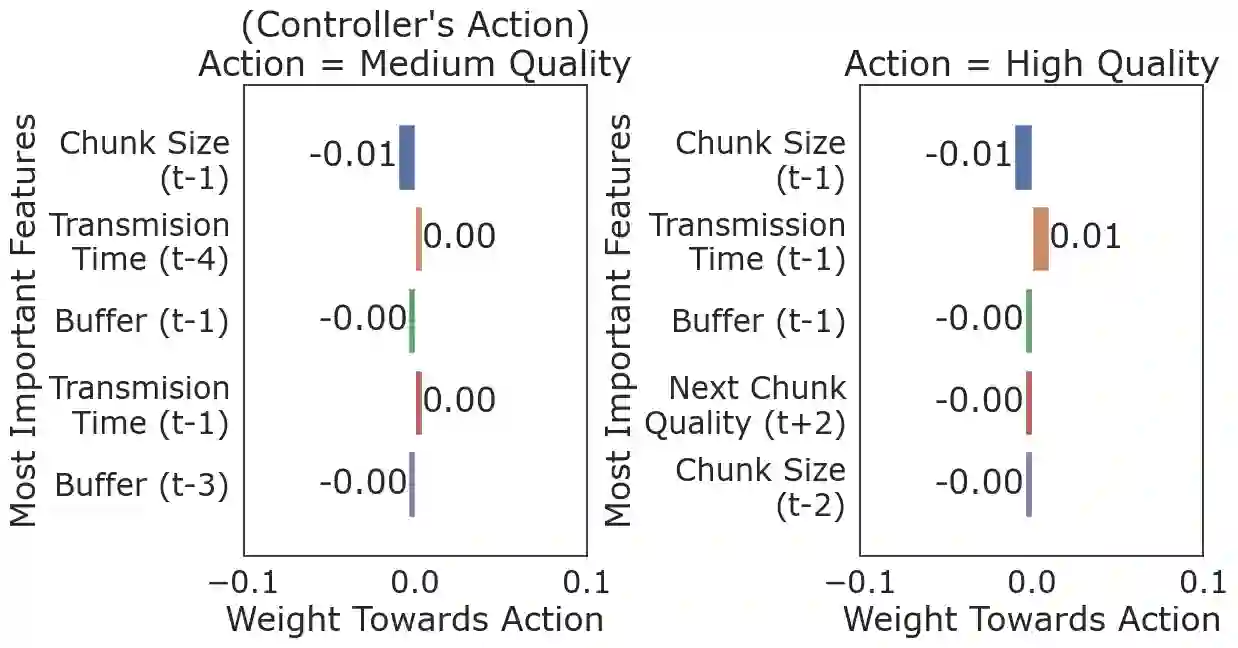
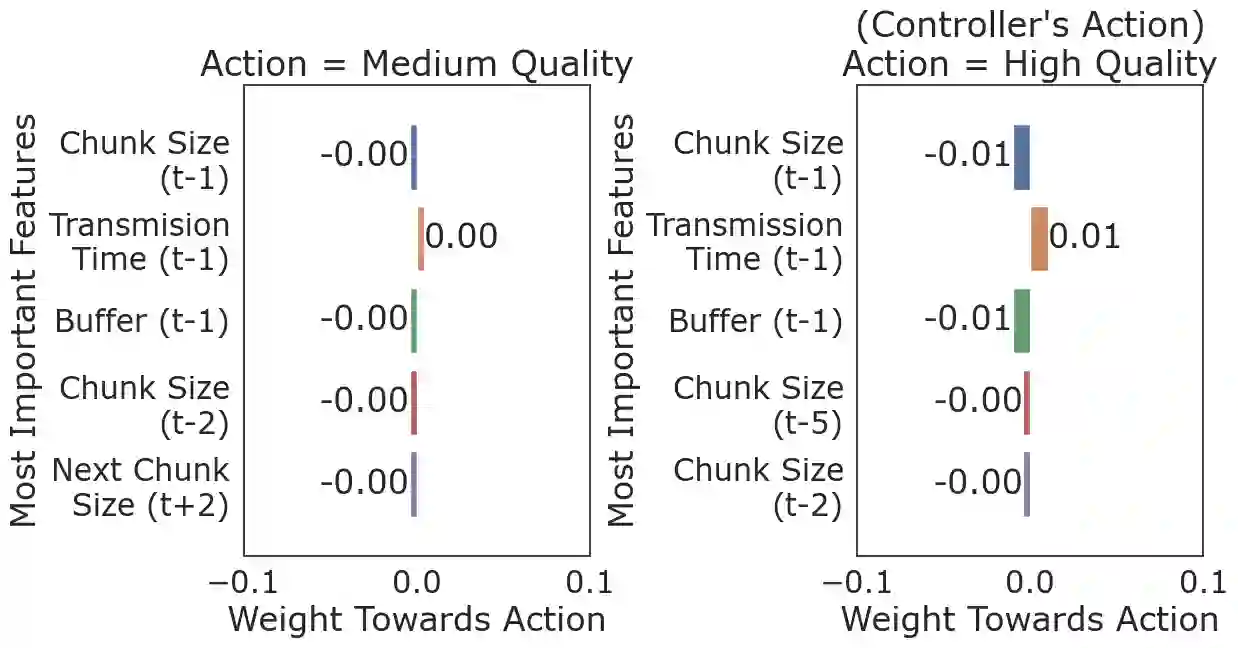
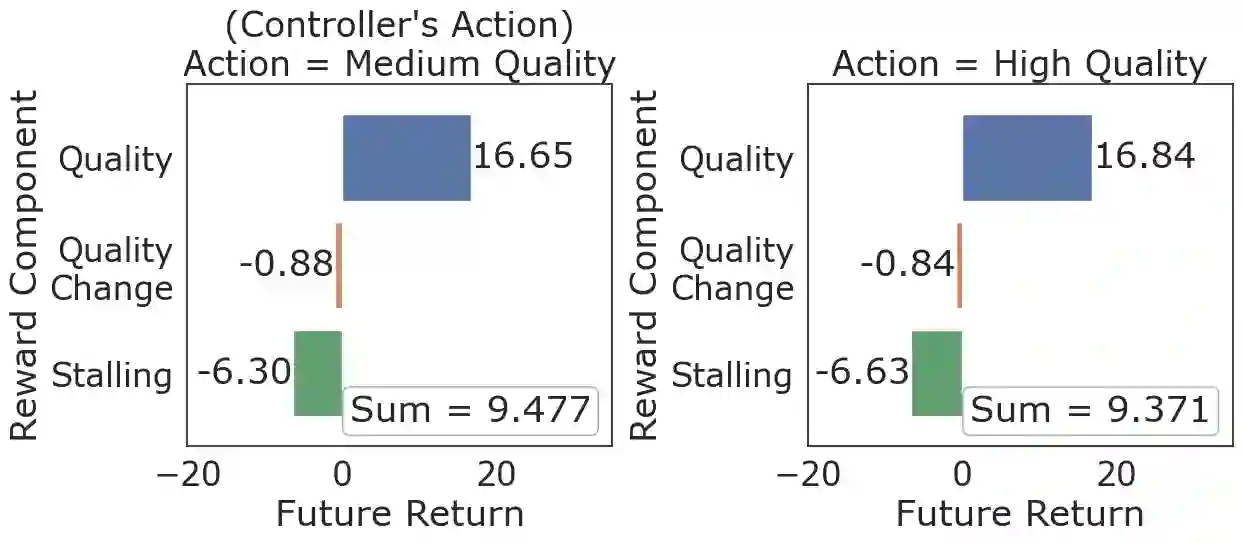
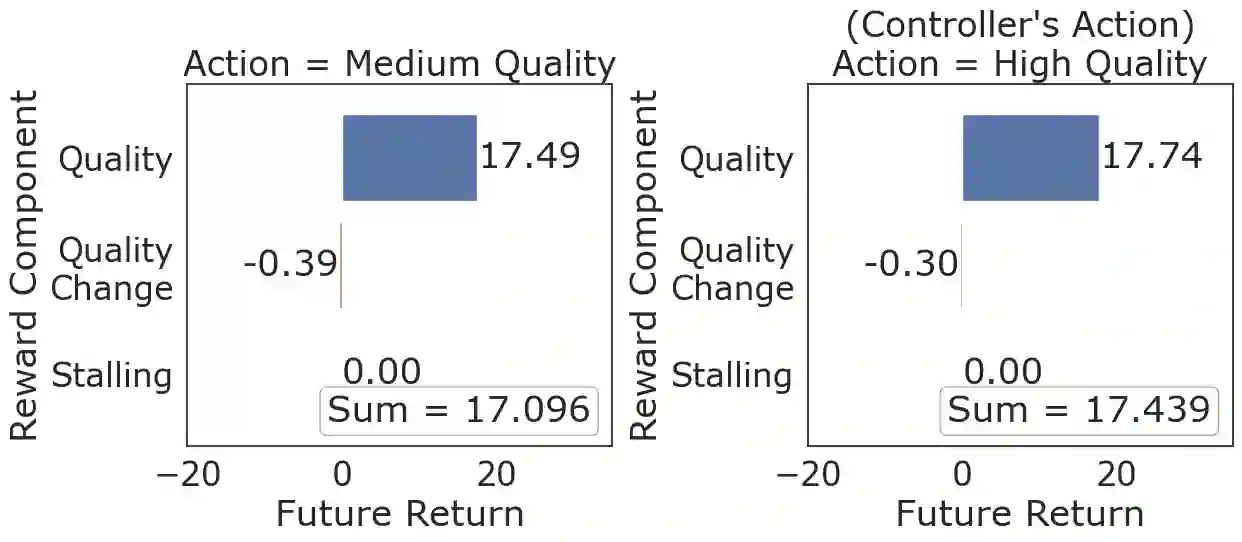
We present CrystalBox, a novel, model-agnostic, posthoc explainability framework for Deep Reinforcement Learning (DRL) controllers in the large family of input-driven environments which includes computer systems. We combine the natural decomposability of reward functions in input-driven environments with the explanatory power of decomposed returns. We propose an efficient algorithm to generate future-based explanations across both discrete and continuous control environments. Using applications such as adaptive bitrate streaming and congestion control, we demonstrate CrystalBox's capability to generate high-fidelity explanations. We further illustrate its higher utility across three practical use cases: contrastive explanations, network observability, and guided reward design, as opposed to prior explainability techniques that identify salient features.
翻译:我们提出CrystalBox,一种新颖的、模型无关的事后可解释性框架,适用于包含计算机系统在内的输入驱动环境大家族中的深度强化学习控制器。我们将输入驱动环境中奖励函数的自然可分解性与分解回报的解释能力相结合,并提出一种高效算法,可在离散和连续控制环境中生成基于未来的解释。通过自适应比特率流和拥塞控制等应用,我们证明了CrystalBox生成高保真解释的能力。进一步地,相比于先前识别显著特征的可解释性技术,我们在对比解释、网络可观测性和引导奖励设计三个实际用例中展示了CrystalBox的更高实用性。