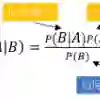
The Naive Bayesian classifier is a popular classification method employing the Bayesian paradigm. The concept of having conditional dependence among input variables sounds good in theory but can lead to a majority vote style behaviour. Achieving conditional independence is often difficult, and they introduce decision biases in the estimates. In Naive Bayes, certain features are called independent features as they have no conditional correlation or dependency when predicting a classification. In this paper, we focus on the optimal partition of features by proposing a novel technique called the Comonotone-Independence Classifier (CIBer) which is able to overcome the challenges posed by the Naive Bayes method. For different datasets, we clearly demonstrate the efficacy of our technique, where we achieve lower error rates and higher or equivalent accuracy compared to models such as Random Forests and XGBoost.
翻译:朴素贝叶斯分类器是一种利用贝叶斯范式的主流分类方法。理论上,输入变量间存在条件依赖关系的概念听起来合理,但实际可能导致多数表决式的行为。实现条件独立性往往十分困难,且会在估计中引入决策偏差。在朴素贝叶斯方法中,某些特征因在预测分类时不存在条件相关性或依赖性而被称作独立特征。本文通过提出名为共单调独立性分类器(CIBer)的新技术,聚焦于特征的最优划分问题,该技术能够克服朴素贝叶斯方法带来的挑战。我们针对不同数据集清晰展示了该技术的有效性——与随机森林和XGBoost等模型相比,该方法实现了更低的错误率以及更高或相当的分类精度。