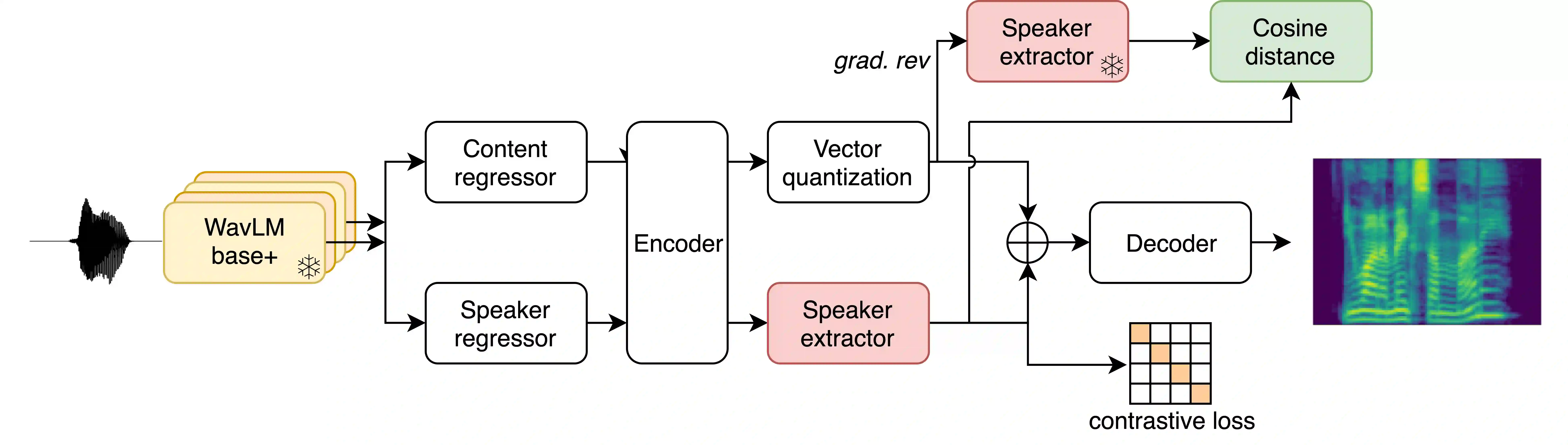
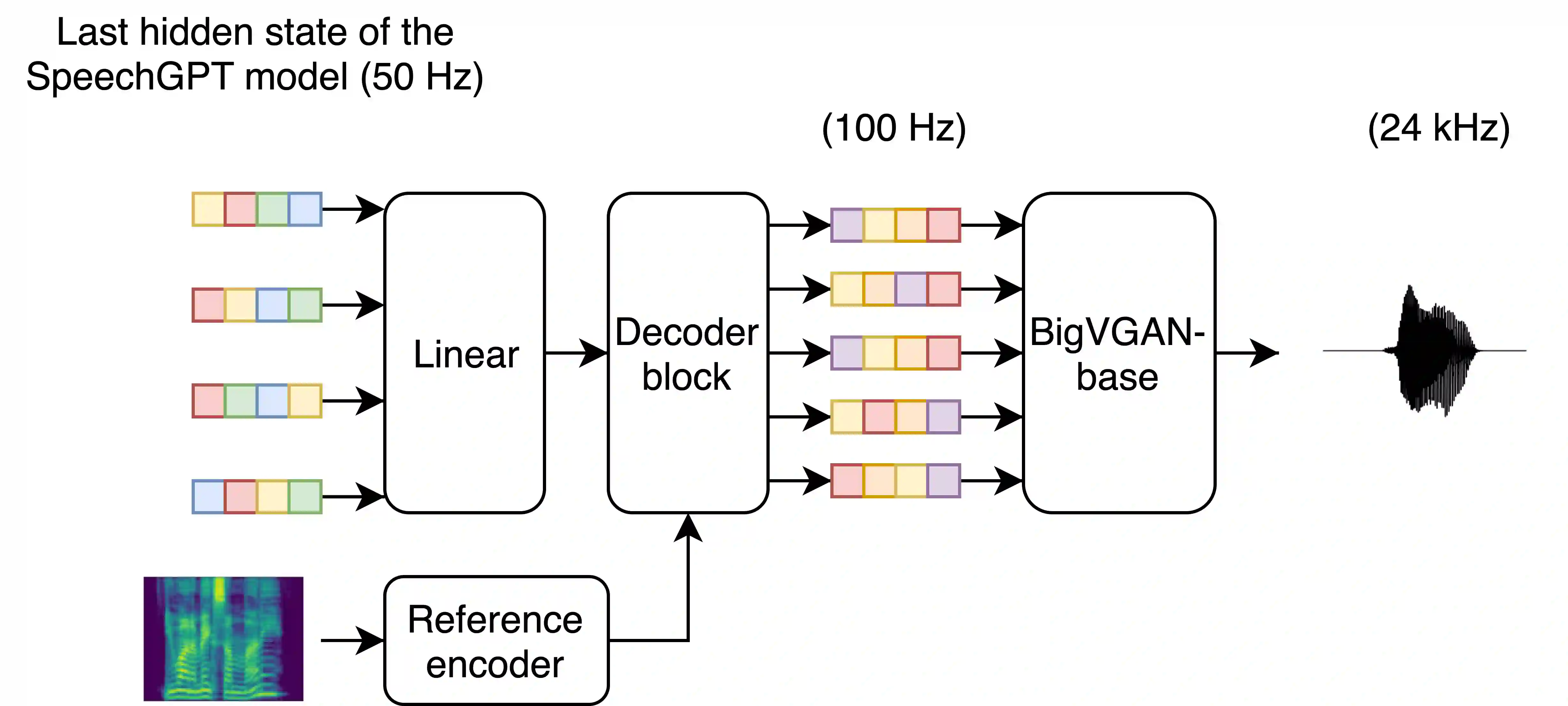
We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
翻译:我们提出一种名为BASE TTS的文本转语音(TTS)模型,其中BASE TTS代表 $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities。BASE TTS是迄今为止规模最大的TTS模型,基于10万小时公共领域语音数据训练,在语音自然度方面达到了新的最优水平。该模型采用10亿参数自回归Transformer,将原始文本转换为离散编码("语音编码"),随后通过基于卷积的解码器以增量、流式方式将这些语音编码转换为波形。此外,我们的语音编码采用了一种新型语音分词技术,该技术具备说话人身份解耦功能,并通过字节对编码实现压缩。与大型语言模型在数据量增长时展现的"涌现能力"相呼应,我们证明使用1万小时以上数据和5亿以上参数构建的BASE TTS变体开始在文本复杂句式中展现自然韵律。为衡量文本转语音领域的这些涌现能力,我们设计并公开了专用数据集。通过与包括公开可用大规模文本转语音系统YourTTS、Bark和TortoiseTTS在内的基线模型进行对比评估,我们展示了BASE TTS在自然度方面的最优表现。模型生成的音频样本可通过 https://amazon-ltts-paper.com/ 收听。