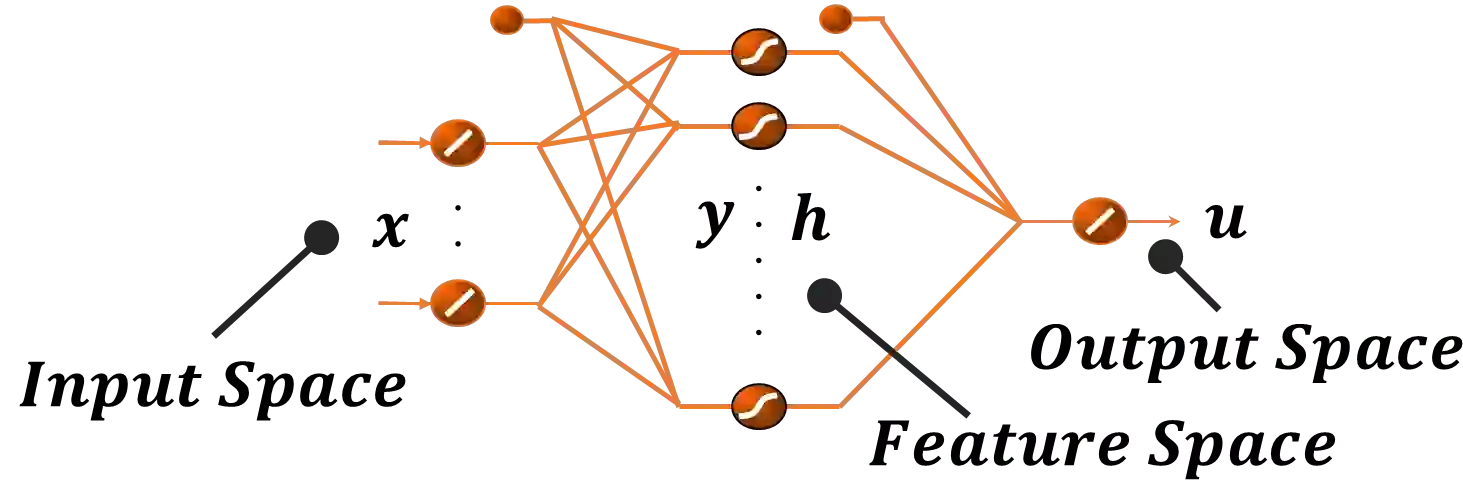
In this article an innovative method for training regressive MLP networks is presented, which is not subject to local minima. The Error-Back-Propagation algorithm, proposed by William-Hinton-Rummelhart, has had the merit of favouring the development of machine learning techniques, which has permeated every branch of research and technology since the mid-1980s. This extraordinary success is largely due to the black-box approach, but this same factor was also seen as a limitation, as soon more challenging problems were approached. One of the most critical aspects of the training algorithms was that of local minima of the loss function, typically the mean squared error of the output on the training set. In fact, as the most popular training algorithms are driven by the derivatives of the loss function, there is no possibility to evaluate if a reached minimum is local or global. The algorithm presented in this paper avoids the problem of local minima, as the training is based on the properties of the distribution of the training set, or better on its image internal to the neural network. The performance of the algorithm is shown for a well-known benchmark.
翻译:本文提出了一种创新的回归型多层感知器(MLP)网络训练方法,该方法不受局部极小值问题困扰。由William-Hinton-Rummelhart提出的误差反向传播算法,自20世纪80年代中期以来,因其推动了机器学习技术的发展而功不可没,这种技术已渗透到研究与技术的各个分支。这一非凡成功很大程度上归功于其黑箱方法,但当面对更具挑战性的问题时,同样的因素也成为了局限。训练算法中最关键的问题之一在于损失函数的局部极小值,通常指训练集上输出的均方误差。实际上,由于最流行的训练算法由损失函数的导数驱动,因此无法评估所达到的极小值是局部还是全局。本文提出的算法通过基于训练集分布特性(确切地说,是其内部在神经网络中的映像)进行训练,从而避免了局部极小值问题。文中通过一个著名基准测试展示了该算法的性能。