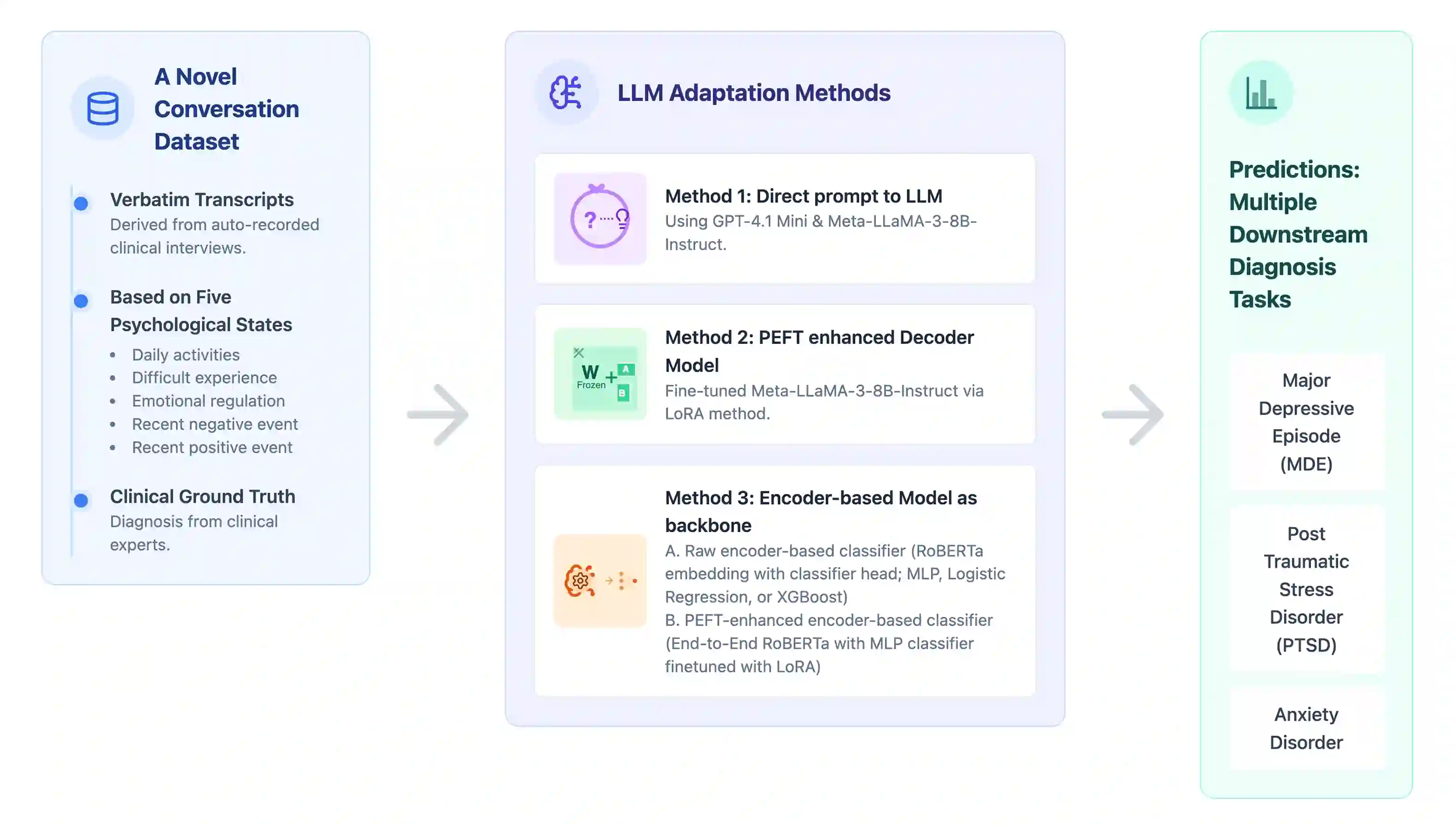
Mental health disorders remain among the leading cause of disability worldwide, yet conditions such as depression, anxiety, and Post-Traumatic Stress Disorder (PTSD) are frequently underdiagnosed or misdiagnosed due to subjective assessments, limited clinical resources, and stigma and low awareness. In primary care settings, studies show that providers misidentify depression or anxiety in over 60% of cases, highlighting the urgent need for scalable, accessible, and context-aware diagnostic tools that can support early detection and intervention. In this study, we evaluate the effectiveness of machine learning models for mental health screening using a unique dataset of 553 real-world, semistructured interviews, each paried with ground-truth diagnoses for major depressive episodes (MDE), anxiety disorders, and PTSD. We benchmark multiple model classes, including zero-shot prompting with GPT-4.1 Mini and MetaLLaMA, as well as fine-tuned RoBERTa models using LowRank Adaptation (LoRA). Our models achieve over 80% accuracy across diagnostic categories, with especially strongperformance on PTSD (up to 89% accuracy and 98% recall). We also find that using shorter context, focused context segments improves recall, suggesting that focused narrative cues enhance detection sensitivity. LoRA fine-tuning proves both efficient and effective, with lower-rank configurations (e.g., rank 8 and 16) maintaining competitive performance across evaluation metrics. Our results demonstrate that LLM-based models can offer substantial improvements over traditional self-report screening tools, providing a path toward low-barrier, AI-powerd early diagnosis. This work lays the groundwork for integrating machine learning into real-world clinical workflows, particularly in low-resource or high-stigma environments where access to timely mental health care is most limited.
翻译:心理健康障碍仍是全球范围内致残的主要原因之一,然而抑郁症、焦虑症和创伤后应激障碍(PTSD)等疾病常因主观评估、临床资源有限、社会污名化及认知度低而被漏诊或误诊。在初级诊疗环境中,研究表明医生对抑郁症或焦虑症的误判率超过60%,这凸显了对可扩展、易获取且具有情境感知能力的诊断工具的迫切需求,以支持早期发现和干预。本研究利用一个独特的真实世界半结构化访谈数据集(共553例),评估机器学习模型在心理健康筛查中的有效性,每例访谈均配有重度抑郁发作(MDE)、焦虑症和PTSD的真实诊断标签。我们对多类模型进行了基准测试,包括使用GPT-4.1 Mini和MetaLLaMA的零样本提示方法,以及采用低秩自适应(LoRA)微调的RoBERTa模型。我们的模型在所有诊断类别中均达到超过80%的准确率,其中对PTSD的识别表现尤为突出(准确率最高达89%,召回率达98%)。研究还发现,使用聚焦的短上下文片段能提升召回率,表明聚焦的叙事线索可增强检测敏感性。LoRA微调被证明兼具高效性与有效性,低秩配置(如秩为8和16)能在各项评估指标中保持竞争力。我们的结果表明,基于大语言模型的工具相较传统自评筛查工具可实现显著改进,为低门槛、人工智能驱动的早期诊断提供了可行路径。本研究为将机器学习整合至真实世界临床工作流程奠定了基础,尤其在资源匮乏或污名化严重、难以及时获得心理健康服务的环境中具有重要应用前景。