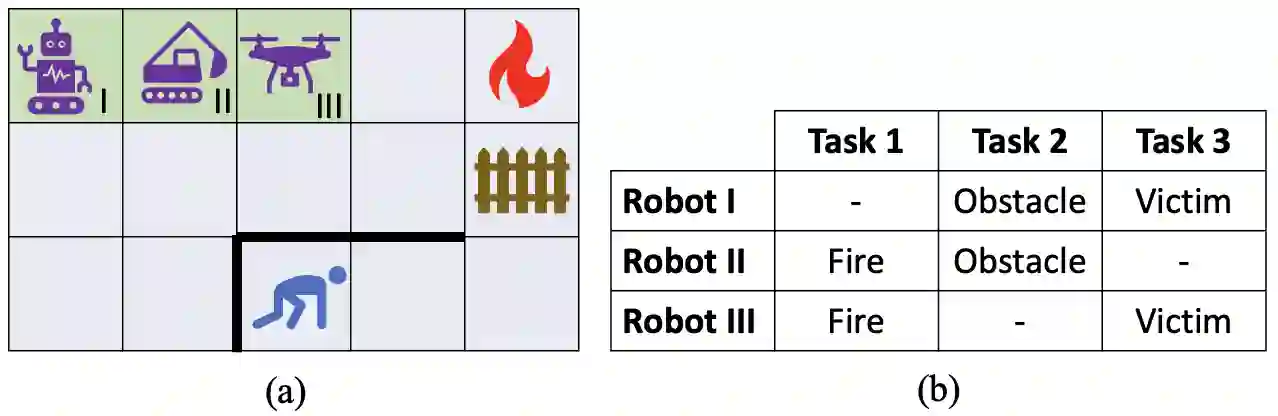
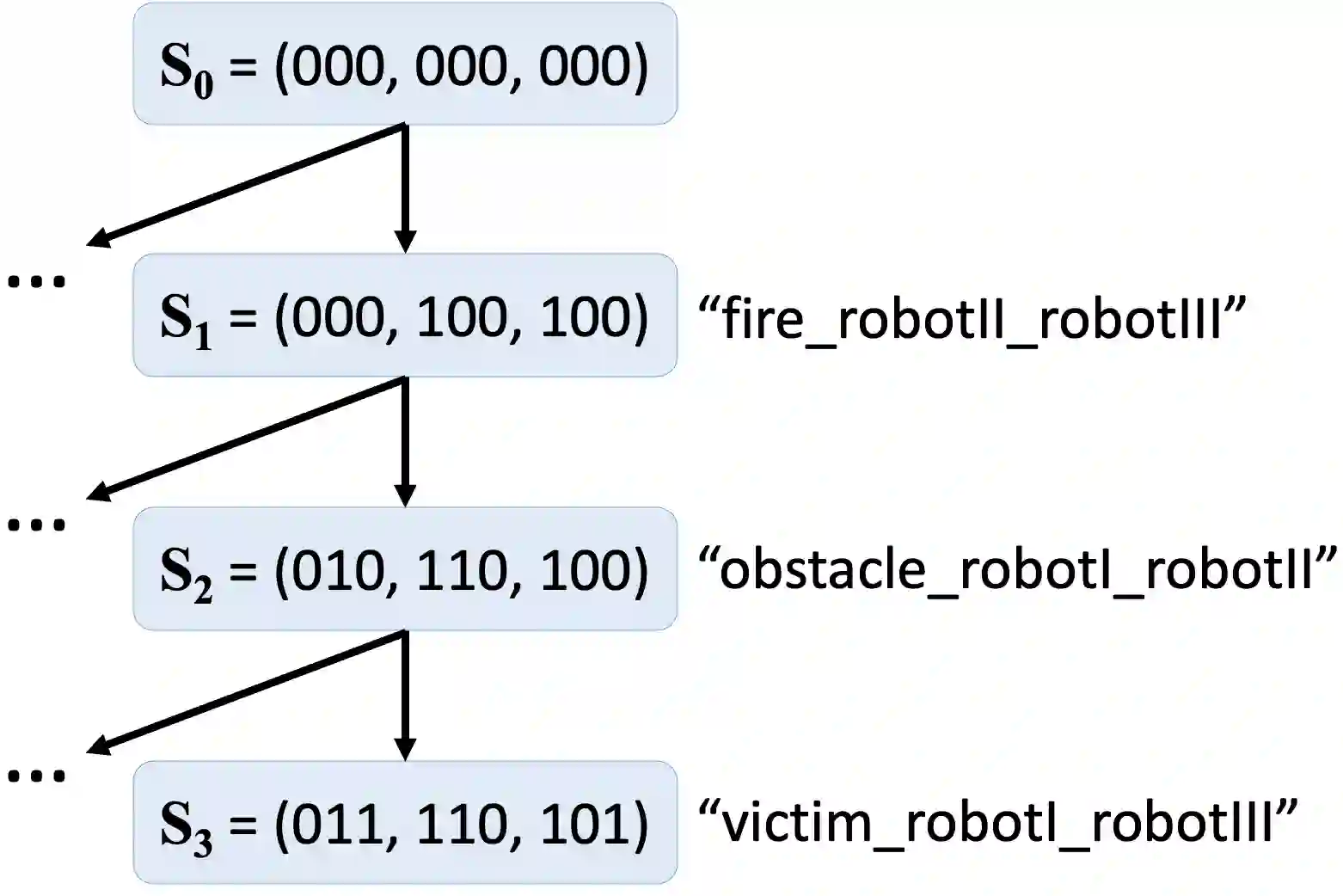
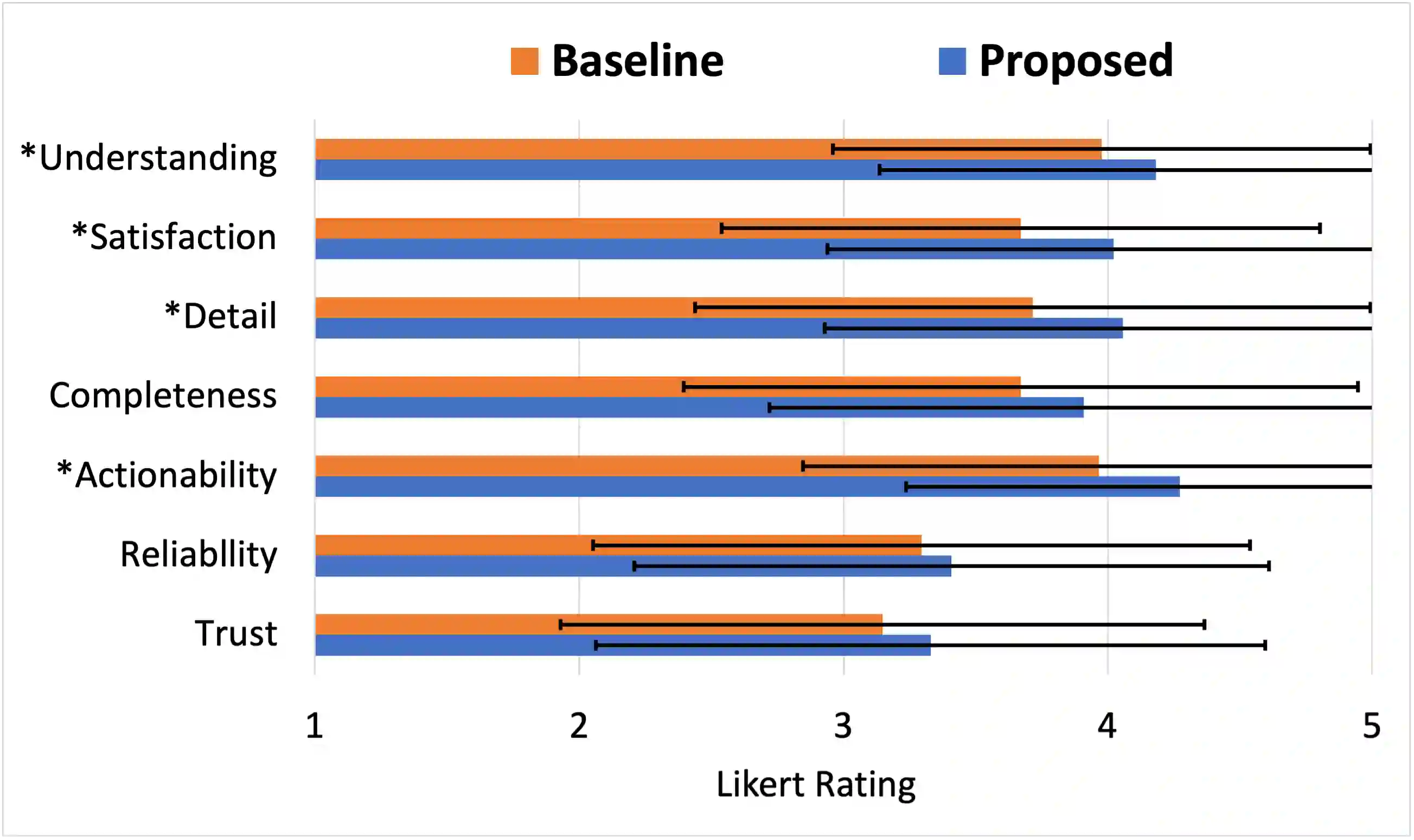
As multi-agent reinforcement learning (MARL) systems are increasingly deployed throughout society, it is imperative yet challenging for users to understand the emergent behaviors of MARL agents in complex environments. This work presents an approach for generating policy-level contrastive explanations for MARL to answer a temporal user query, which specifies a sequence of tasks completed by agents with possible cooperation. The proposed approach encodes the temporal query as a PCTL logic formula and checks if the query is feasible under a given MARL policy via probabilistic model checking. Such explanations can help reconcile discrepancies between the actual and anticipated multi-agent behaviors. The proposed approach also generates correct and complete explanations to pinpoint reasons that make a user query infeasible. We have successfully applied the proposed approach to four benchmark MARL domains (up to 9 agents in one domain). Moreover, the results of a user study show that the generated explanations significantly improve user performance and satisfaction.
翻译:随着多智能体强化学习系统在社会中日益广泛部署,用户理解复杂环境下多智能体涌现行为的需求变得迫切且具有挑战性。本文提出一种为多智能体强化学习生成策略级对比解释的方法,用于回答用户的时序查询——该查询指定智能体在可能协作下完成的一系列任务序列。该方法将时序查询编码为PCTL逻辑公式,并通过概率模型检验验证该查询在给定多智能体强化学习策略下的可行性。此类解释有助于调和实际多智能体行为与预期行为之间的差异。所提方法还能生成正确且完备的解释,精准定位导致用户查询不可行的原因。我们已在四个基准多智能体强化学习领域(其中一个领域包含多达9个智能体)成功应用该方法。此外,用户研究结果表明,生成的解释显著提升了用户表现与满意度。