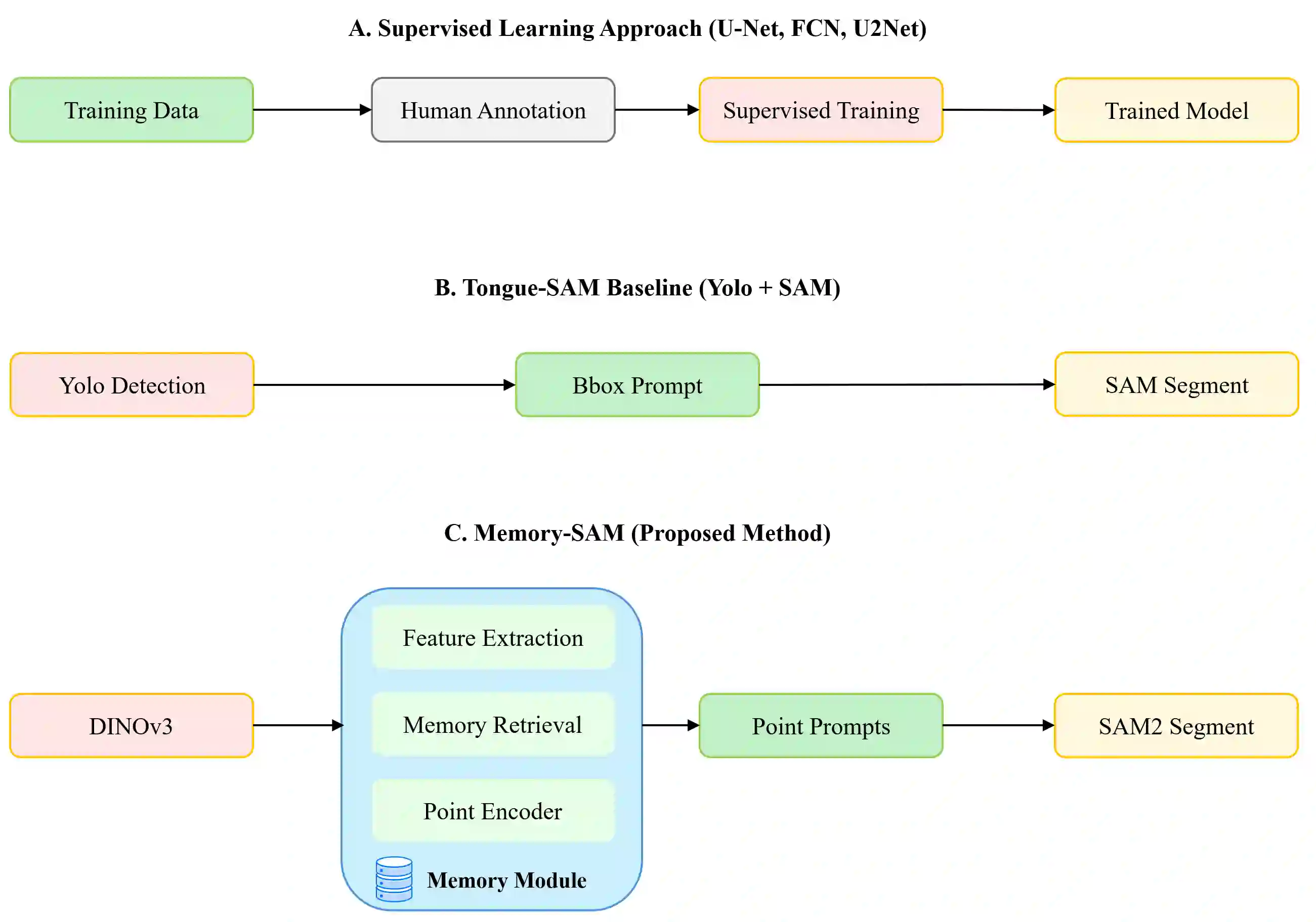
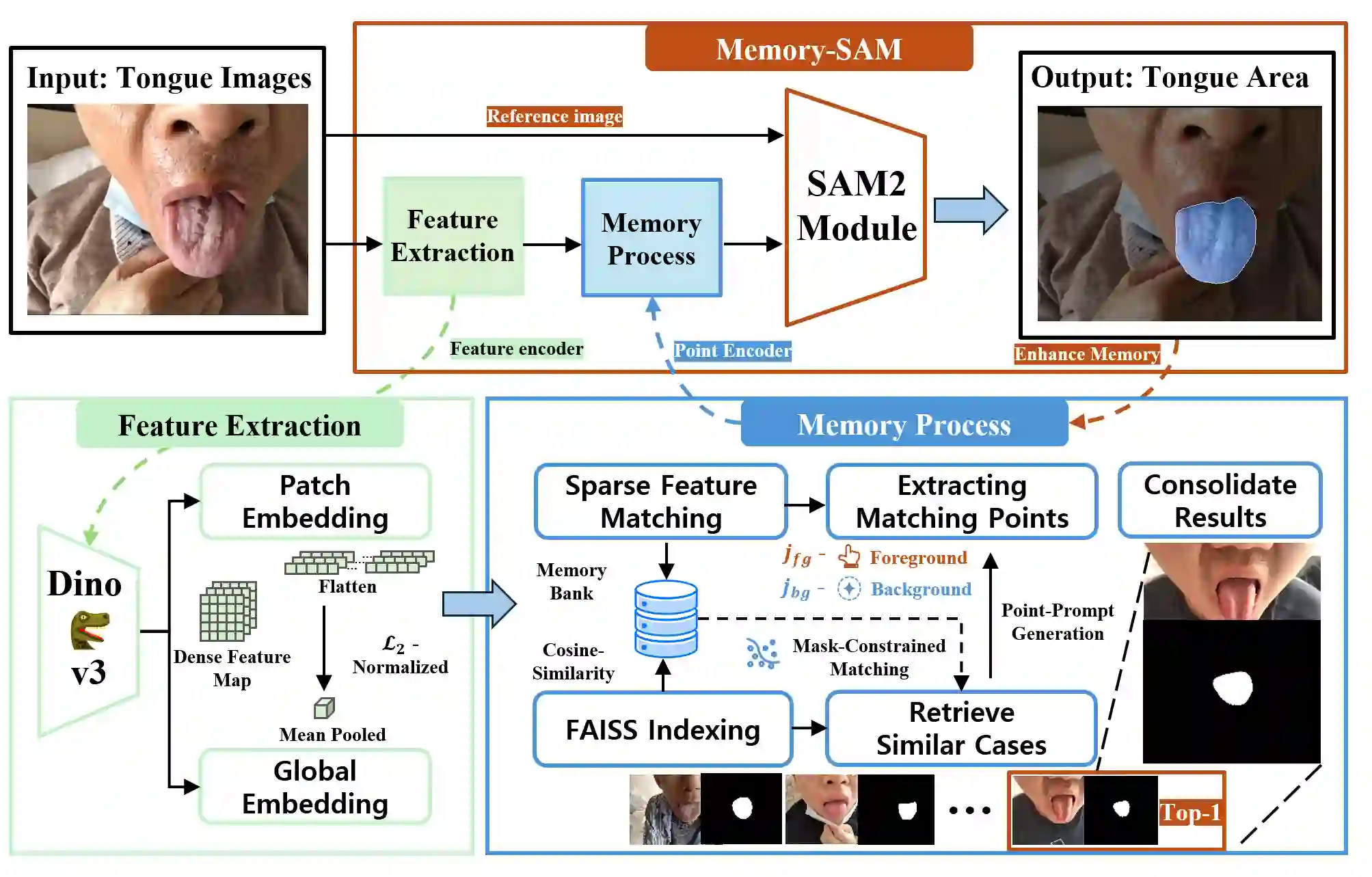
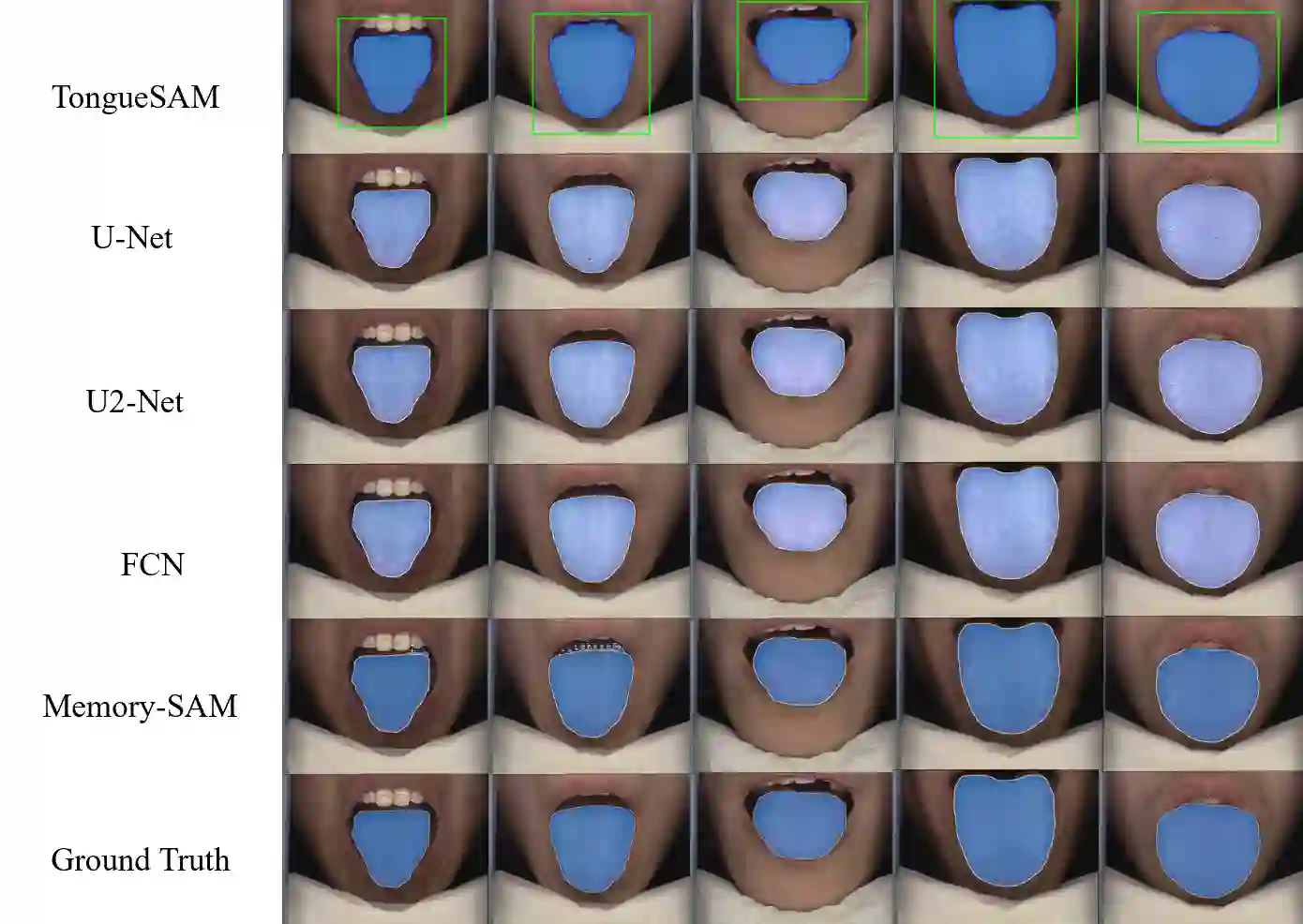
Accurate tongue segmentation is crucial for reliable TCM analysis. Supervised models require large annotated datasets, while SAM-family models remain prompt-driven. We present Memory-SAM, a training-free, human-prompt-free pipeline that automatically generates effective prompts from a small memory of prior cases via dense DINOv3 features and FAISS retrieval. Given a query image, mask-constrained correspondences to the retrieved exemplar are distilled into foreground/background point prompts that guide SAM2 without manual clicks or model fine-tuning. We evaluate on 600 expert-annotated images (300 controlled, 300 in-the-wild). On the mixed test split, Memory-SAM achieves mIoU 0.9863, surpassing FCN (0.8188) and a detector-to-box SAM baseline (0.1839). On controlled data, ceiling effects above 0.98 make small differences less meaningful given annotation variability, while our method shows clear gains under real-world conditions. Results indicate that retrieval-to-prompt enables data-efficient, robust segmentation of irregular boundaries in tongue imaging. The code is publicly available at https://github.com/jw-chae/memory-sam.
翻译:精确的舌体分割对于可靠的中医分析至关重要。监督模型需要大量标注数据集,而SAM系列模型仍需人工提示驱动。本文提出Memory-SAM,一种无需训练、无需人工提示的流程,通过密集的DINOv3特征和FAISS检索,从少量先验案例记忆中自动生成有效提示。给定查询图像,与检索示例的掩码约束对应关系被提炼为前景/背景点提示,从而无需手动点击或模型微调即可引导SAM2。我们在600张专家标注图像(300张受控环境,300张真实场景)上进行评估。在混合测试集上,Memory-SAM实现了0.9863的mIoU,超越了FCN(0.8188)和检测器到框的SAM基线方法(0.1839)。在受控数据上,由于标注变异性,高于0.98的天花板效应使得微小差异意义不大,而我们的方法在真实场景条件下显示出明显优势。结果表明,检索到提示的方法能够实现对舌体成像中不规则边界的数据高效且鲁棒的分割。代码已公开于https://github.com/jw-chae/memory-sam。