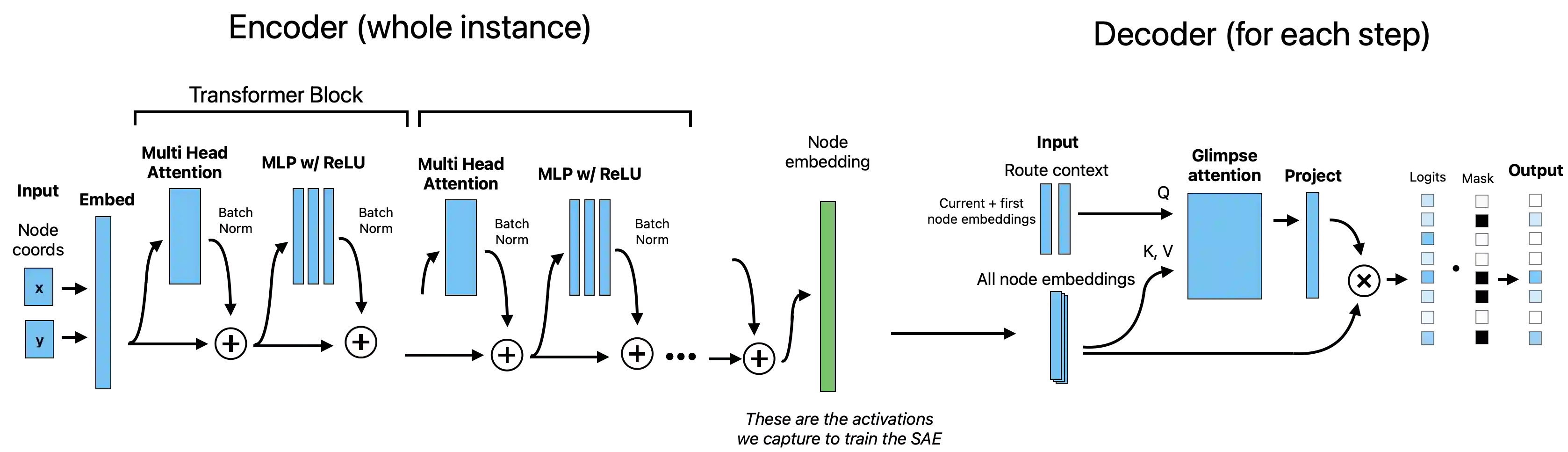
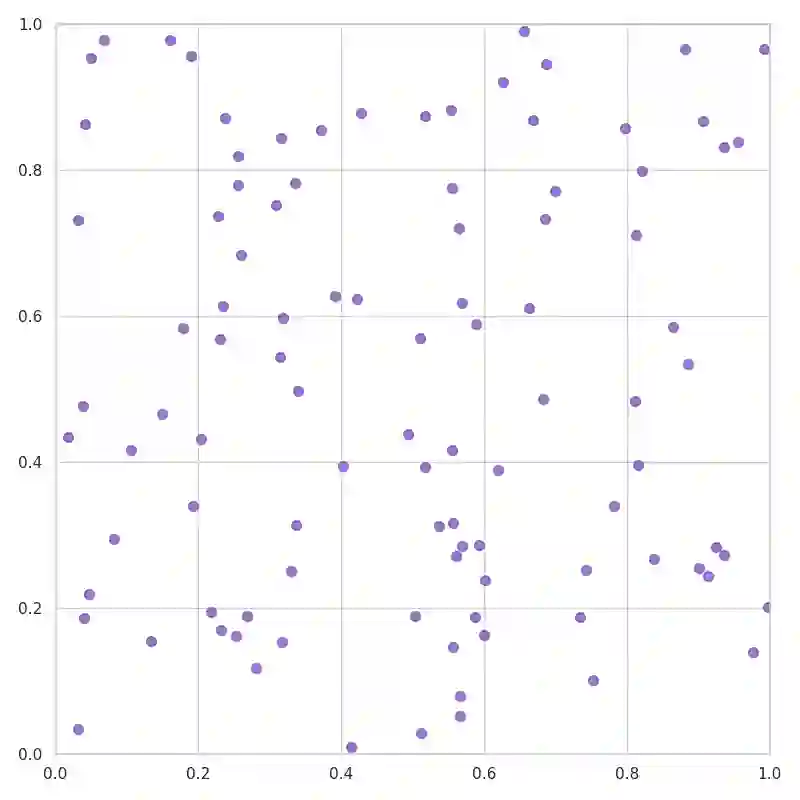
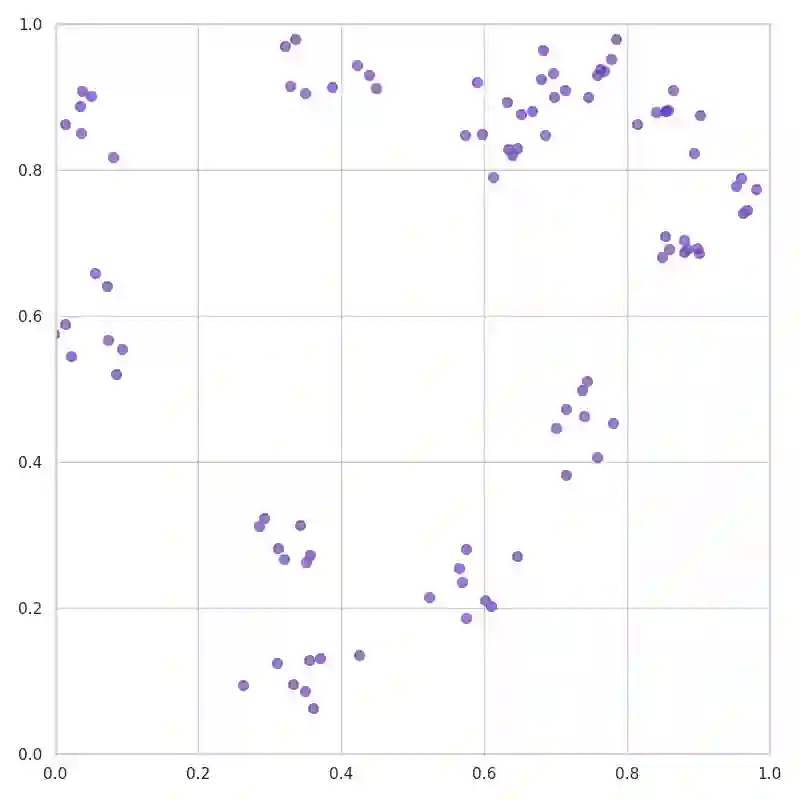
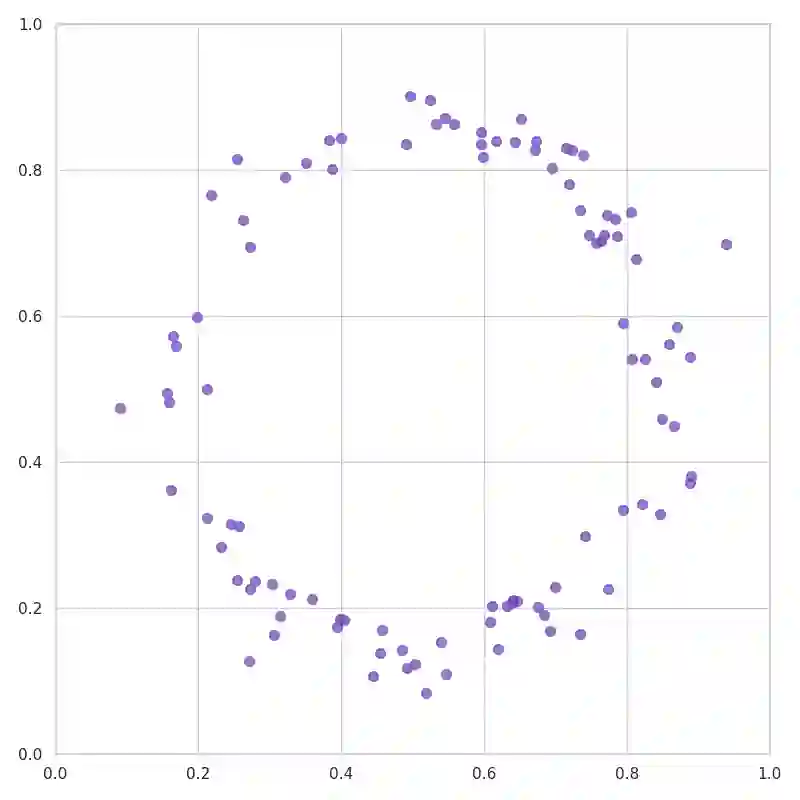
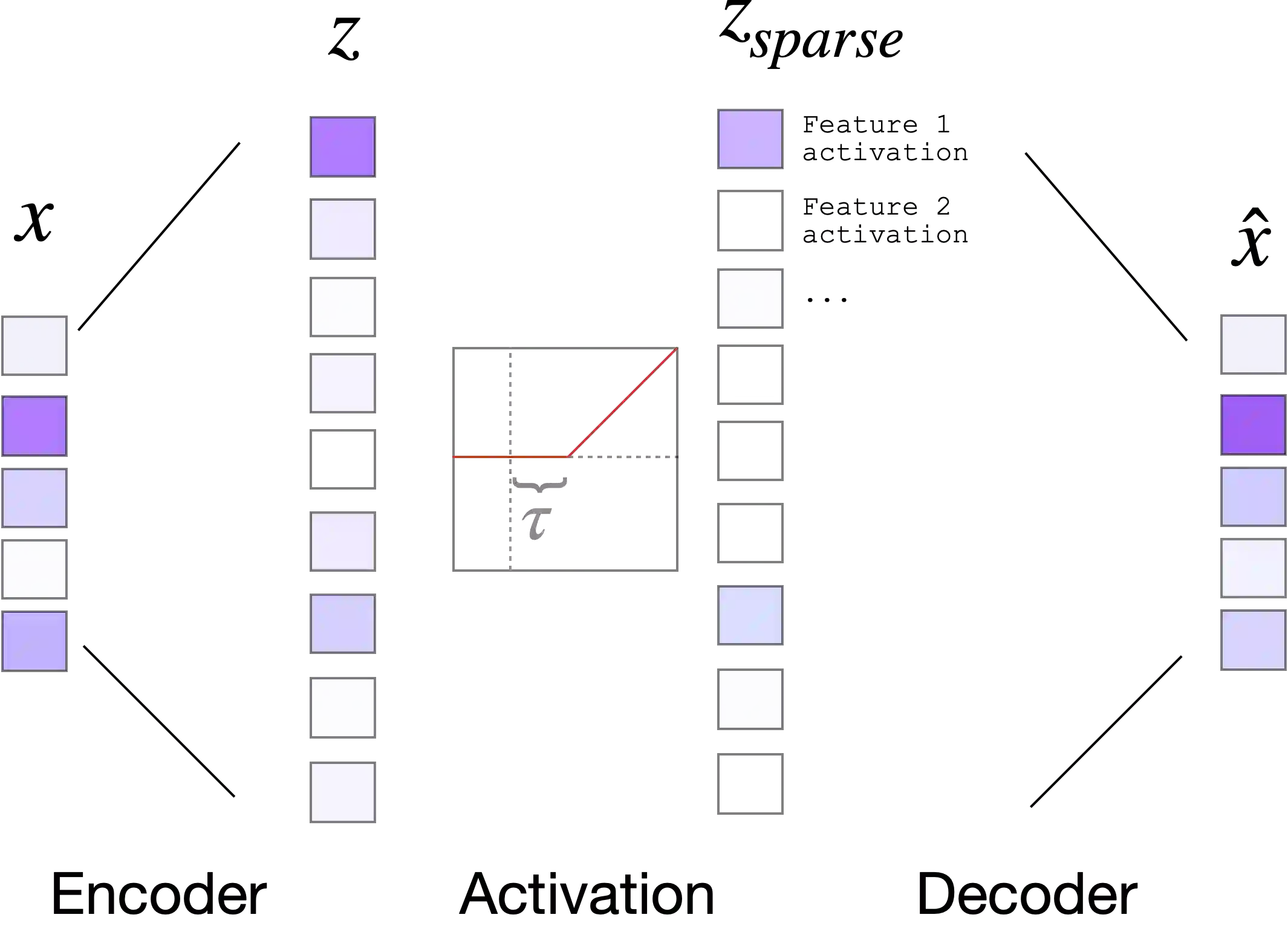
Neural networks have advanced combinatorial optimization, with Transformer-based solvers achieving near-optimal solutions on the Traveling Salesman Problem (TSP) in milliseconds. However, these models operate as black boxes, providing no insight into the geometric patterns they learn or the heuristics they employ during tour construction. We address this opacity by applying sparse autoencoders (SAEs), a mechanistic interpretability technique, to a Transformer-based TSP solver, representing the first application of activation-based interpretability methods to operations research models. We train a pointer network with reinforcement learning on 100-node instances, then fit an SAE to the encoder's residual stream to discover an overcomplete dictionary of interpretable features. Our analysis reveals that the solver naturally develops features mirroring fundamental TSP concepts: boundary detectors that activate on convex-hull nodes, cluster-sensitive features responding to locally dense regions, and separator features encoding geometric partitions. These findings provide the first model-internal account of what neural TSP solvers compute before node selection, demonstrate that geometric structure emerges without explicit supervision, and suggest pathways toward transparent hybrid systems that combine neural efficiency with algorithmic interpretability. Interactive feature explorer: https://reubennarad.github.io/TSP_interp
翻译:神经网络在组合优化领域取得了显著进展,基于Transformer的求解器能够在毫秒级时间内为旅行商问题(TSP)提供接近最优的解。然而,这些模型如同黑箱般运行,无法揭示其学习到的几何模式或在路径构建过程中采用的启发式策略。针对这一不透明性问题,我们首次将稀疏自编码器(SAEs)——一种机制可解释性技术——应用于基于Transformer的TSP求解器,这也是基于激活的可解释性方法在运筹学模型中的首次应用。我们在100节点规模的实例上通过强化学习训练指针网络,随后对编码器残差流拟合SAE,以发现过完备的可解释特征字典。分析表明,求解器自发形成了与TSP基础概念相对应的特征:在凸包节点上激活的边界检测器、对局部密集区域响应的聚类敏感特征,以及编码几何划分的分隔特征。这些发现首次从模型内部揭示了神经TSP求解器在节点选择前的计算机制,证明了无显式监督下几何结构的自发涌现,并为构建融合神经高效性与算法可解释性的透明混合系统提供了新路径。交互式特征探索平台:https://reubennarad.github.io/TSP_interp