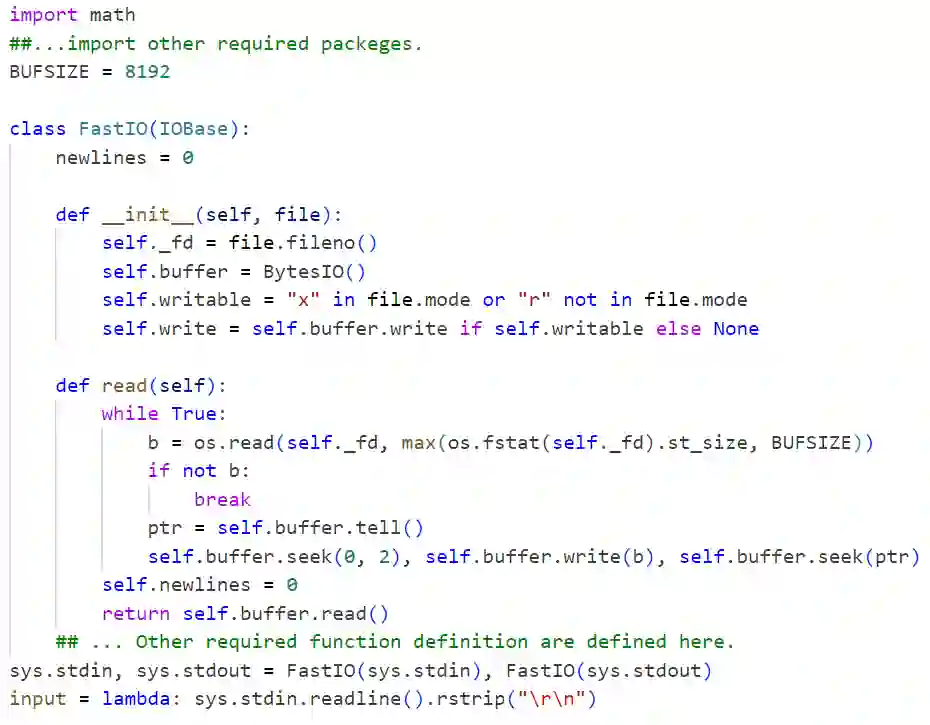
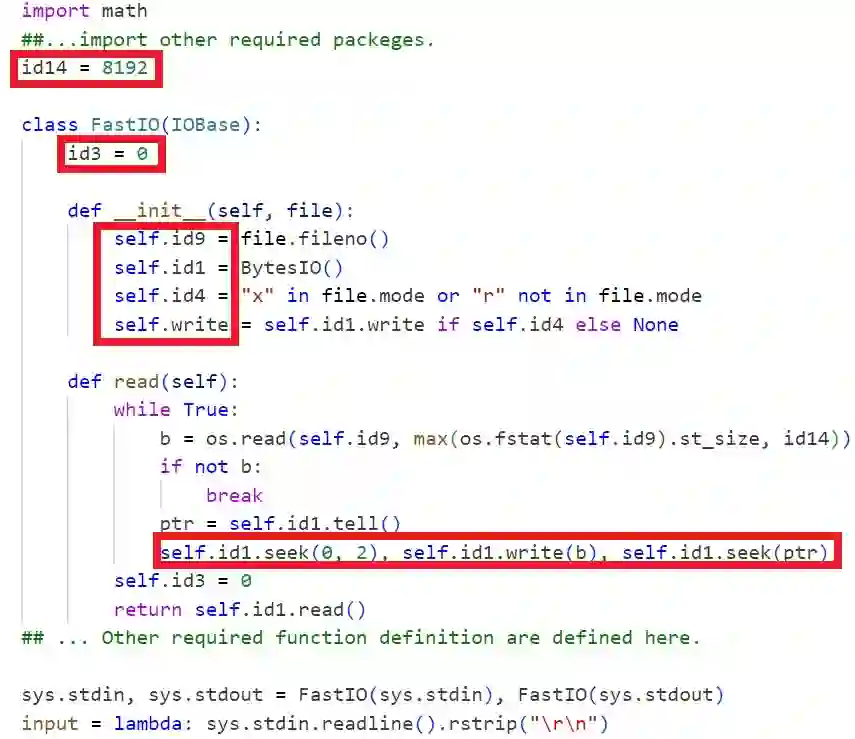
In the domain of software development, LLMs have been utilized to automate tasks such as code translation, where source code from one programming language is translated to another while preserving its functionality. However, LLMs often struggle with long source codes that don't fit into the context window, which produces inaccurate translations. To address this, we propose a novel zero-shot code translation method that incorporates identifier replacement. By substituting user-given long identifiers with generalized placeholders during translation, our method allows the LLM to focus on the logical structure of the code, by reducing token count and memory usage, which improves the efficiency and cost-effectiveness of long code translation. Our empirical results demonstrate that our approach preserves syntactical and hierarchical information and produces translation results with reduced tokens.
翻译:在软件开发领域,大语言模型已被用于自动化代码翻译等任务,即将源代码从一种编程语言转换为另一种语言,同时保持其功能不变。然而,大语言模型在处理超出上下文窗口长度的长源代码时,往往难以生成准确的翻译结果。为解决这一问题,本文提出了一种新颖的零样本代码翻译方法,该方法引入了标识符替换机制。通过在翻译过程中将用户给定的长标识符替换为通用占位符,本方法使大语言模型能够专注于代码的逻辑结构,同时减少令牌数量和内存占用,从而提升长代码翻译的效率和成本效益。实验结果表明,该方法能够有效保留语法和层次结构信息,并生成令牌数更少的翻译结果。