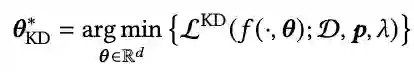This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 1% and 4% higher scoring accuracy than ANN and TinyBERT and comparable accuracy to the teacher model. Furthermore, the student model size is 0.02M, 10,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
翻译:本研究提出了一种知识蒸馏方法,将微调后的大语言模型的知识迁移至更小、更高效且更精确的神经网络中。我们特别针对在资源受限设备上部署这些模型的挑战展开研究。该方法通过利用大语言模型(作为教师模型)的预测概率(即软标签)来训练较小的学生模型(神经网络),并采用专门设计的损失函数从大语言模型的输出概率中学习,确保学生模型能够紧密模仿教师模型的性能。为验证知识蒸馏方法的有效性,我们使用了包含6684条学生科学问题作答记录的大规模数据集7T,以及三个由人工专家评分的数学推理数据集(学生作答内容)。我们将该方法与当前最优的蒸馏模型TinyBERT及人工神经网络模型进行了精度对比。实验结果表明,知识蒸馏方法在评分精度上分别比人工神经网络和TinyBERT高出1%和4%,且与教师模型精度相当。此外,学生模型的参数量仅为0.02M,参数规模比教师模型小10000倍,推理速度比TinyBERT快10倍。本研究的核心意义在于推动先进人工智能技术在典型教育场景中的实际应用,尤其是自动评分领域。