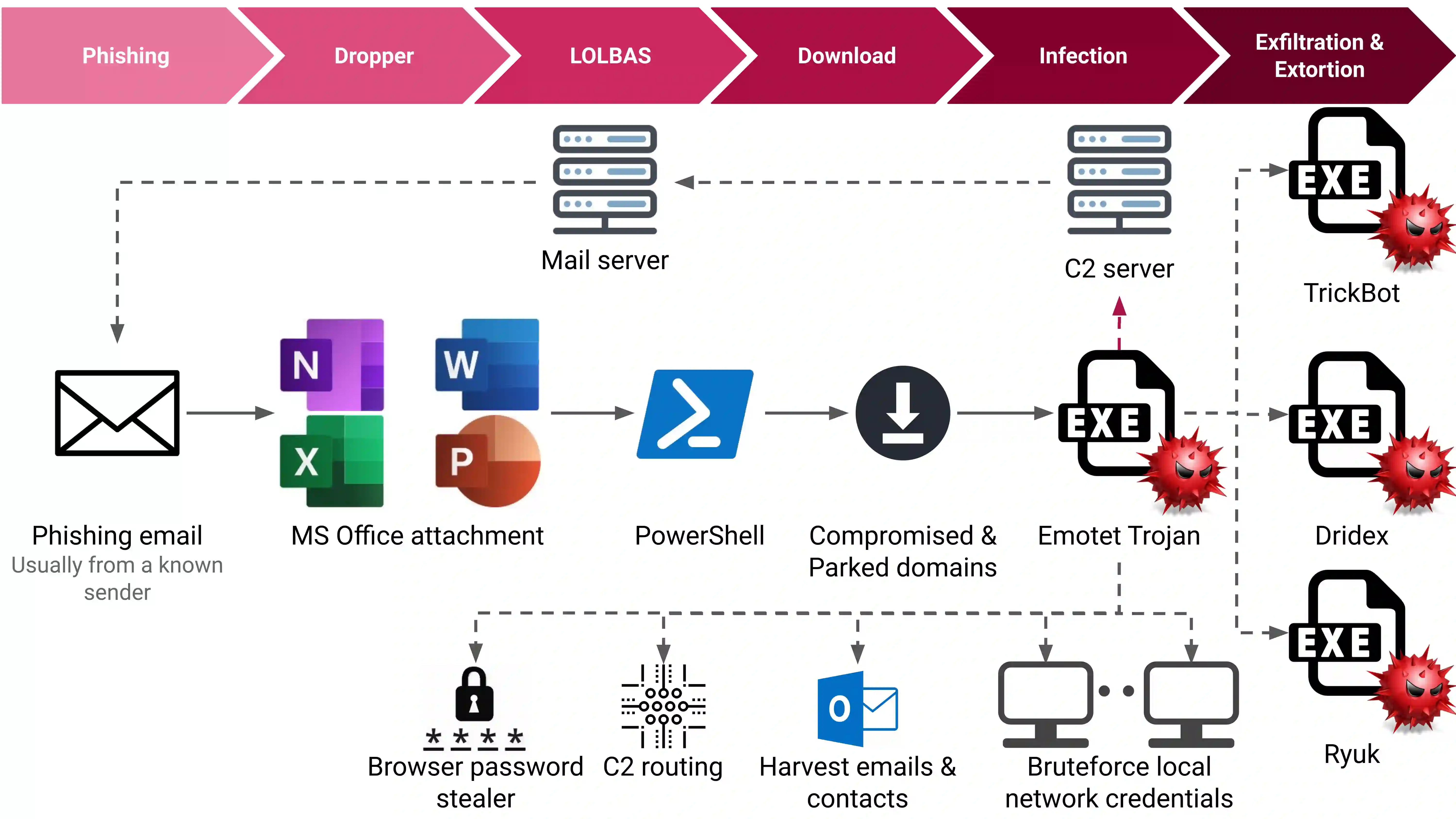
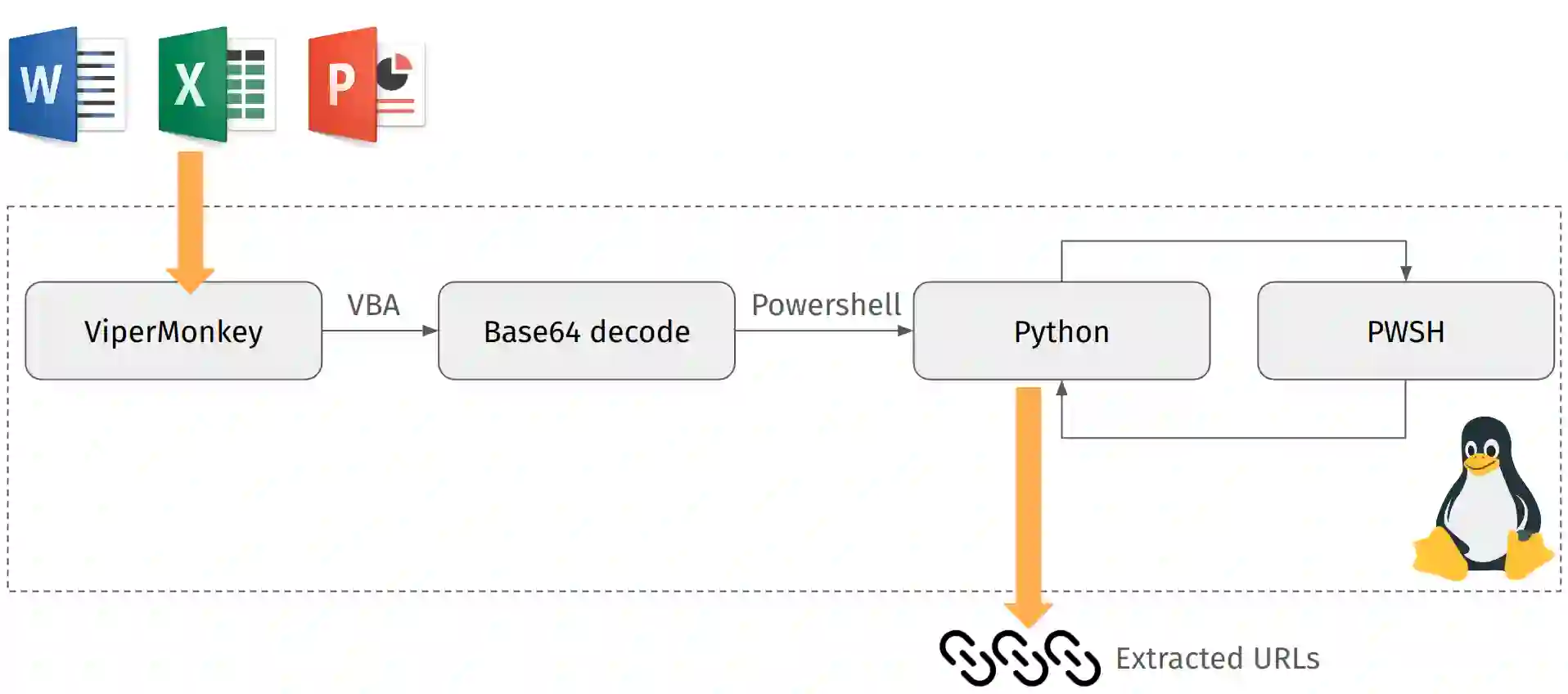
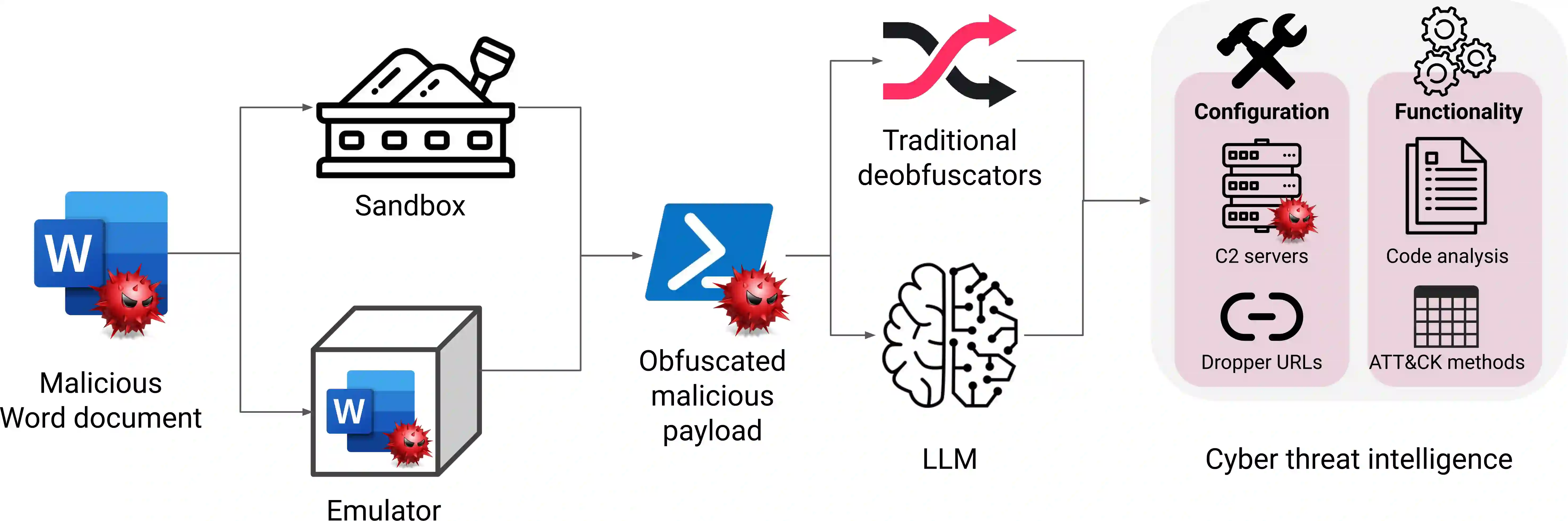
The integration of large language models (LLMs) into various pipelines is increasingly widespread, effectively automating many manual tasks and often surpassing human capabilities. Cybersecurity researchers and practitioners have recognised this potential. Thus, they are actively exploring its applications, given the vast volume of heterogeneous data that requires processing to identify anomalies, potential bypasses, attacks, and fraudulent incidents. On top of this, LLMs' advanced capabilities in generating functional code, comprehending code context, and summarising its operations can also be leveraged for reverse engineering and malware deobfuscation. To this end, we delve into the deobfuscation capabilities of state-of-the-art LLMs. Beyond merely discussing a hypothetical scenario, we evaluate four LLMs with real-world malicious scripts used in the notorious Emotet malware campaign. Our results indicate that while not absolutely accurate yet, some LLMs can efficiently deobfuscate such payloads. Thus, fine-tuning LLMs for this task can be a viable potential for future AI-powered threat intelligence pipelines in the fight against obfuscated malware.
翻译:将大语言模型(LLM)集成到各类流程中的做法日益普遍,这有效自动化了许多人工任务,甚至常超越人类能力。网络安全研究人员与从业者已认识到这一潜力,鉴于需要处理大量异构数据以识别异常、潜在绕过手段、攻击及欺诈事件,他们正积极探索其应用场景。在此基础上,LLM在生成可运行代码、理解代码上下文及总结其操作方面的先进能力,也可被用于逆向工程和恶意软件反混淆。为此,我们深入研究了最新LLM的反混淆能力。不同于仅讨论假设场景,我们使用臭名昭著的Emotet恶意软件活动中的真实恶意脚本,对四种LLM进行了评估。结果表明,尽管尚未达到绝对精确,但部分LLM能够高效反混淆此类载荷。因此,针对该任务微调LLM,可为未来基于AI的威胁情报流程提供可行潜力,以对抗混淆型恶意软件。