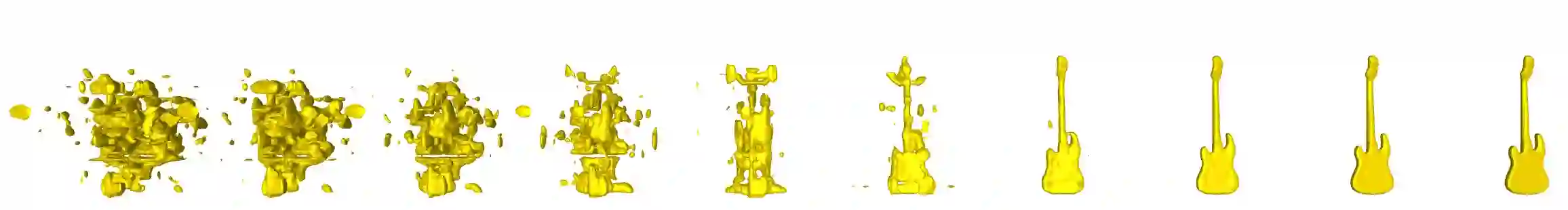We present a novel alignment-before-generation approach to tackle the challenging task of generating general 3D shapes based on 2D images or texts. Directly learning a conditional generative model from images or texts to 3D shapes is prone to producing inconsistent results with the conditions because 3D shapes have an additional dimension whose distribution significantly differs from that of 2D images and texts. To bridge the domain gap among the three modalities and facilitate multi-modal-conditioned 3D shape generation, we explore representing 3D shapes in a shape-image-text-aligned space. Our framework comprises two models: a Shape-Image-Text-Aligned Variational Auto-Encoder (SITA-VAE) and a conditional Aligned Shape Latent Diffusion Model (ASLDM). The former model encodes the 3D shapes into the shape latent space aligned to the image and text and reconstructs the fine-grained 3D neural fields corresponding to given shape embeddings via the transformer-based decoder. The latter model learns a probabilistic mapping function from the image or text space to the latent shape space. Our extensive experiments demonstrate that our proposed approach can generate higher-quality and more diverse 3D shapes that better semantically conform to the visual or textural conditional inputs, validating the effectiveness of the shape-image-text-aligned space for cross-modality 3D shape generation.
翻译:我们提出了一种新颖的“先对齐后生成”方法,以应对基于二维图像或文本生成通用三维形状这一具有挑战性的任务。若直接从图像或文本学习条件式生成模型来生成三维形状,易产生与条件不一致的结果,因为三维形状具有额外维度,其分布与二维图像和文本存在显著差异。为弥合三种模态间的领域差异并促进多模态条件式三维形状生成,我们探索了在形状-图像-文本对齐空间中表征三维形状。我们的框架由两个模型组成:形状-图像-文本对齐变分自编码器(SITA-VAE)与条件式对齐形状潜在扩散模型(ASLDM)。前者将三维形状编码至与图像和文本对齐的潜在空间中,并通过基于Transformer的解码器重建与给定形状嵌入对应的细粒度三维神经场;后者学习从图像或文本空间到潜在形状空间的概率映射函数。大量实验表明,我们的方法能生成更高质量、更多样化的三维形状,且在语义上更好符合视觉或文本条件输入,验证了形状-图像-文本对齐空间在跨模态三维形状生成中的有效性。