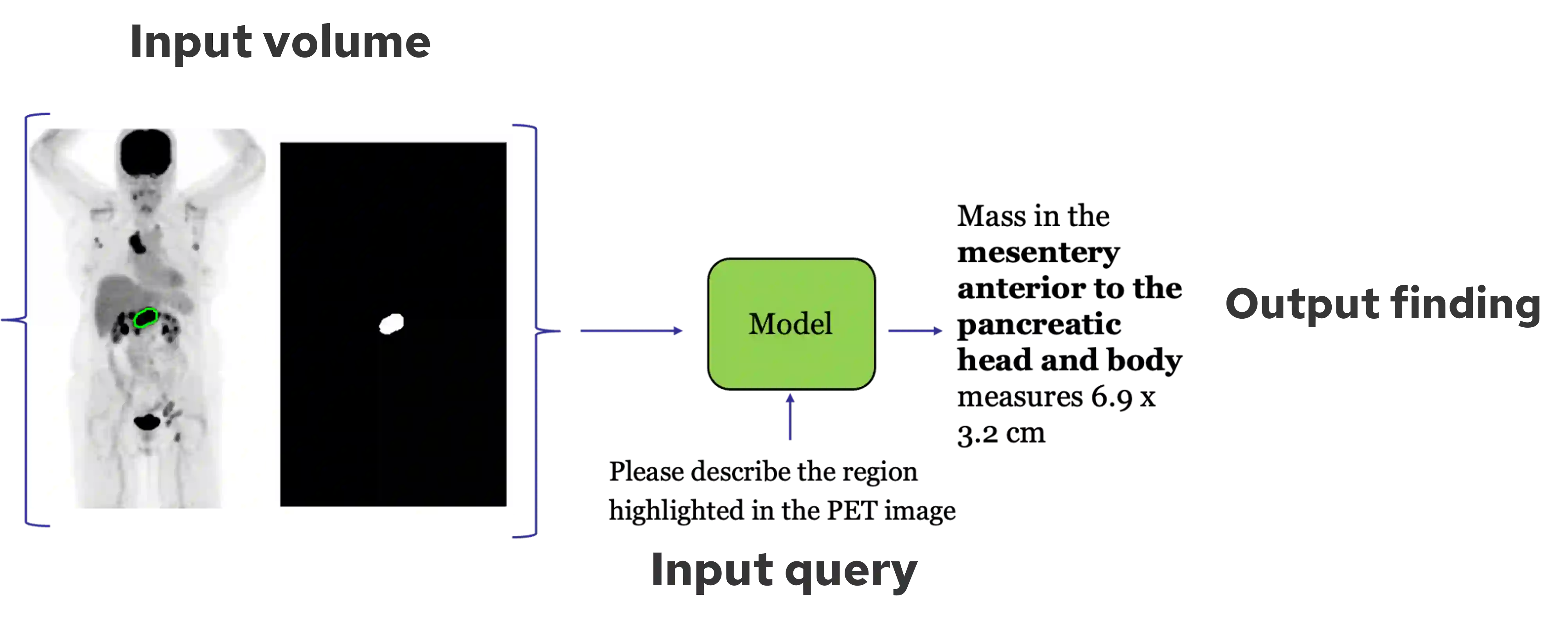
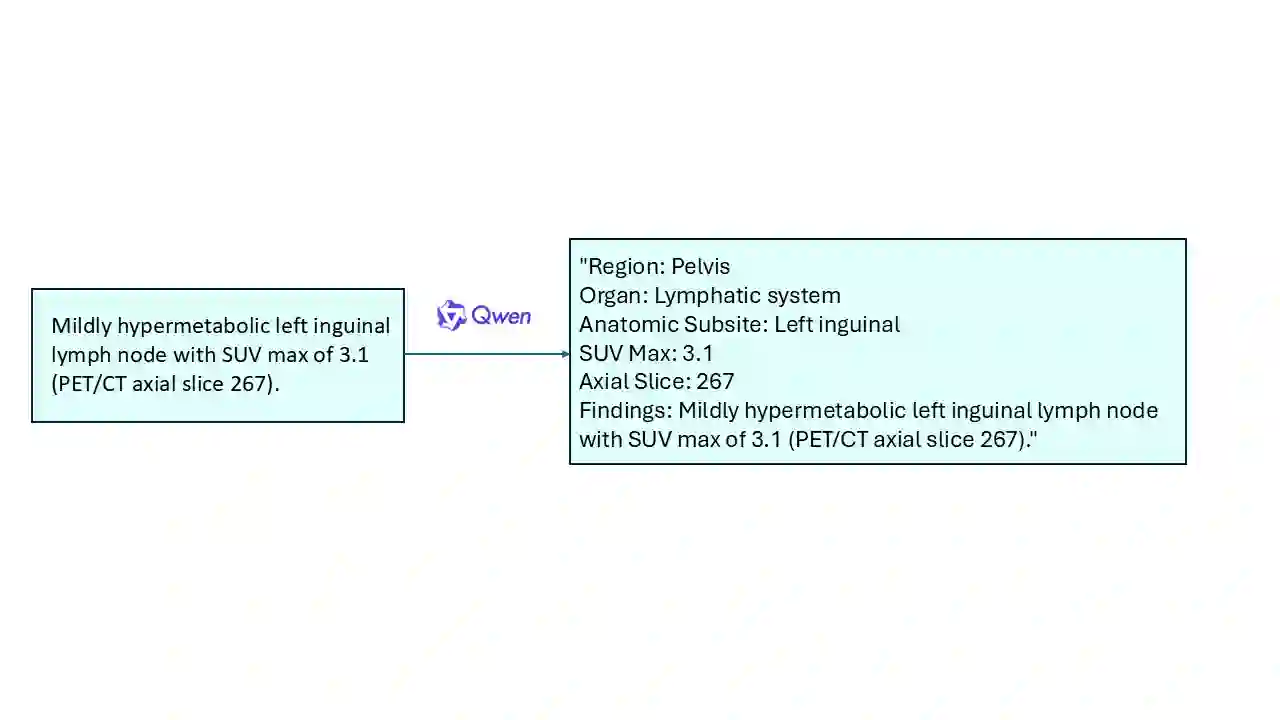
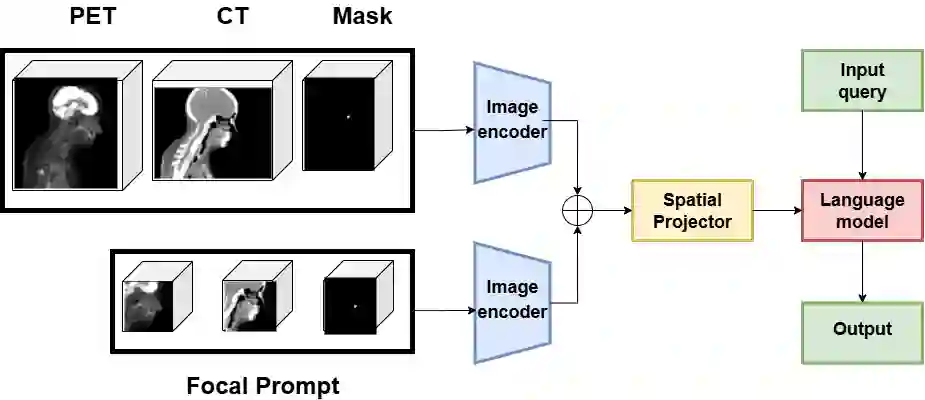
Recent advances in vision-language models (VLMs) have enabled impressive multimodal reasoning, yet most medical applications remain limited to 2D imaging. In this work, we extend VLMs to 3D positron emission tomography and computed tomography (PET/CT), a domain characterized by large volumetric data, small and dispersed lesions, and lengthy radiology reports. We introduce a large-scale dataset comprising over 11,000 lesion-level descriptions paired with 3D segmentations from more than 5,000 PET/CT exams, extracted via a hybrid rule-based and large language model (LLM) pipeline. Building upon this dataset, we propose PETAR-4B, a 3D mask-aware vision-language model that integrates PET, CT, and lesion contours for spatially grounded report generation. PETAR bridges global contextual reasoning with fine-grained lesion awareness, producing clinically coherent and localized findings. Comprehensive automated and human evaluations demonstrate that PETAR substantially improves PET/CT report generation quality, advancing 3D medical vision-language understanding.
翻译:近期视觉语言模型(VLMs)的进展已实现卓越的多模态推理能力,但大多数医学应用仍局限于二维成像。本研究将VLMs扩展至三维正电子发射断层扫描与计算机断层扫描(PET/CT)领域,该领域具有大体积数据、小而分散的病灶以及冗长放射学报告的特点。我们引入了一个大规模数据集,包含超过11,000个病灶级描述与来自5,000余次PET/CT检查的三维分割结果,这些数据通过基于规则的混合流程与大型语言模型(LLM)流水线提取。基于此数据集,我们提出PETAR-4B——一个三维掩码感知视觉语言模型,它整合了PET、CT及病灶轮廓信息,实现空间锚定的报告生成。PETAR通过融合全局上下文推理与细粒度病灶感知,生成临床连贯且定位明确的发现。综合自动化与人工评估表明,PETAR显著提升了PET/CT报告生成质量,推动了三维医学视觉语言理解的发展。