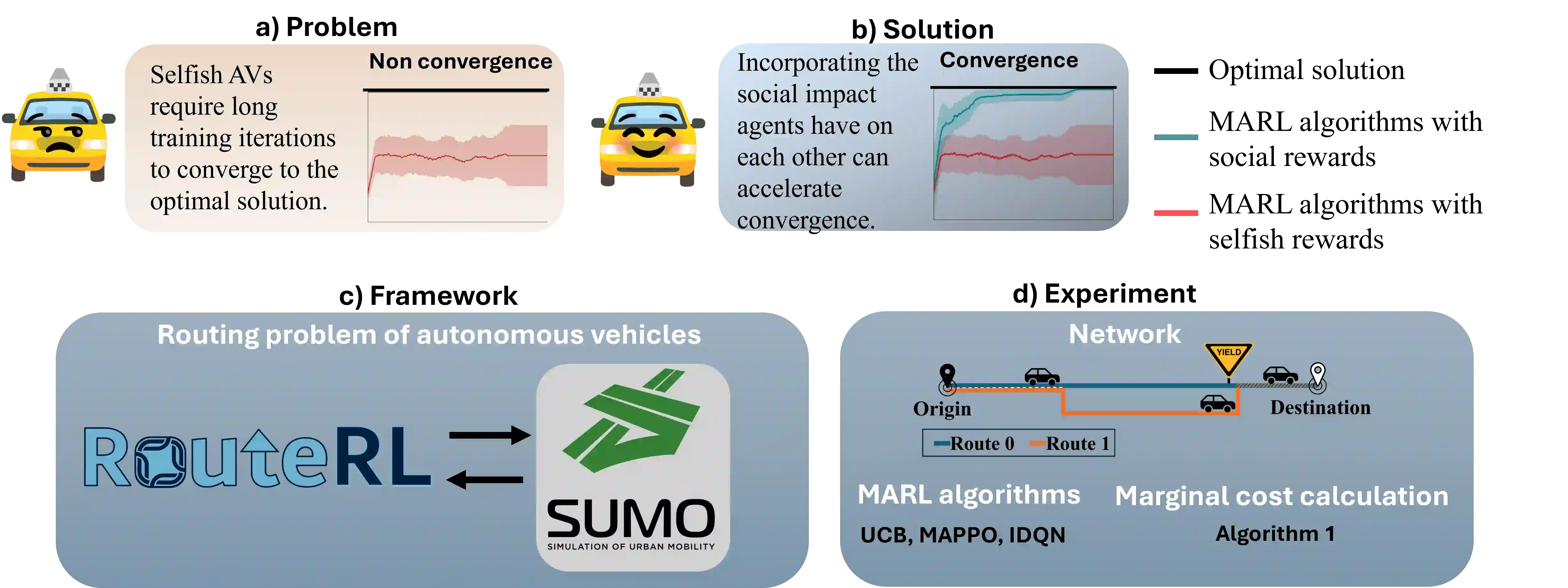
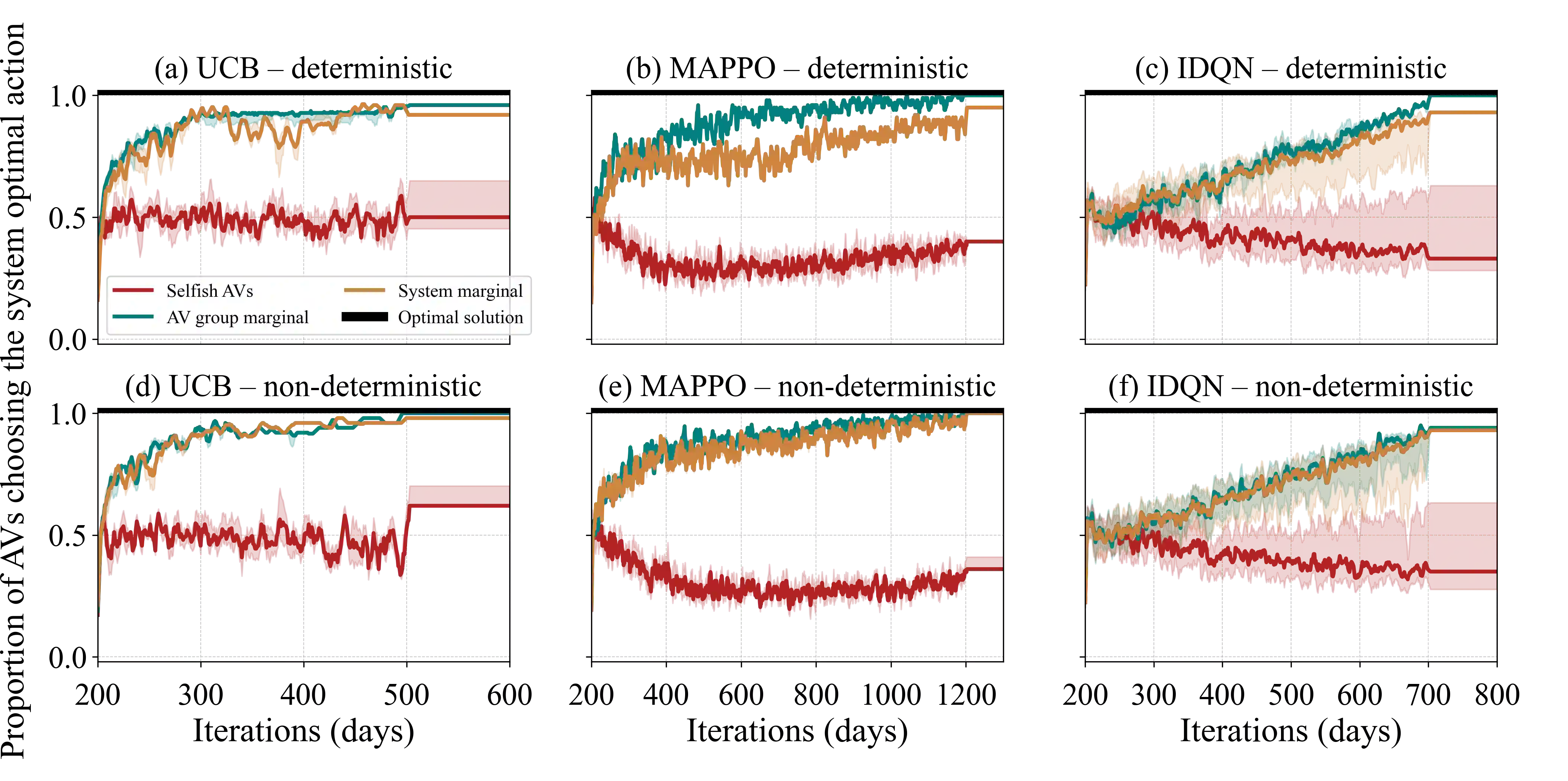
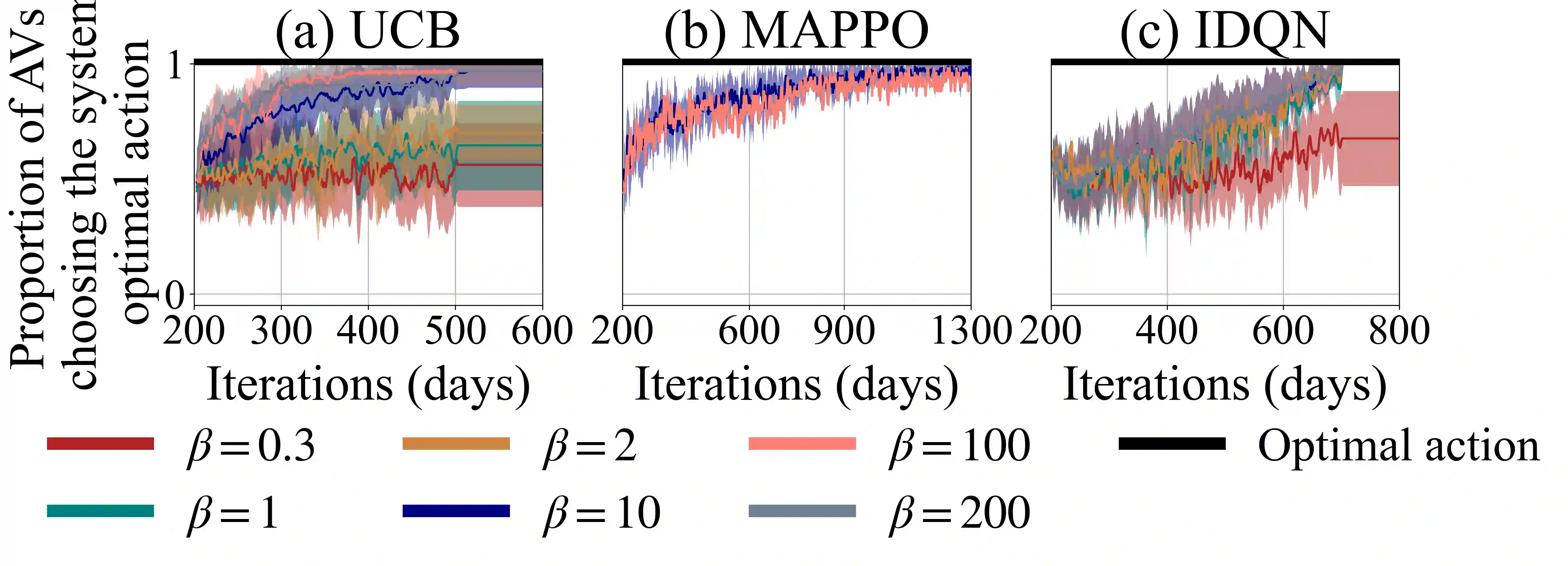
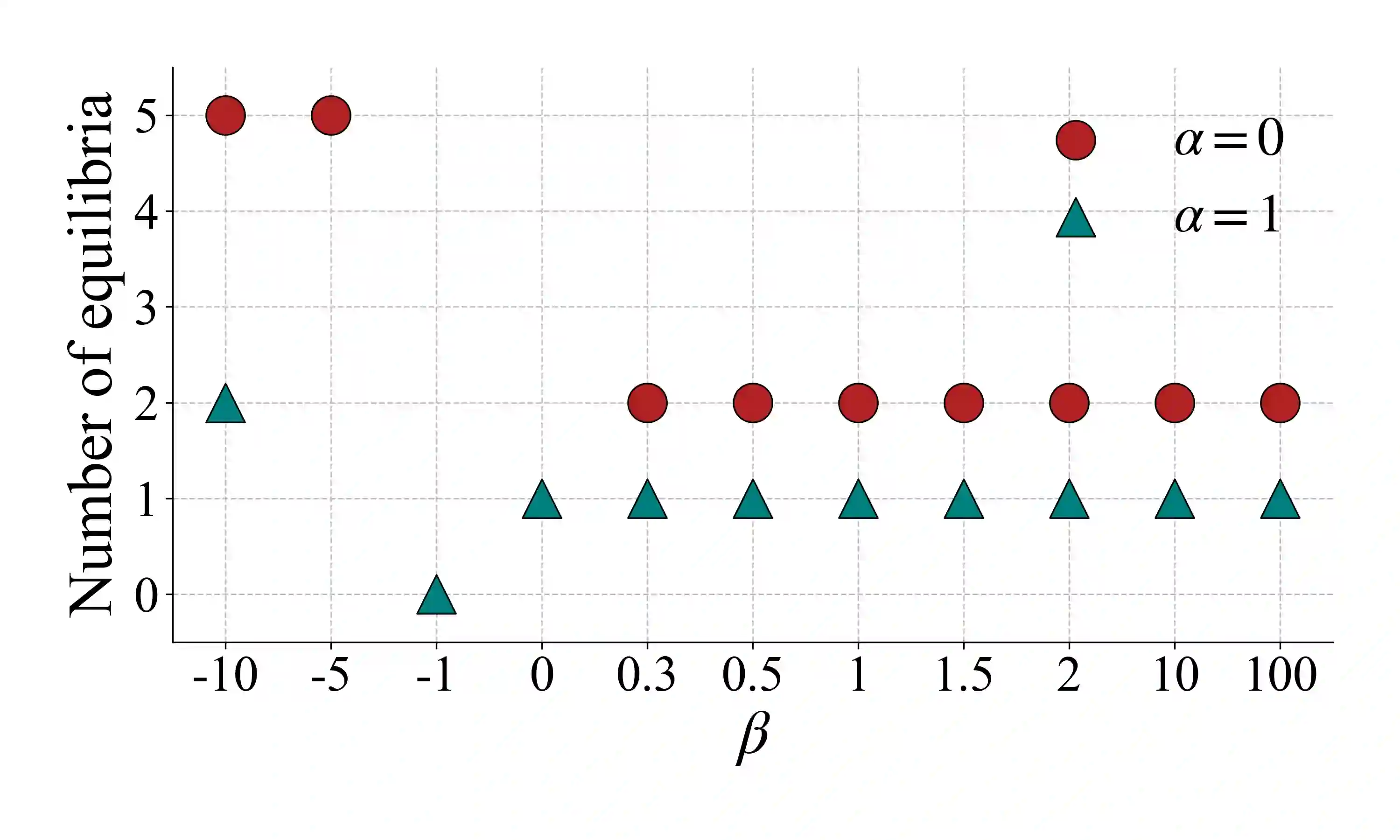
Previous work has shown that when multiple selfish Autonomous Vehicles (AVs) are introduced to future cities and start learning optimal routing strategies using Multi-Agent Reinforcement Learning (MARL), they may destabilize traffic systems, as they would require a significant amount of time to converge to the optimal solution, equivalent to years of real-world commuting. We demonstrate that moving beyond the selfish component in the reward significantly relieves this issue. If each AV, apart from minimizing its own travel time, aims to reduce its impact on the system, this will be beneficial not only for the system-wide performance but also for each individual player in this routing game. By introducing an intrinsic reward signal based on the marginal cost matrix, we significantly reduce training time and achieve convergence more reliably. Marginal cost quantifies the impact of each individual action (route-choice) on the system (total travel time). Including it as one of the components of the reward can reduce the degree of non-stationarity by aligning agents' objectives. Notably, the proposed counterfactual formulation preserves the system's equilibria and avoids oscillations. Our experiments show that training MARL algorithms with our novel reward formulation enables the agents to converge to the optimal solution, whereas the baseline algorithms fail to do so. We show these effects in both a toy network and the real-world network of Saint-Arnoult. Our results optimistically indicate that social awareness (i.e., including marginal costs in routing decisions) improves both the system-wide and individual performance of future urban systems with AVs.
翻译:先前的研究表明,当多个自私的自动驾驶车辆(AVs)被引入未来城市并开始使用多智能体强化学习(MARL)学习最优路由策略时,它们可能会破坏交通系统的稳定性,因为这些车辆需要大量时间才能收敛到最优解,这相当于现实世界通勤中的数年时间。我们证明,在奖励函数中超越自私成分能显著缓解这一问题。如果每辆自动驾驶车辆除了最小化自身行程时间外,还致力于减少其对系统的影响,这不仅有利于系统整体性能,对此路由博弈中的每个个体参与者也是有益的。通过引入基于边际成本矩阵的内在奖励信号,我们显著减少了训练时间并更可靠地实现了收敛。边际成本量化了每个个体行动(路径选择)对系统(总行程时间)的影响。将其作为奖励的组成部分之一,可以通过对齐智能体的目标来降低非平稳性的程度。值得注意的是,所提出的反事实公式保持了系统的均衡并避免了振荡。我们的实验表明,使用我们新颖的奖励公式训练MARL算法能使智能体收敛到最优解,而基线算法则无法做到这一点。我们在一个玩具网络和Saint-Arnoult的真实世界网络中展示了这些效果。我们的结果乐观地表明,社会意识(即在路由决策中考虑边际成本)能同时改善未来配备自动驾驶车辆的城市系统的整体性能和个体性能。