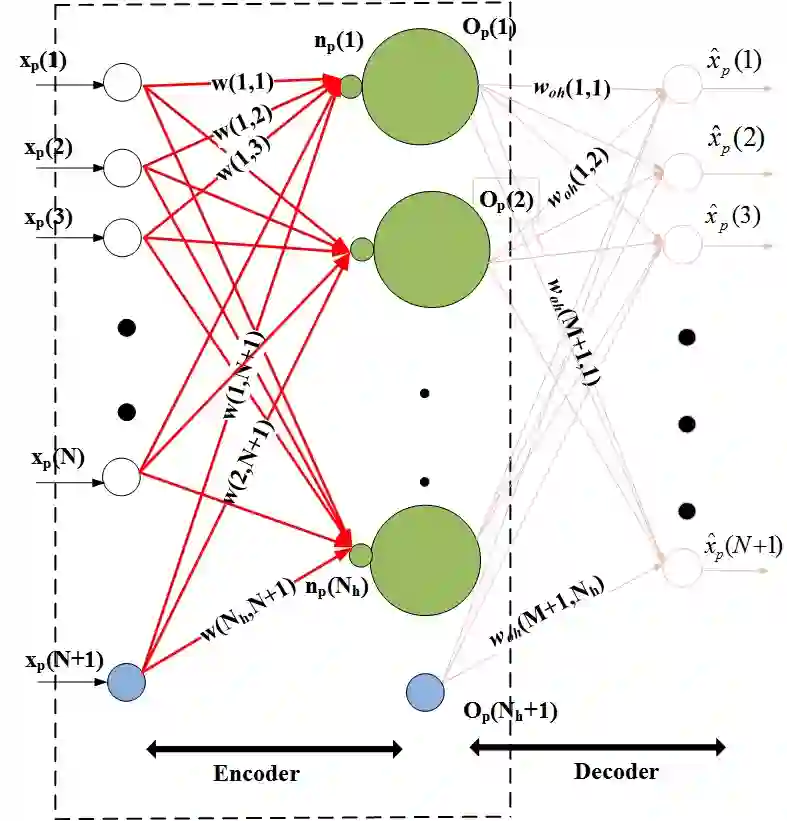
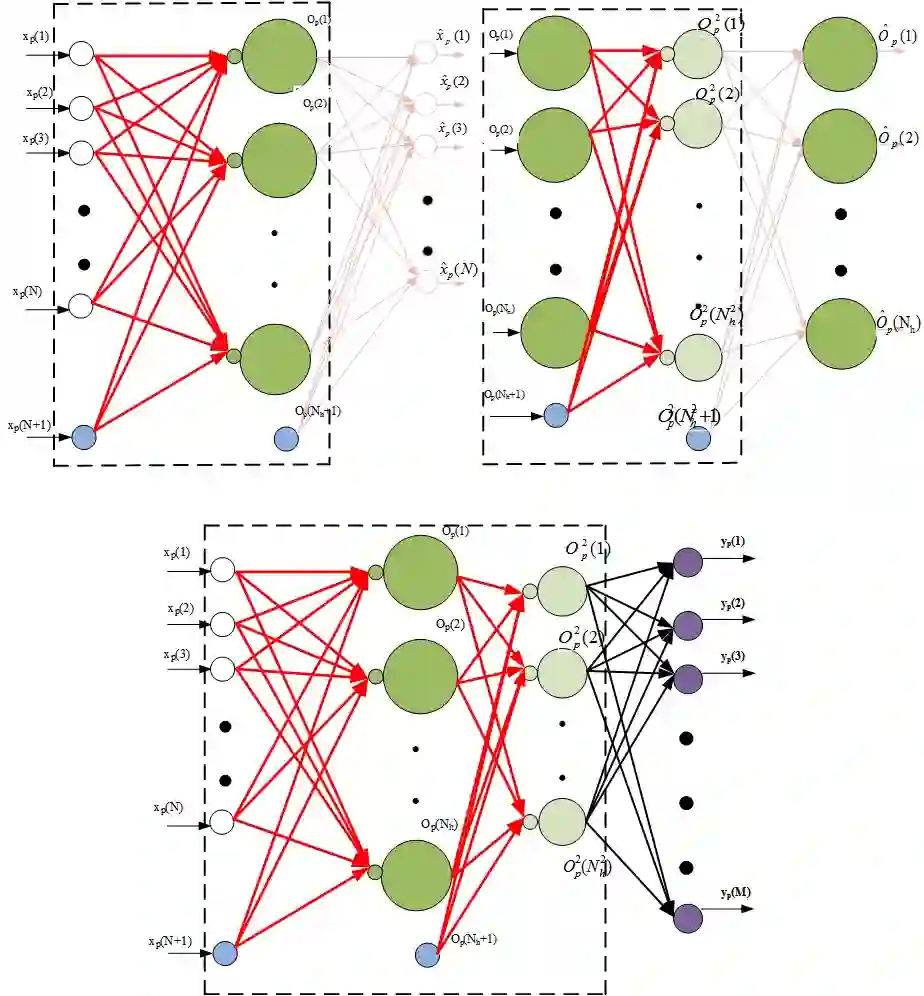
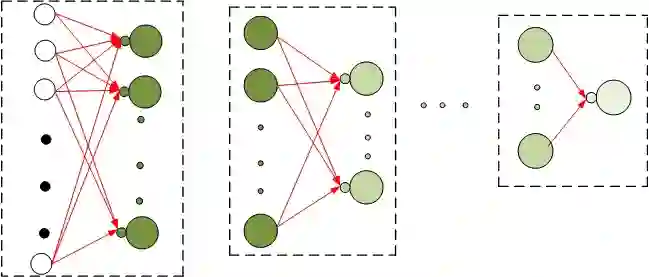
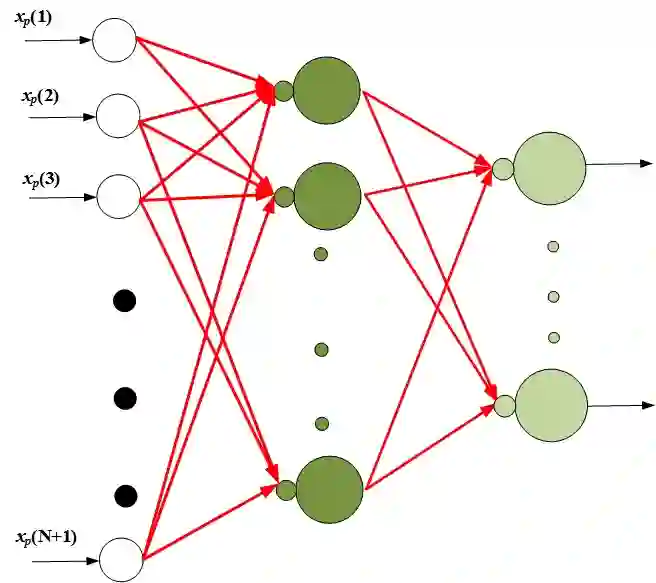
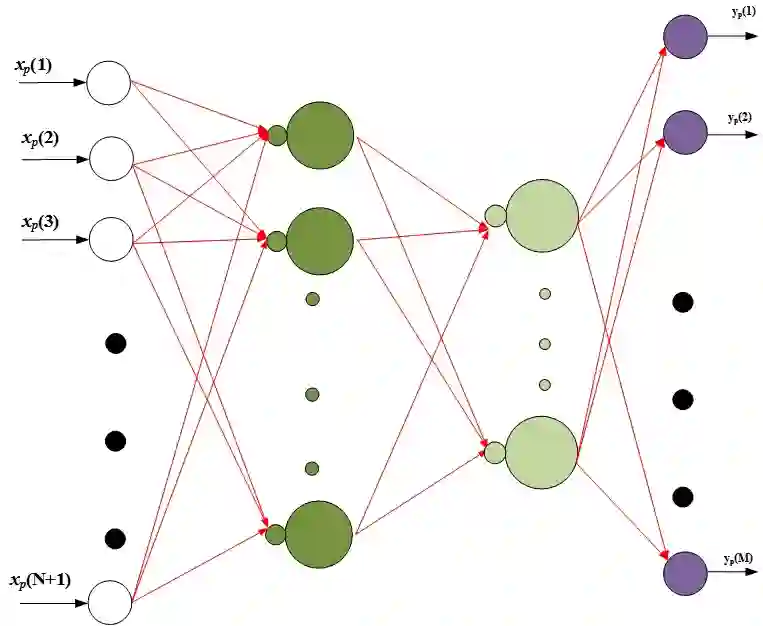
We propose a multi-step training method for designing generalized linear classifiers. First, an initial multi-class linear classifier is found through regression. Then validation error is minimized by pruning of unnecessary inputs. Simultaneously, desired outputs are improved via a method similar to the Ho-Kashyap rule. Next, the output discriminants are scaled to be net functions of sigmoidal output units in a generalized linear classifier. We then develop a family of batch training algorithm for the multi layer perceptron that optimizes its hidden layer size and number of training epochs. Next, we combine pruning with a growing approach. Later, the input units are scaled to be the net function of the sigmoidal output units that are then feed into as input to the MLP. We then propose resulting improvements in each of the deep learning blocks thereby improving the overall performance of the deep architecture. We discuss the principles and formulation regarding learning algorithms for deep autoencoders. We investigate several problems in deep autoencoders networks including training issues, the theoretical, mathematical and experimental justification that the networks are linear, optimizing the number of hidden units in each layer and determining the depth of the deep learning model. A direct implication of the current work is the ability to construct fast deep learning models using desktop level computational resources. This, in our opinion, promotes our design philosophy of building small but powerful algorithms. Performance gains are demonstrated at each step. Using widely available datasets, the final network's ten fold testing error is shown to be less than that of several other linear, generalized linear classifiers, multi layer perceptron and deep learners reported in the literature.
翻译:我们提出一种用于设计广义线性分类器的多步训练方法。首先,通过回归方法找到初始的多类线性分类器。然后,通过剪枝不必要的输入来最小化验证误差。同时,采用类似于Ho-Kashyap规则的方法改进期望输出。接着,将输出判别函数缩放为广义线性分类器中S型输出单元的净函数。随后,我们开发了一族针对多层感知器的批量训练算法,可优化其隐藏层大小与训练轮数。进一步地,我们将剪枝与增长方法相结合。之后,对输入单元进行缩放,使其成为S型输出单元的净函数,并作为多层感知器的输入。最后,我们提出针对各个深度学习模块的改进方案,从而提升深层架构的整体性能。本文讨论了深度自编码器学习算法的原理与公式推导,研究了深度自编码器网络中的若干问题,包括训练难题、网络线性的理论/数学/实验证明、每层隐藏单元数量的优化以及深度学习模型深度的确定。本工作的直接意义在于能够利用桌面级计算资源构建快速深度学习模型——这体现了我们“构建小而强算法”的设计理念。每一步的改进均以性能提升佐证。基于广泛使用的数据集,最终网络的十倍交叉验证误差低于文献中报道的其他线性分类器、广义线性分类器、多层感知器及深度学习模型。