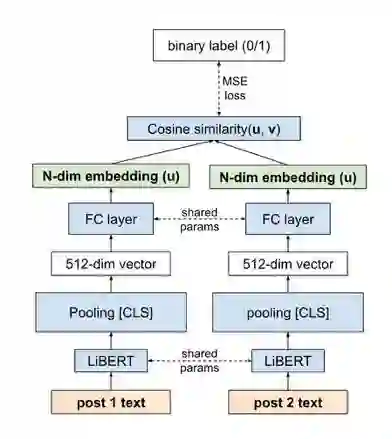
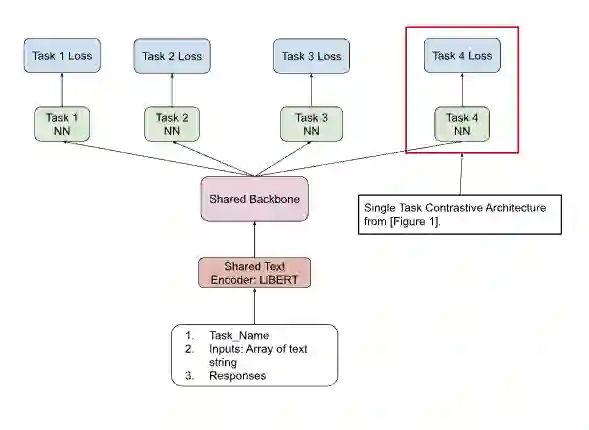
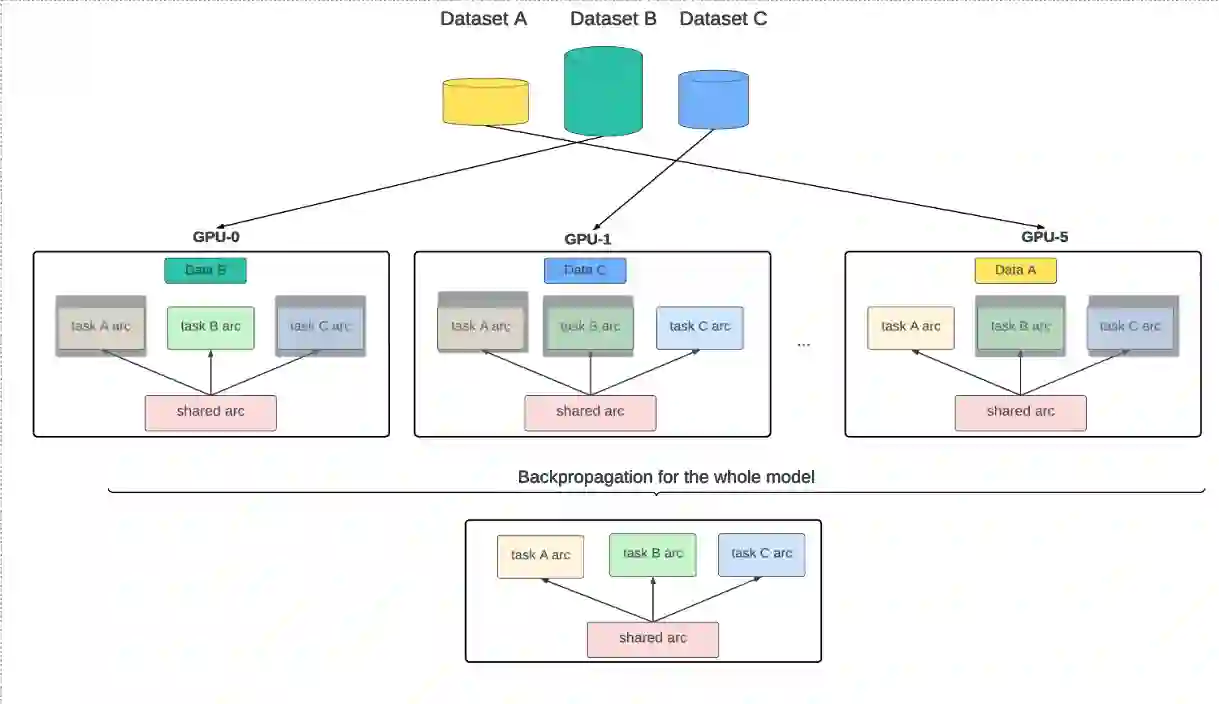
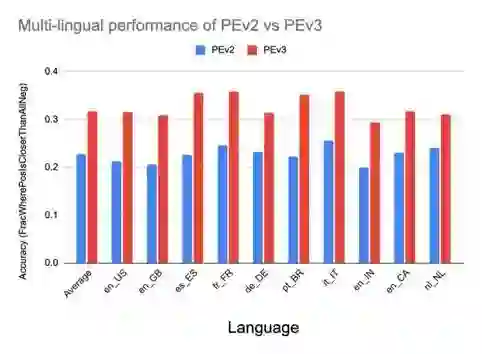
In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
翻译:在提升领英核心内容推荐模型的过程中,一个关键挑战在于增强其语义理解能力。本文通过利用多任务学习来解决这一问题,该方法已在多个领域显示出潜力。我们使用来自多种语义标注任务的数据,通过多任务对比学习对基于Transformer的预训练大语言模型进行微调。我们观察到正向迁移效果,使得模型在所有任务上的表现均优于独立训练各自任务的结果。我们的模型在零样本学习上优于基线,并提供了改进的多语言支持,凸显了其更广泛应用的潜力。该模型生成的专业内容嵌入在领英数据集和任务上优于OpenAI提供的通用嵌入。本研究为领英各垂直团队根据其具体应用定制和微调大语言模型提供了坚实基础。我们的工作为该领域的进一步发展提供了见解和最佳实践。