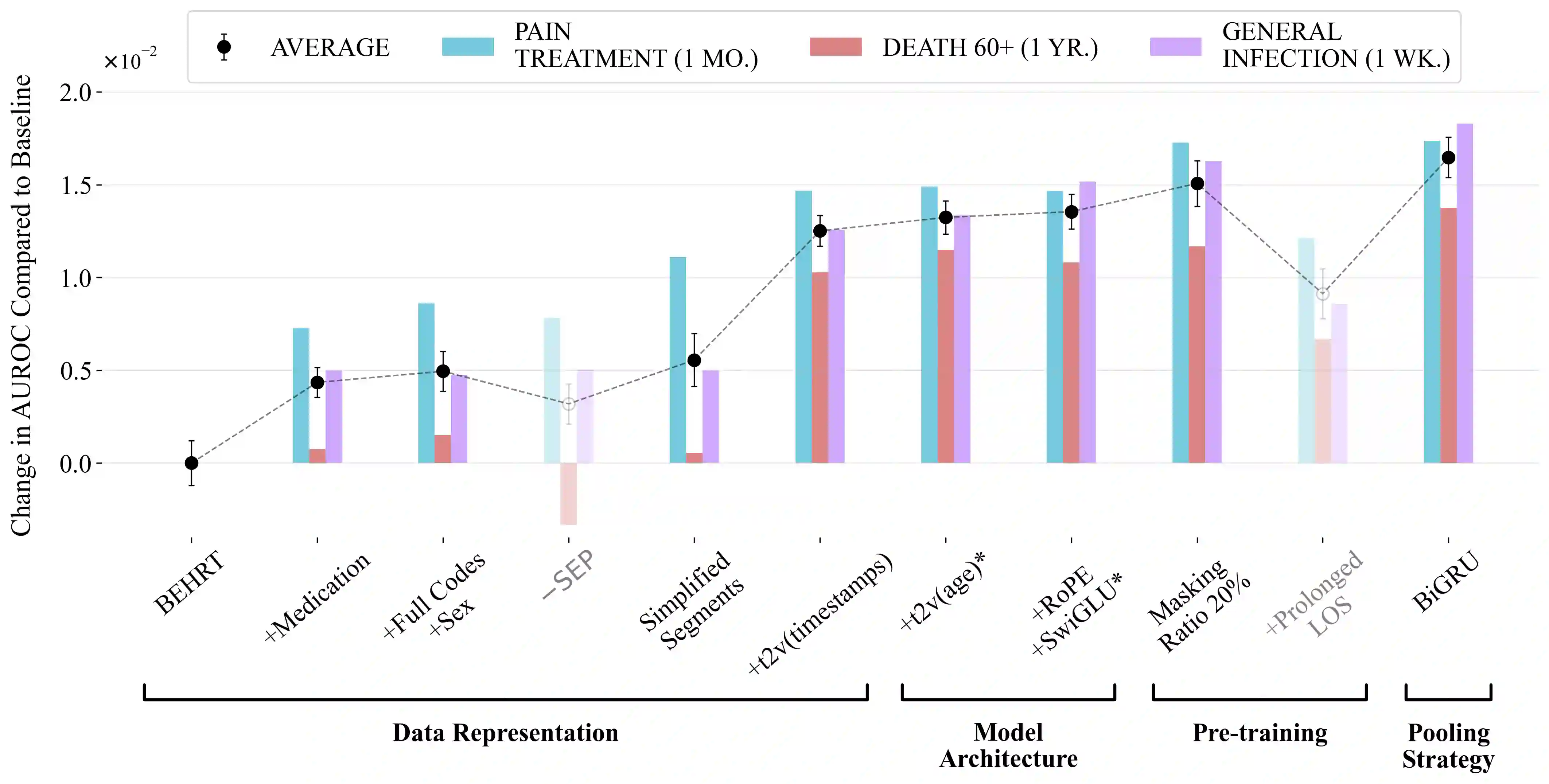
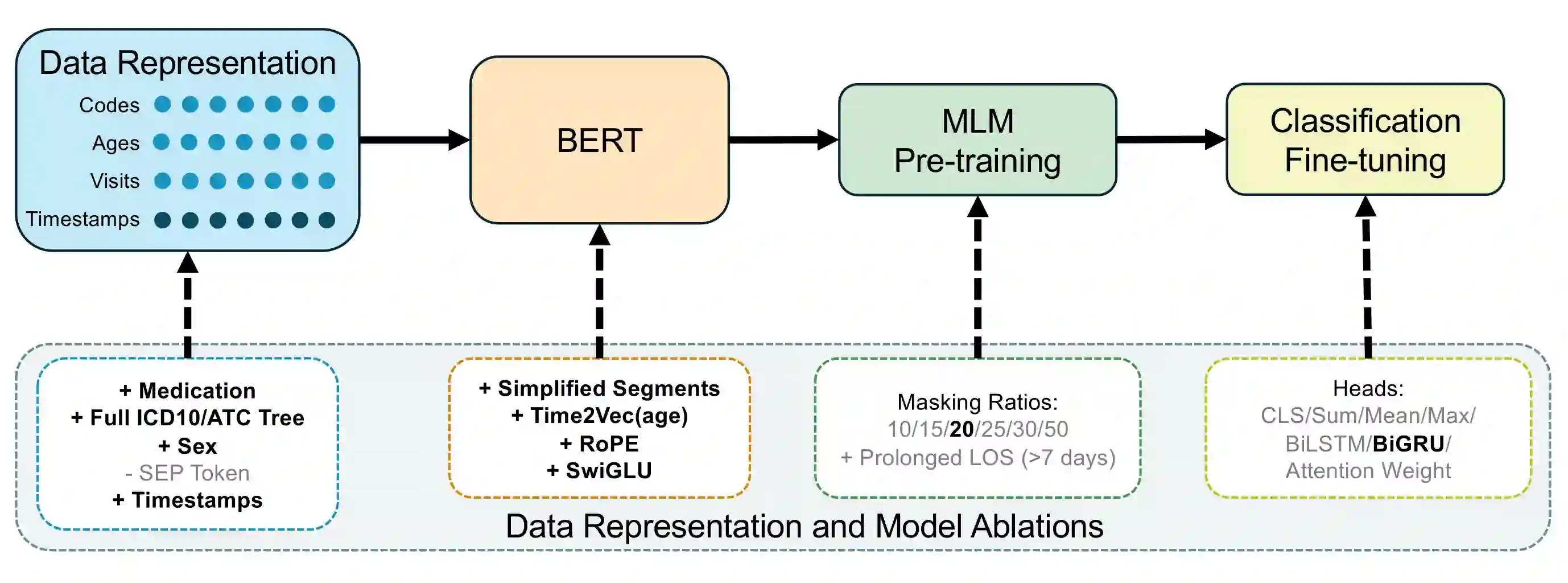
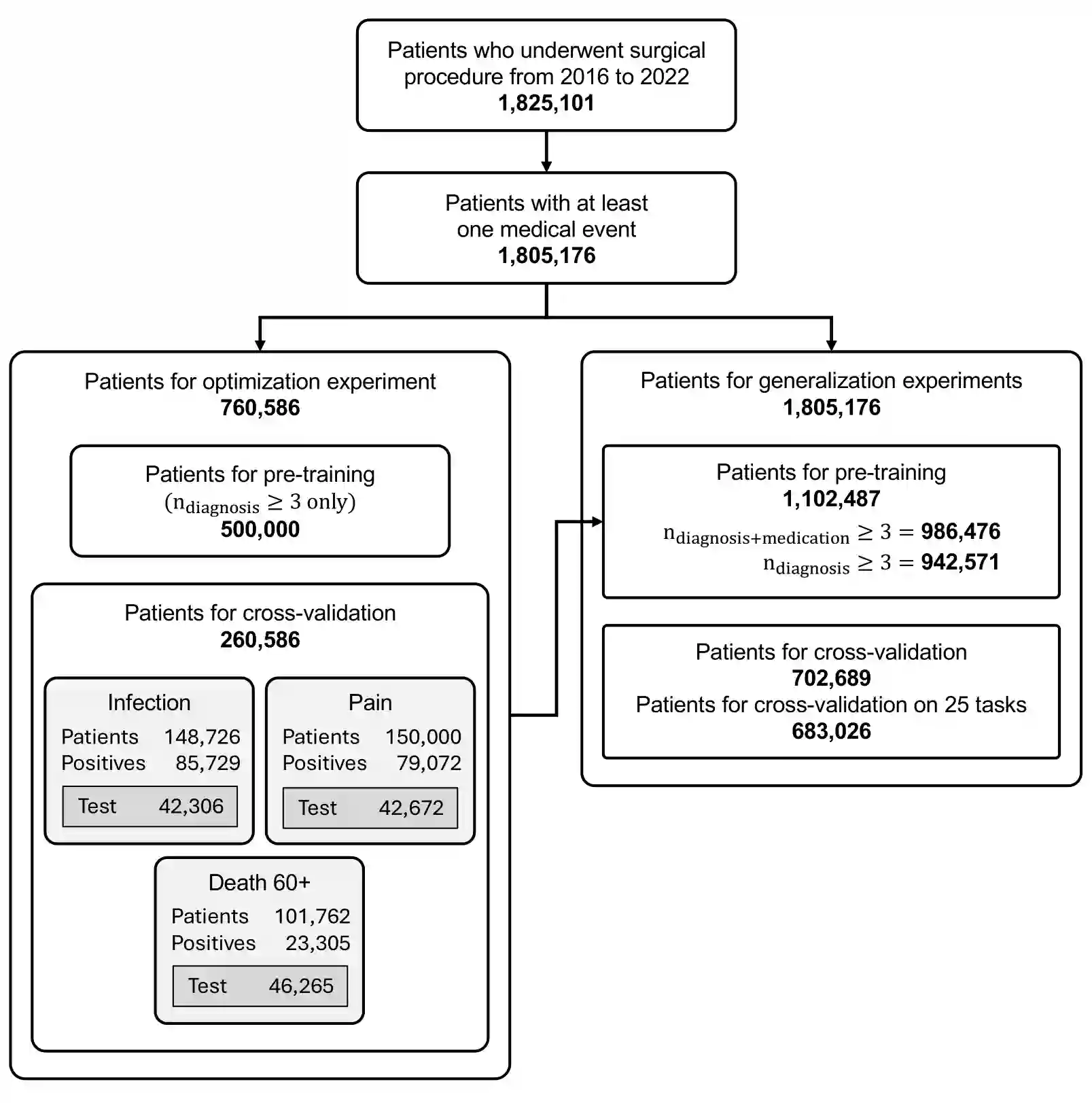
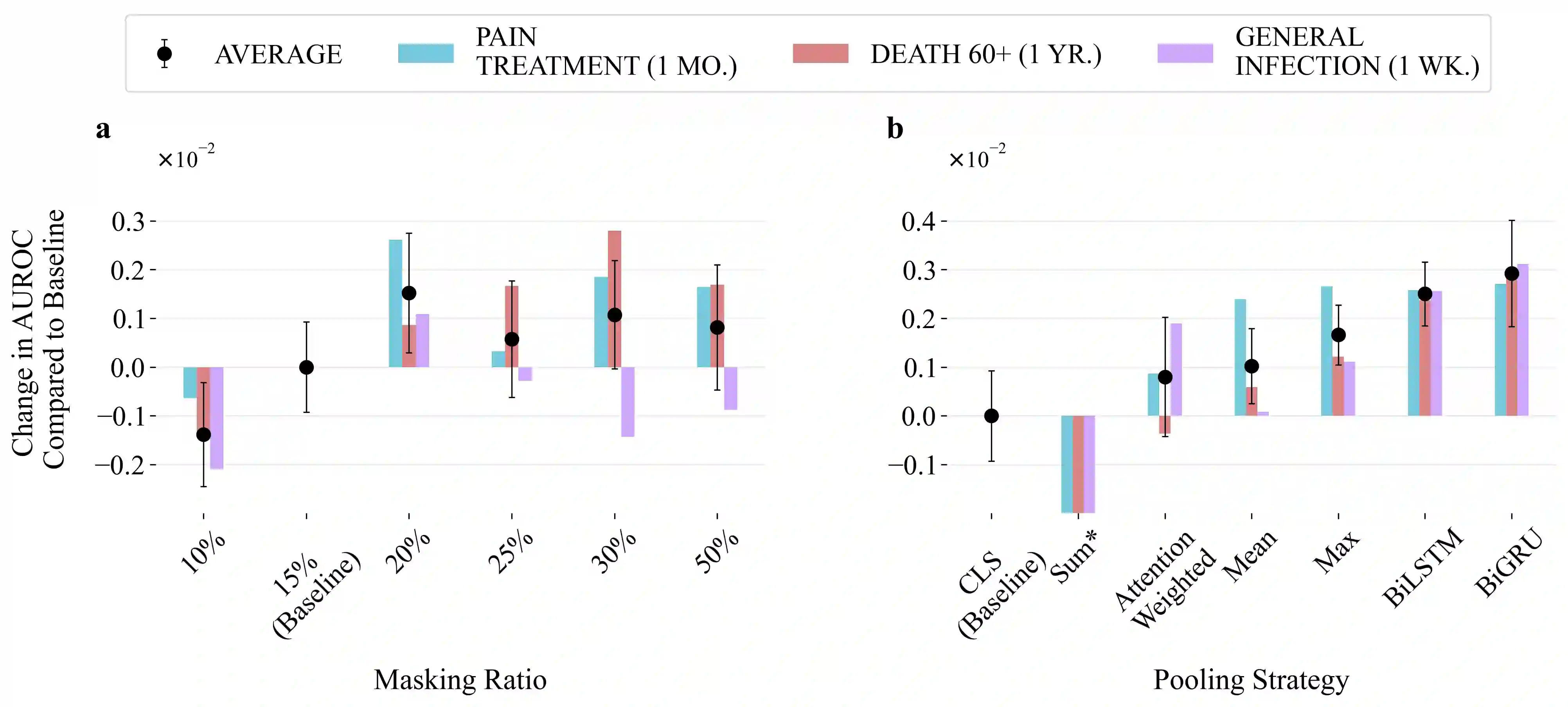
BERT-based models for Electronic Health Records (EHR) have surged in popularity following the release of BEHRT and Med-BERT. Subsequent models have largely built on these foundations despite the fundamental design choices of these pioneering models remaining underexplored. To address this issue, we introduce CORE-BEHRT, a Carefully Optimized and Rigorously Evaluated BEHRT. Through incremental optimization, we isolate the sources of improvement for key design choices, giving us insights into the effect of data representation and individual technical components on performance. Evaluating this across a set of generic tasks (death, pain treatment, and general infection), we showed that improving data representation can increase the average downstream performance from 0.785 to 0.797 AUROC, primarily when including medication and timestamps. Improving the architecture and training protocol on top of this increased average downstream performance to 0.801 AUROC. We then demonstrated the consistency of our optimization through a rigorous evaluation across 25 diverse clinical prediction tasks. We observed significant performance increases in 17 out of 25 tasks and improvements in 24 tasks, highlighting the generalizability of our findings. Our findings provide a strong foundation for future work and aim to increase the trustworthiness of BERT-based EHR models.
翻译:在BEHRT和Med-BERT发布之后,基于BERT的电子健康记录(EHR)模型迅速流行起来。尽管这些开创性模型的基本设计选择仍未得到充分探索,但后续模型大多建立在这些基础之上。为了解决这一问题,我们提出了CORE-BEHRT——一种经过精心优化和严谨评估的BEHRT模型。通过增量式优化,我们分离了关键设计选择带来的改进来源,从而深入理解数据表示和各个技术组件对性能的影响。在一组通用任务(死亡预测、疼痛治疗和通用感染预测)上的评估表明,改进数据表示可将平均下游性能从0.785 AUROC提升至0.797 AUROC,这主要归功于加入了药物和时间戳信息。在此基础之上优化架构和训练方案后,平均下游性能进一步提升至0.801 AUROC。随后,我们通过涵盖25项不同临床预测任务的严谨评估,验证了优化的稳定性。我们发现,在25项任务中有17项任务的性能显著提升,且24项任务均有所改进,这凸显了我们发现的可推广性。本研究为未来工作奠定了坚实基础,并致力于提高基于BERT的EHR模型的可信度。