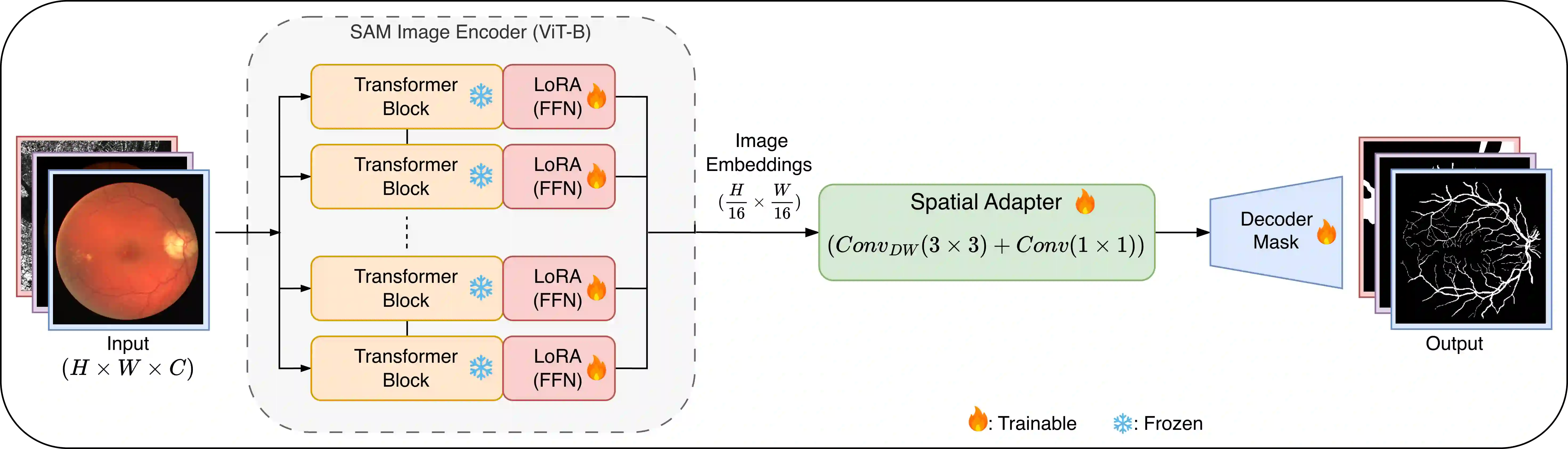
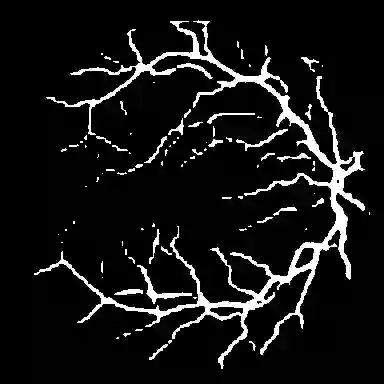
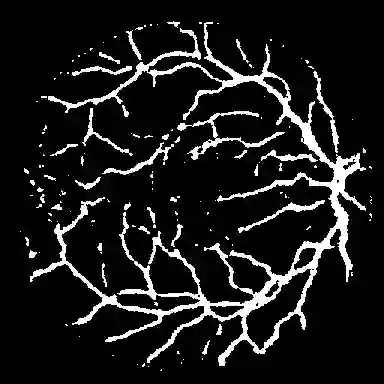
Foundation segmentation models such as the Segment Anything Model (SAM) exhibit strong zero-shot generalization through large-scale pretraining, but adapting them to domain-specific semantic segmentation remains challenging, particularly for thin structures (e.g., retinal vessels) and noisy modalities (e.g., SAR imagery). Full fine-tuning is computationally expensive and risks catastrophic forgetting. We propose \textbf{TopoLoRA-SAM}, a topology-aware and parameter-efficient adaptation framework for binary semantic segmentation. TopoLoRA-SAM injects Low-Rank Adaptation (LoRA) into the frozen ViT encoder, augmented with a lightweight spatial convolutional adapter and optional topology-aware supervision via differentiable clDice. We evaluate our approach on five benchmarks spanning retinal vessel segmentation (DRIVE, STARE, CHASE\_DB1), polyp segmentation (Kvasir-SEG), and SAR sea/land segmentation (SL-SSDD), comparing against U-Net, DeepLabV3+, SegFormer, and Mask2Former. TopoLoRA-SAM achieves the best retina-average Dice and the best overall average Dice across datasets, while training only \textbf{5.2\%} of model parameters ($\sim$4.9M). On the challenging CHASE\_DB1 dataset, our method substantially improves segmentation accuracy and robustness, demonstrating that topology-aware parameter-efficient adaptation can match or exceed fully fine-tuned specialist models. Code is available at : https://github.com/salimkhazem/Seglab.git
翻译:基础分割模型,例如Segment Anything Model (SAM),通过大规模预训练展现出强大的零样本泛化能力,但将其适配到特定领域的语义分割任务仍然具有挑战性,尤其是在处理细长结构(如视网膜血管)和噪声模态(如SAR图像)时。完全微调计算成本高昂且存在灾难性遗忘的风险。我们提出了\textbf{TopoLoRA-SAM},一个面向二值语义分割的拓扑感知且参数高效的适配框架。TopoLoRA-SAM将低秩适配(LoRA)注入到冻结的ViT编码器中,并辅以一个轻量级的空间卷积适配器,以及通过可微分clDice实现的、可选的拓扑感知监督。我们在涵盖视网膜血管分割(DRIVE, STARE, CHASE\_DB1)、息肉分割(Kvasir-SEG)和SAR海陆分割(SL-SSDD)的五个基准数据集上评估了我们的方法,并与U-Net、DeepLabV3+、SegFormer和Mask2Former进行了比较。TopoLoRA-SAM在视网膜数据集上取得了最佳的平均Dice分数,并在所有数据集上取得了最佳的整体平均Dice分数,同时仅训练了模型\textbf{5.2\%}的参数(约490万)。在具有挑战性的CHASE\_DB1数据集上,我们的方法显著提升了分割精度和鲁棒性,证明了拓扑感知的参数高效适配能够匹配甚至超越完全微调的专业模型。代码发布于:https://github.com/salimkhazem/Seglab.git