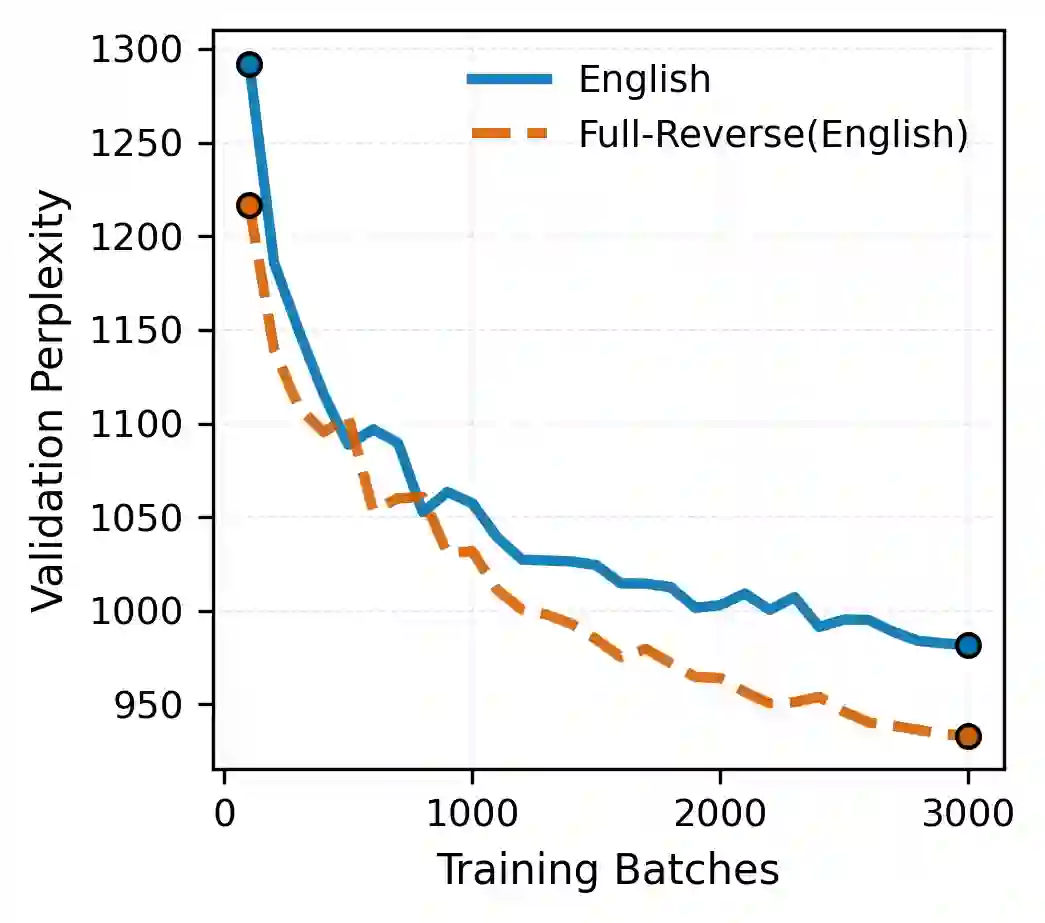
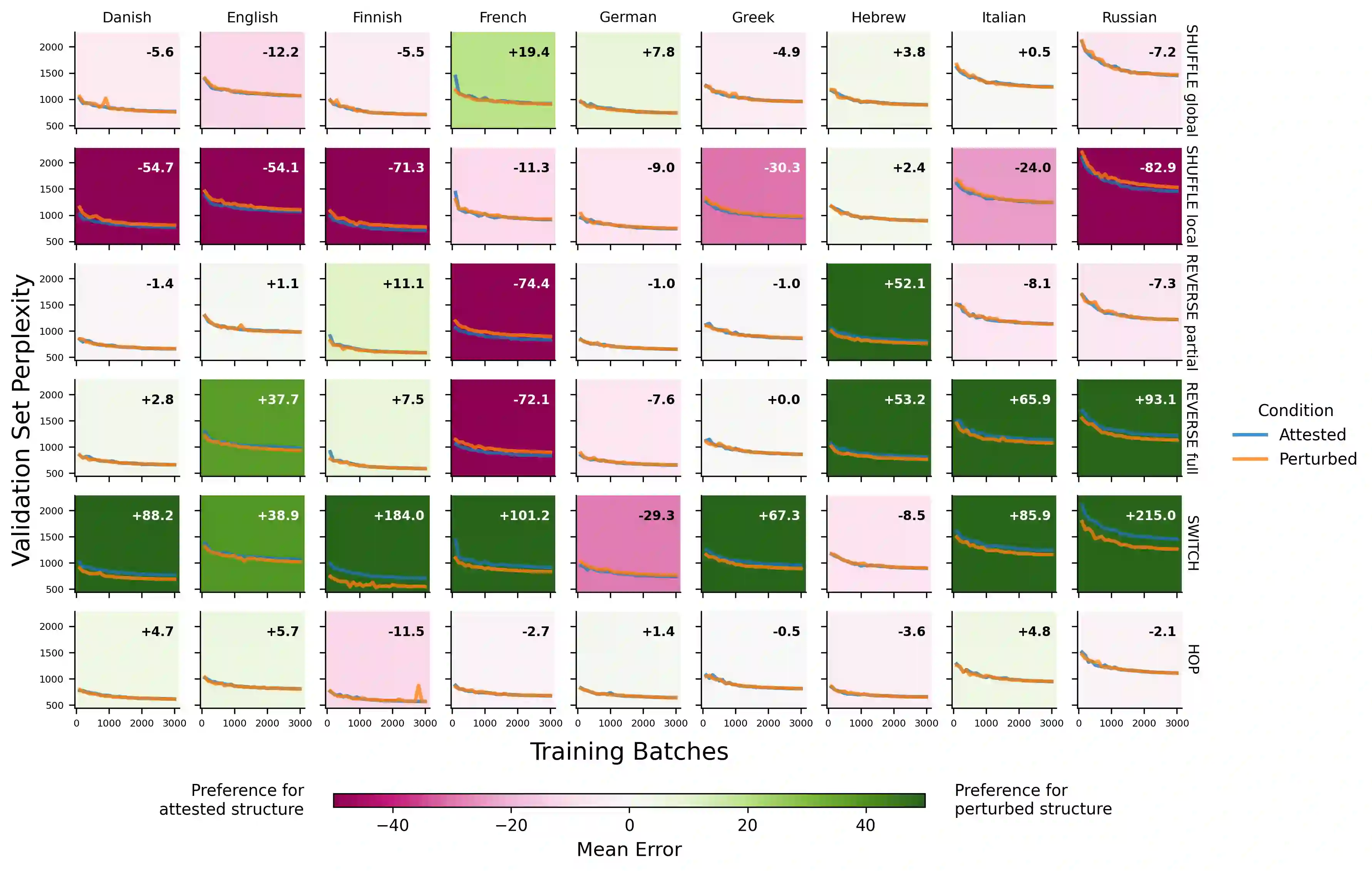
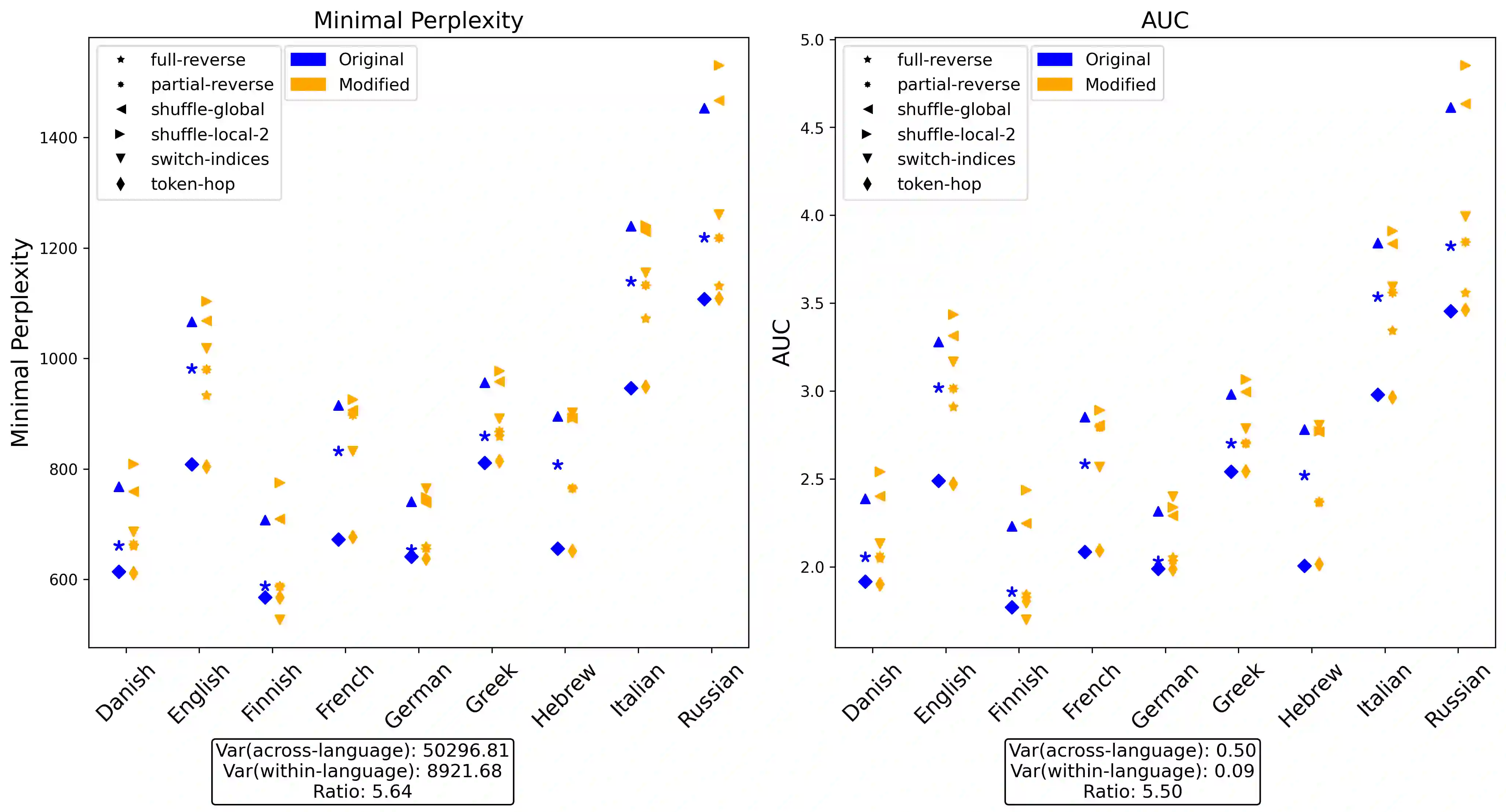
Are large language models (LLMs) sensitive to the distinction between humanly possible languages and humanly impossible languages? This question is taken by many to bear on whether LLMs and humans share the same innate learning biases. Previous work has attempted to answer it in the positive by comparing LLM learning curves on existing language datasets and on "impossible" datasets derived from them via various perturbation functions. Using the same methodology, we examine this claim on a wider set of languages and impossible perturbations. We find that in most cases, GPT-2 learns each language and its impossible counterpart equally easily, in contrast to previous claims. We also apply a more lenient condition by testing whether GPT-2 provides any kind of separation between the whole set of natural languages and the whole set of impossible languages. By considering cross-linguistic variance in various metrics computed on the perplexity curves, we show that GPT-2 provides no systematic separation between the possible and the impossible. Taken together, these perspectives show that LLMs do not share the human innate biases that shape linguistic typology.
翻译:大语言模型(LLMs)是否能够区分人类可能的语言与人类不可能的语言?这一问题被广泛认为关乎LLMs与人类是否共享相同的先天学习偏置。先前研究通过比较LLM在现有语言数据集与经过多种扰动函数生成的"不可能"数据集上的学习曲线,试图对此给出肯定答案。采用相同方法论,我们在更广泛的语言集和不可能扰动集上检验了这一主张。研究发现,在大多数情况下,GPT-2对每种语言及其对应不可能变体的学习难度相当,这与先前结论相悖。我们还通过测试GPT-2是否能在整体自然语言集与整体不可能语言集之间提供任何形式的区分,采用了更宽松的判定条件。通过对困惑度曲线计算的多种指标进行跨语言方差分析,我们证明GPT-2未能系统地区分可能语言与不可能语言。综合来看,这些视角表明LLMs并不具备塑造语言类型学的人类先天偏置。