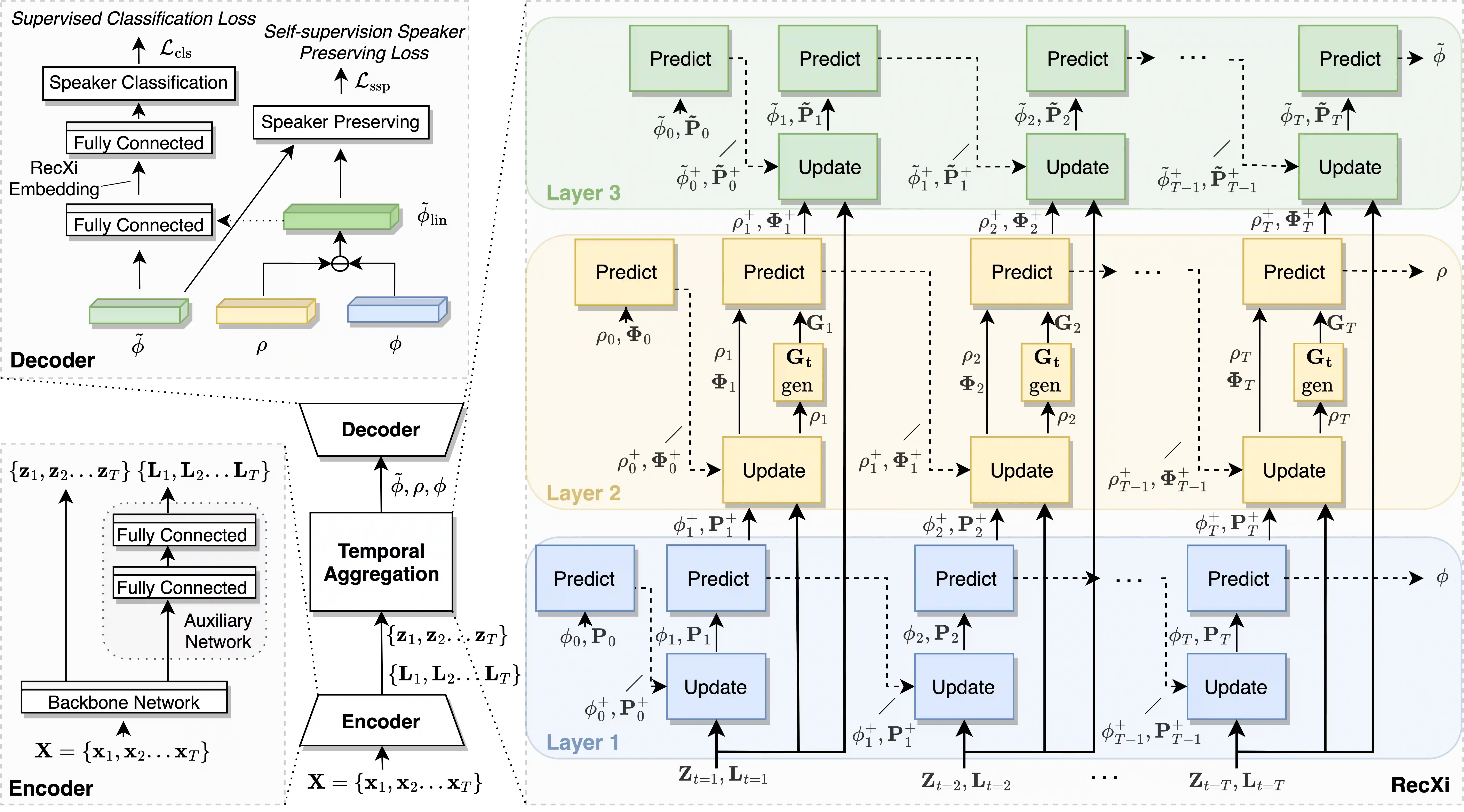
For speaker recognition, it is difficult to extract an accurate speaker representation from speech because of its mixture of speaker traits and content. This paper proposes a disentanglement framework that simultaneously models speaker traits and content variability in speech. It is realized with the use of three Gaussian inference layers, each consisting of a learnable transition model that extracts distinct speech components. Notably, a strengthened transition model is specifically designed to model complex speech dynamics. We also propose a self-supervision method to dynamically disentangle content without the use of labels other than speaker identities. The efficacy of the proposed framework is validated via experiments conducted on the VoxCeleb and SITW datasets with 9.56% and 8.24% average reductions in EER and minDCF, respectively. Since neither additional model training nor data is specifically needed, it is easily applicable in practical use.
翻译:在说话人识别任务中,由于语音中同时混合了说话人特征和内容信息,提取准确的说话人表征具有挑战性。本文提出一种解耦框架,能够同时对语音中的说话人特征与内容变化性进行建模。该框架通过三个高斯推理层实现,每个推理层包含一个可学习的转移模型以提取不同的语音成分。特别地,我们设计了一种增强型转移模型来专门建模复杂的语音动态特性。此外,我们提出一种自监督方法,在仅使用说话人身份标签而不依赖其他标注的条件下,动态解耦内容信息。在VoxCeleb和SITW数据集上的实验验证了该框架的有效性,其中等错误率(EER)和最小检测代价函数(minDCF)分别获得9.56%和8.24%的平均降幅。由于该方法无需额外模型训练或专用数据,可便捷地应用于实际场景。