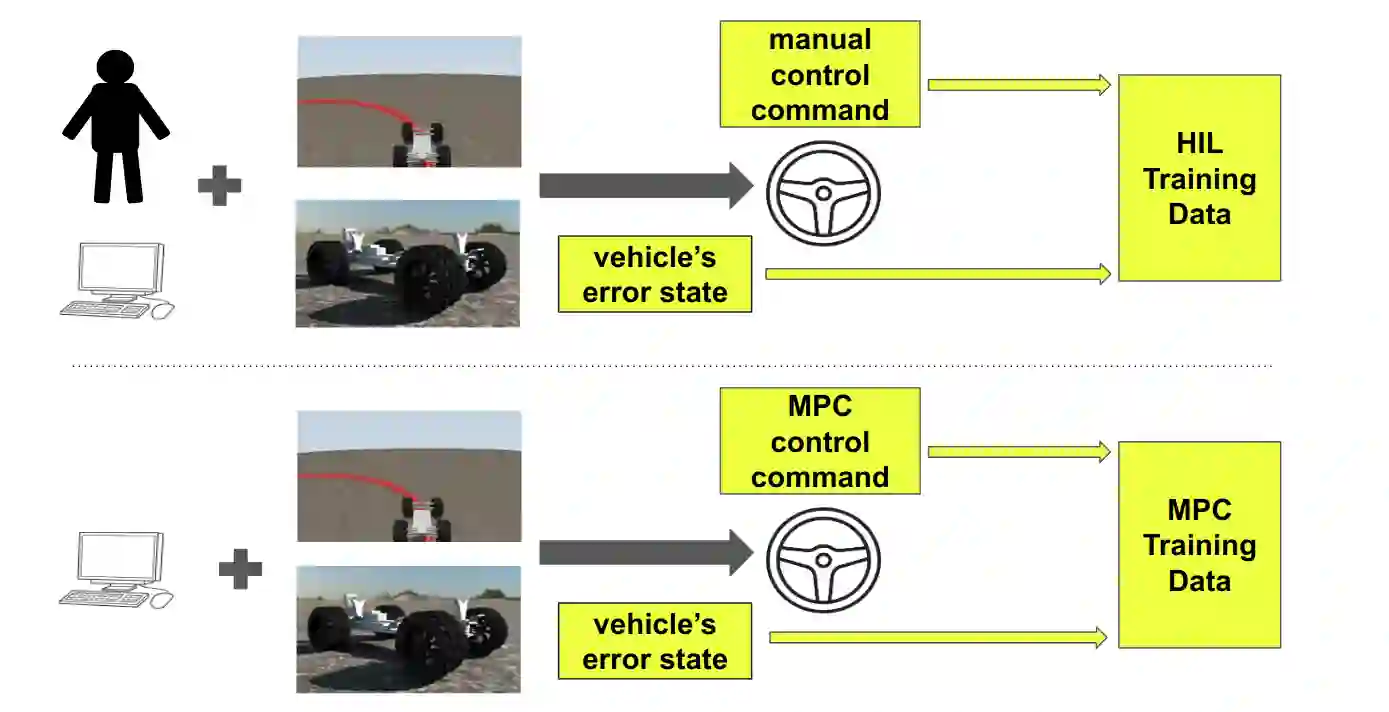
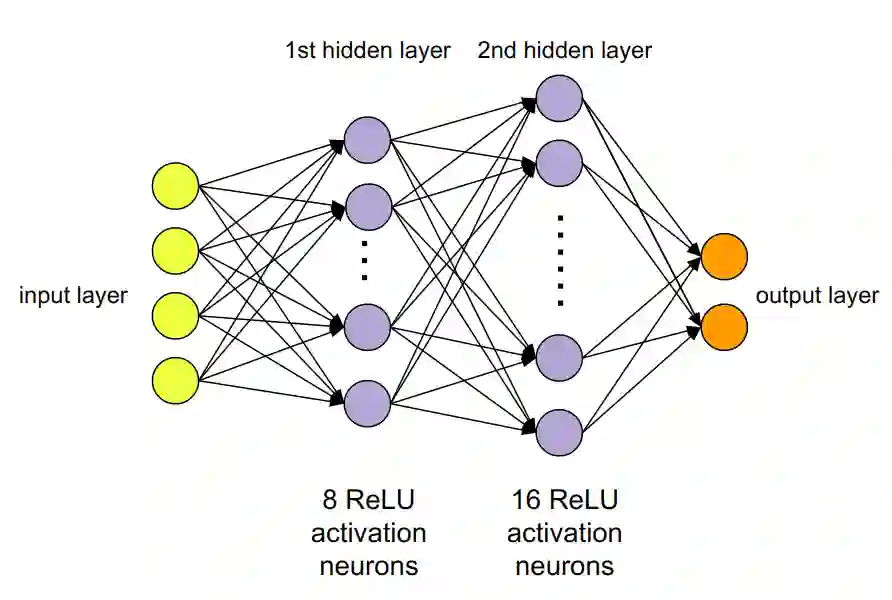
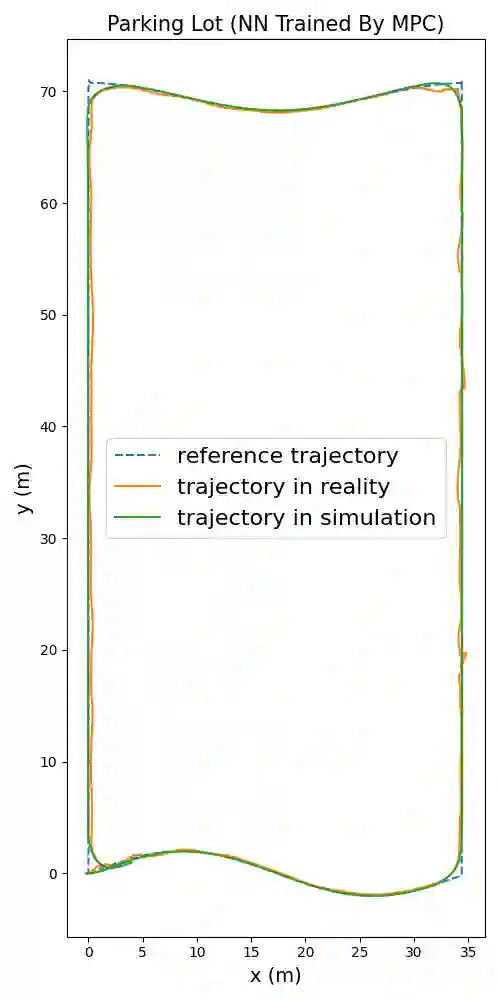
We report on a study that employs an in-house developed simulation infrastructure to accomplish zero shot policy transferability for a control policy associated with a scale autonomous vehicle. We focus on implementing policies that require no real world data to be trained (Zero-Shot Transfer), and are developed in-house as opposed to being validated by previous works. We do this by implementing a Neural Network (NN) controller that is trained only on a family of circular reference trajectories. The sensors used are RTK-GPS and IMU, the latter for providing heading. The NN controller is trained using either a human driver (via human in the loop simulation), or a Model Predictive Control (MPC) strategy. We demonstrate these two approaches in conjunction with two operation scenarios: the vehicle follows a waypoint-defined trajectory at constant speed; and the vehicle follows a speed profile that changes along the vehicle's waypoint-defined trajectory. The primary contribution of this work is the demonstration of Zero-Shot Transfer in conjunction with a novel feed-forward NN controller trained using a general purpose, in-house developed simulation platform.
翻译:我们报告了一项利用内部开发的仿真基础设施,实现缩比自主车辆控制策略的零样本可迁移性的研究。重点在于实现无需真实世界数据进行训练(即零样本迁移)的策略,这些策略由我们自主开发,而非基于前人工作的验证。为此,我们设计了一个神经网络(NN)控制器,该控制器仅通过一组圆形参考轨迹进行训练。所使用的传感器包括RTK-GPS和IMU,其中IMU用于提供航向信息。该神经网络控制器的训练方式可采用人类驾驶员(通过人在环仿真)或模型预测控制(MPC)策略。我们结合两种操作场景演示了这两种方法:车辆以恒定速度沿路点定义的轨迹行驶;以及车辆沿路点定义的轨迹按动态变化的速度曲线行驶。本研究的主要贡献在于:首次将零样本迁移与一种新颖的前馈神经网络控制器相结合,该控制器基于通用型内部仿真平台进行训练。