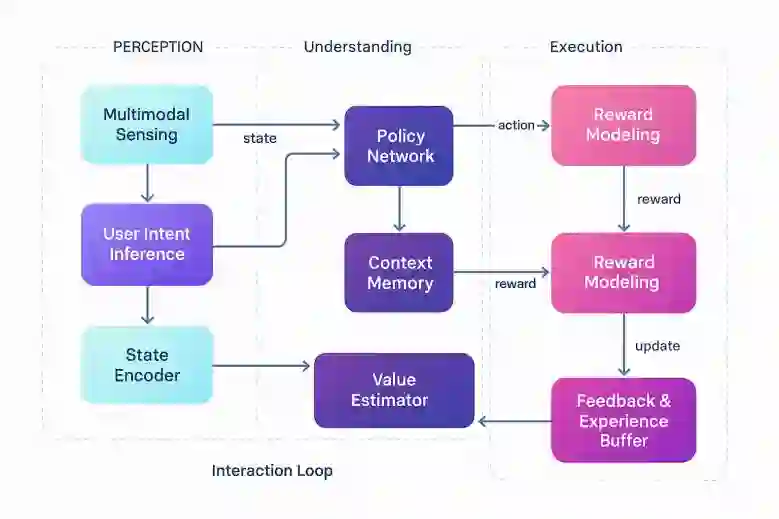
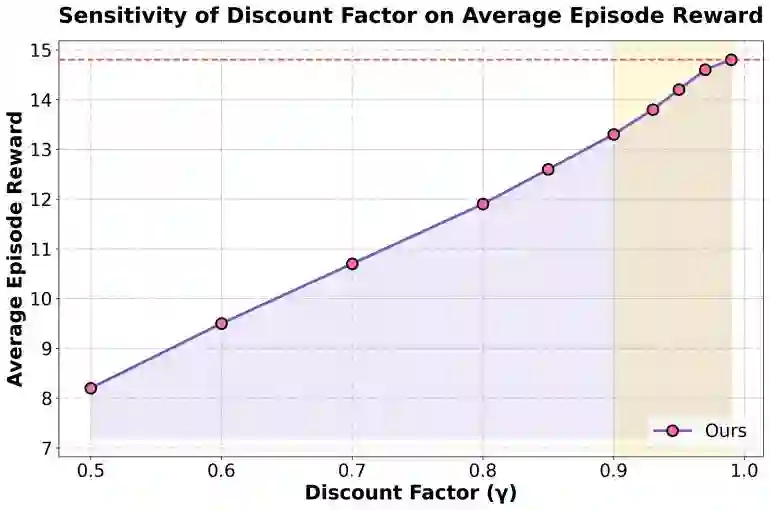
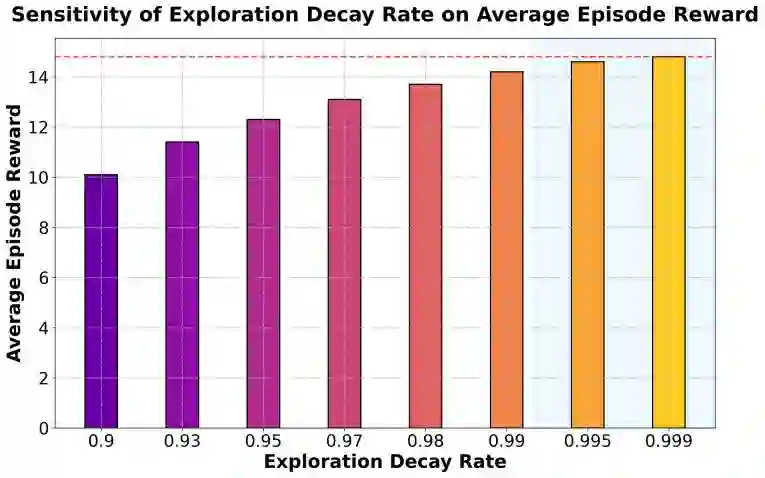
This study addresses the challenges of dynamics and complexity in intelligent human-computer interaction and proposes a reinforcement learning-based optimization framework to improve long-term returns and overall experience. Human-computer interaction is modeled as a Markov decision process, with state space, action space, reward function, and discount factor defined to capture the dynamics of user input, system feedback, and interaction environment. The method combines policy function, value function, and advantage function, updates parameters through policy gradient, and continuously adjusts during interaction to balance immediate feedback and long-term benefits. To validate the framework, multimodal dialog and scene-aware datasets are used as the experimental platform, with multiple sensitivity experiments conducted on key factors such as discount factor, exploration rate decay, environmental noise, and data imbalance. Evaluation is carried out using cumulative reward, average episode reward, convergence speed, and task success rate. Results show that the proposed method outperforms existing approaches across several metrics, achieving higher task completion while maintaining strategy stability. Comparative experiments further confirm its advantages in interaction efficiency and long-term return, demonstrating the significant value of reinforcement learning in optimizing human-computer interaction.
翻译:本研究针对智能人机交互中的动态性与复杂性挑战,提出了一种基于强化学习的优化框架,以提升长期回报与整体体验。人机交互被建模为马尔可夫决策过程,通过定义状态空间、动作空间、奖励函数与折扣因子来捕捉用户输入、系统反馈及交互环境的动态特性。该方法结合策略函数、价值函数与优势函数,通过策略梯度更新参数,并在交互过程中持续调整以平衡即时反馈与长期收益。为验证该框架,采用多模态对话与场景感知数据集作为实验平台,对折扣因子、探索率衰减、环境噪声及数据不平衡等关键因素进行了多组敏感性实验。评估采用累积奖励、平均回合奖励、收敛速度与任务成功率等指标。结果表明,所提方法在多项指标上优于现有方法,在保持策略稳定性的同时实现了更高的任务完成度。对比实验进一步证实了其在交互效率与长期回报方面的优势,彰显了强化学习在优化人机交互中的显著价值。