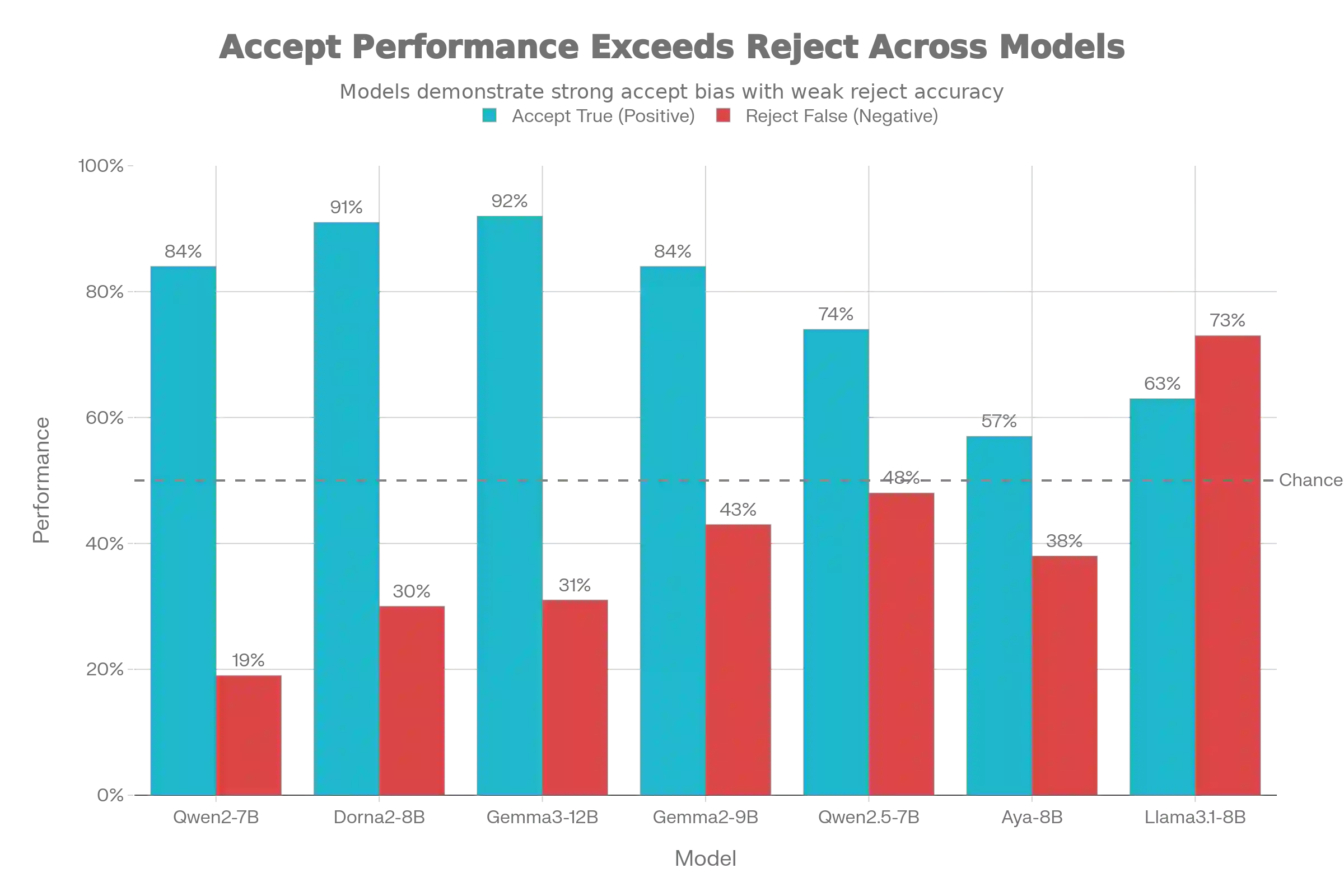
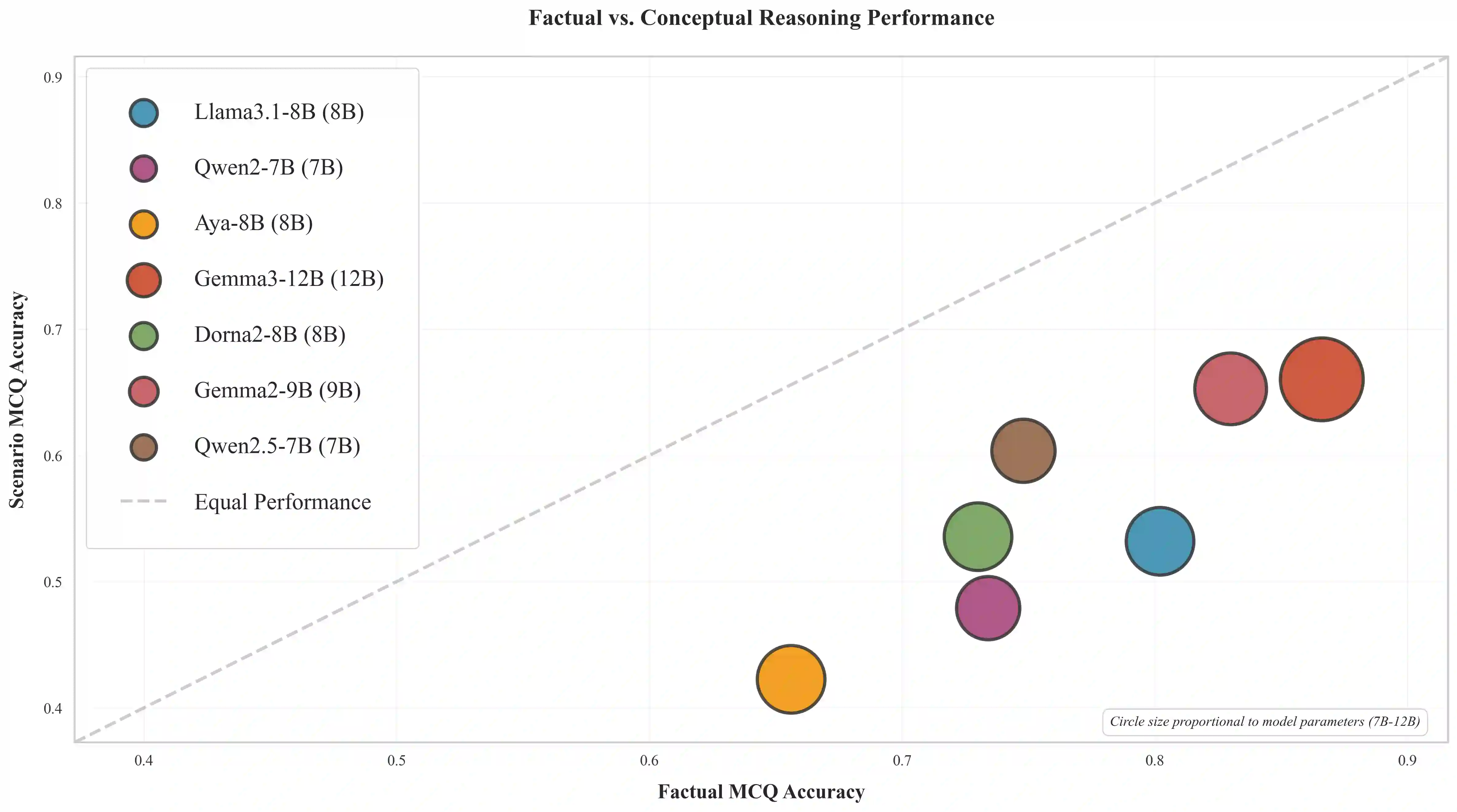
While emerging Persian NLP benchmarks have expanded into pragmatics and politeness, they rarely distinguish between memorized cultural facts and the ability to reason about implicit social norms. We introduce DivanBench, a diagnostic benchmark focused on superstitions and customs, arbitrary, context-dependent rules that resist simple logical deduction. Through 315 questions across three task types (factual retrieval, paired scenario verification, and situational reasoning), we evaluate seven Persian LLMs and reveal three critical failures: most models exhibit severe acquiescence bias, correctly identifying appropriate behaviors but failing to reject clear violations; continuous Persian pretraining amplifies this bias rather than improving reasoning, often degrading the model's ability to discern contradictions; and all models show a 21\% performance gap between retrieving factual knowledge and applying it in scenarios. These findings demonstrate that cultural competence requires more than scaling monolingual data, as current models learn to mimic cultural patterns without internalizing the underlying schemas.
翻译:尽管新兴的波斯语自然语言处理基准已扩展至语用学和礼貌性研究领域,但它们很少能区分记忆性文化事实与推理隐含社会规范的能力。本文提出DivanBench——一个专注于迷信与习俗的诊断性基准,这些任意且依赖情境的规则难以通过简单逻辑推演解决。通过涵盖三种任务类型(事实检索、配对情境验证及情境推理)的315道问题,我们对七款波斯语大语言模型进行评估,并揭示出三个关键缺陷:多数模型表现出严重的默许偏差,能够正确识别恰当行为却无法拒绝明显的违规情形;持续的波斯语预训练非但未能提升推理能力,反而放大了这种偏差,常常削弱模型识别矛盾的能力;所有模型在检索事实性知识与在情境中应用该知识之间均存在21%的性能差距。这些发现表明,文化能力所需的不只是单语数据的规模扩展,因为当前模型仅学会模仿文化模式,而未能内化其底层认知图式。