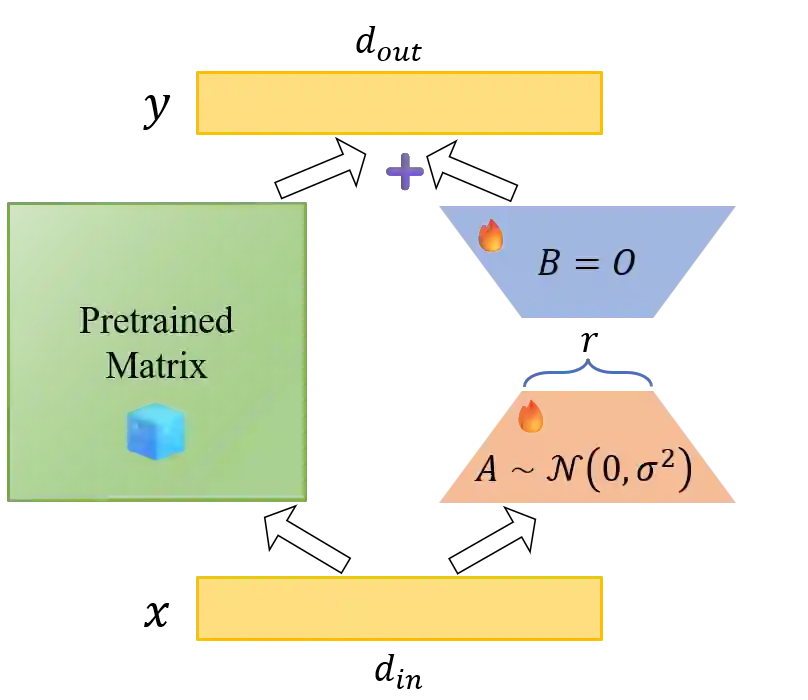
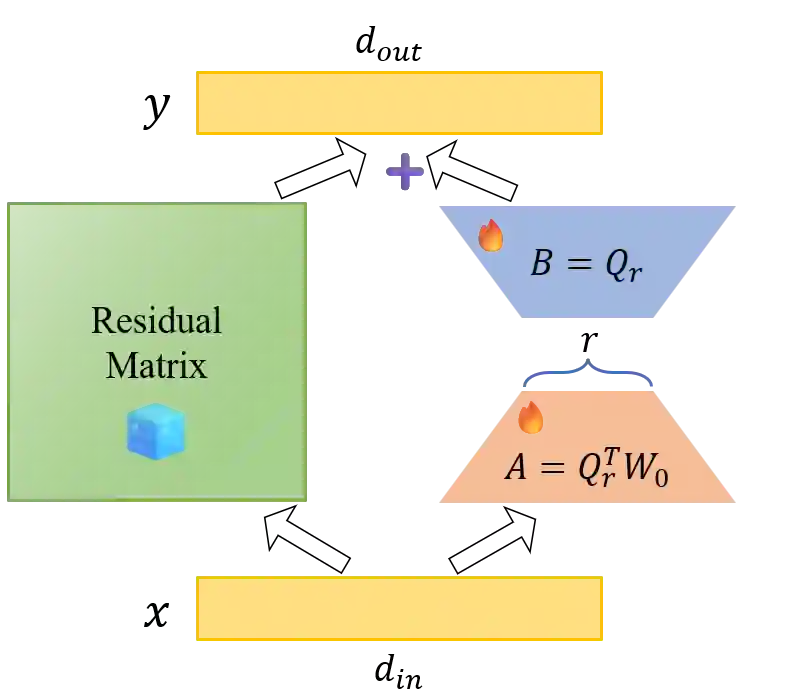
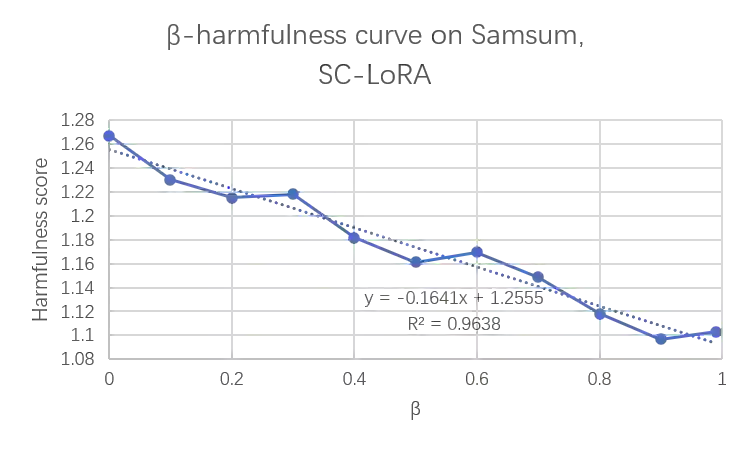
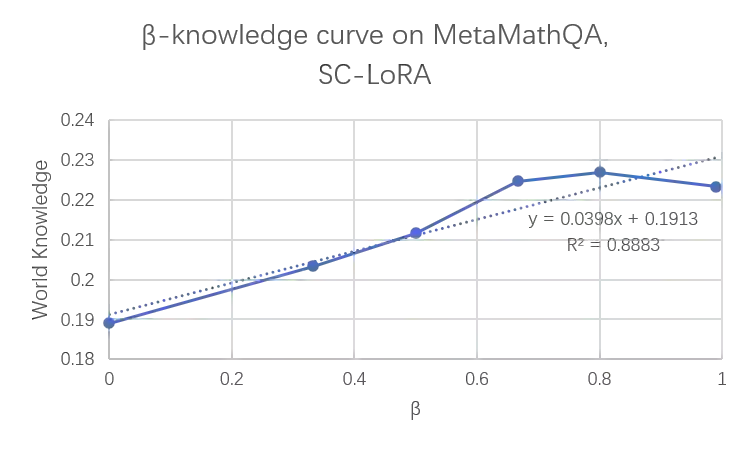
Parameter-Efficient Fine-Tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), are indispensable for efficiently customizing Large Language Models (LLMs). However, vanilla LoRA suffers from slow convergence speed and knowledge forgetting problems. Recent studies have leveraged the power of designed LoRA initialization, to enhance the fine-tuning efficiency, or to preserve knowledge in the pre-trained LLM. However, none of these works can address the two cases at the same time. To this end, we introduce Subspace-Constrained LoRA (SC-LoRA), a novel LoRA initialization framework engineered to navigate the trade-off between efficient fine-tuning and knowledge preservation. We achieve this by constraining the output of trainable LoRA adapters in a low-rank subspace, where the context information of fine-tuning data is most preserved while the context information of preserved knowledge is least retained, in a balanced way. Such constraint enables the trainable weights to primarily focus on the main features of fine-tuning data while avoiding damaging the preserved knowledge features. We provide theoretical analysis on our method, and conduct extensive experiments including safety preservation and world knowledge preservation, on various downstream tasks. In our experiments, SC-LoRA succeeds in delivering superior fine-tuning performance while markedly diminishing knowledge forgetting, surpassing contemporary LoRA initialization methods.
翻译:参数高效微调方法,特别是低秩适应,对于高效定制大型语言模型至关重要。然而,原始LoRA存在收敛速度慢和知识遗忘问题。近期研究通过设计LoRA初始化策略来提升微调效率或保留预训练模型中的知识,但现有工作均无法同时解决这两方面问题。为此,我们提出子空间约束LoRA,这是一种新颖的LoRA初始化框架,旨在权衡高效微调与知识保留。我们通过将可训练LoRA适配器的输出约束在低秩子空间内实现这一目标,该子空间以平衡方式最大程度保留微调数据的上下文信息,同时最小程度保留待保护知识的上下文信息。这种约束使可训练权重主要聚焦于微调数据的核心特征,同时避免破坏待保护知识特征。我们提供了该方法的理论分析,并在包括安全知识保留和世界知识保留在内的多种下游任务上进行了广泛实验。实验表明,SC-LoRA在显著减少知识遗忘的同时实现了更优的微调性能,超越了当前主流LoRA初始化方法。