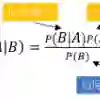
Labeling mistakes are frequently encountered in real-world applications. If not treated well, the labeling mistakes can deteriorate the classification performances of a model seriously. To address this issue, we propose an improved Naive Bayes method for text classification. It is analytically simple and free of subjective judgements on the correct and incorrect labels. By specifying the generating mechanism of incorrect labels, we optimize the corresponding log-likelihood function iteratively by using an EM algorithm. Our simulation and experiment results show that the improved Naive Bayes method greatly improves the performances of the Naive Bayes method with mislabeled data.
翻译:标注错误在实际应用中频繁出现。若未妥善处理,这些标注错误会严重降低模型的分类性能。为解决此问题,我们提出一种用于文本分类的改进朴素贝叶斯方法。该方法在分析上简洁明了,且无需对正确与错误标签进行主观判断。通过指定错误标签的生成机制,我们利用EM算法迭代优化相应的对数似然函数。模拟与实验结果表明,在处理含错误标注数据时,改进的朴素贝叶斯方法大幅提升了传统朴素贝叶斯方法的性能。