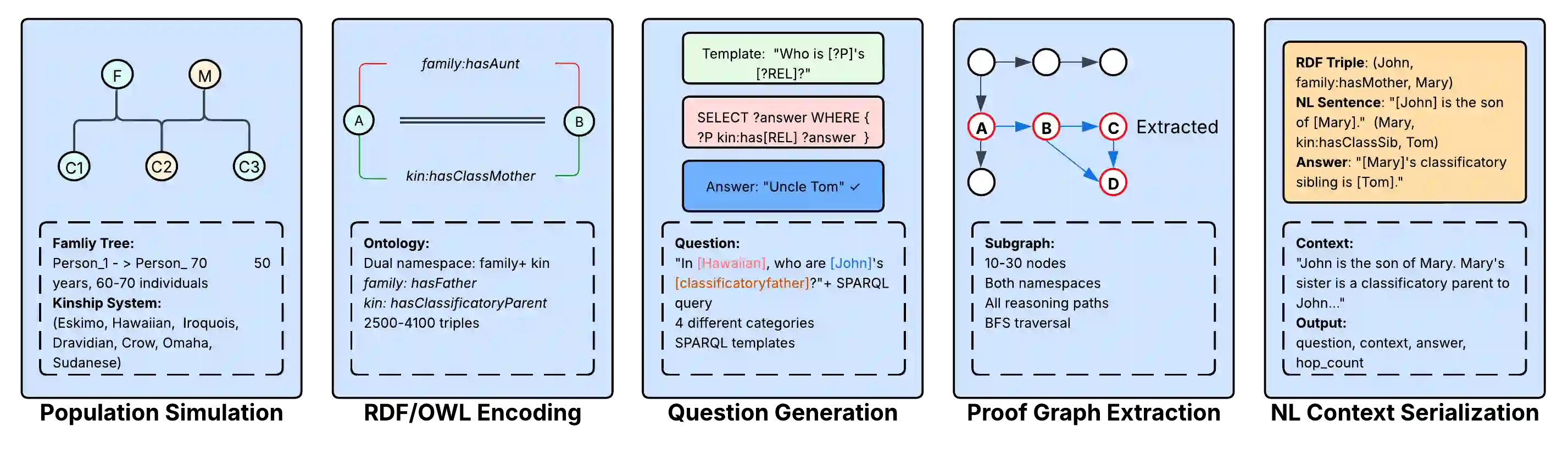
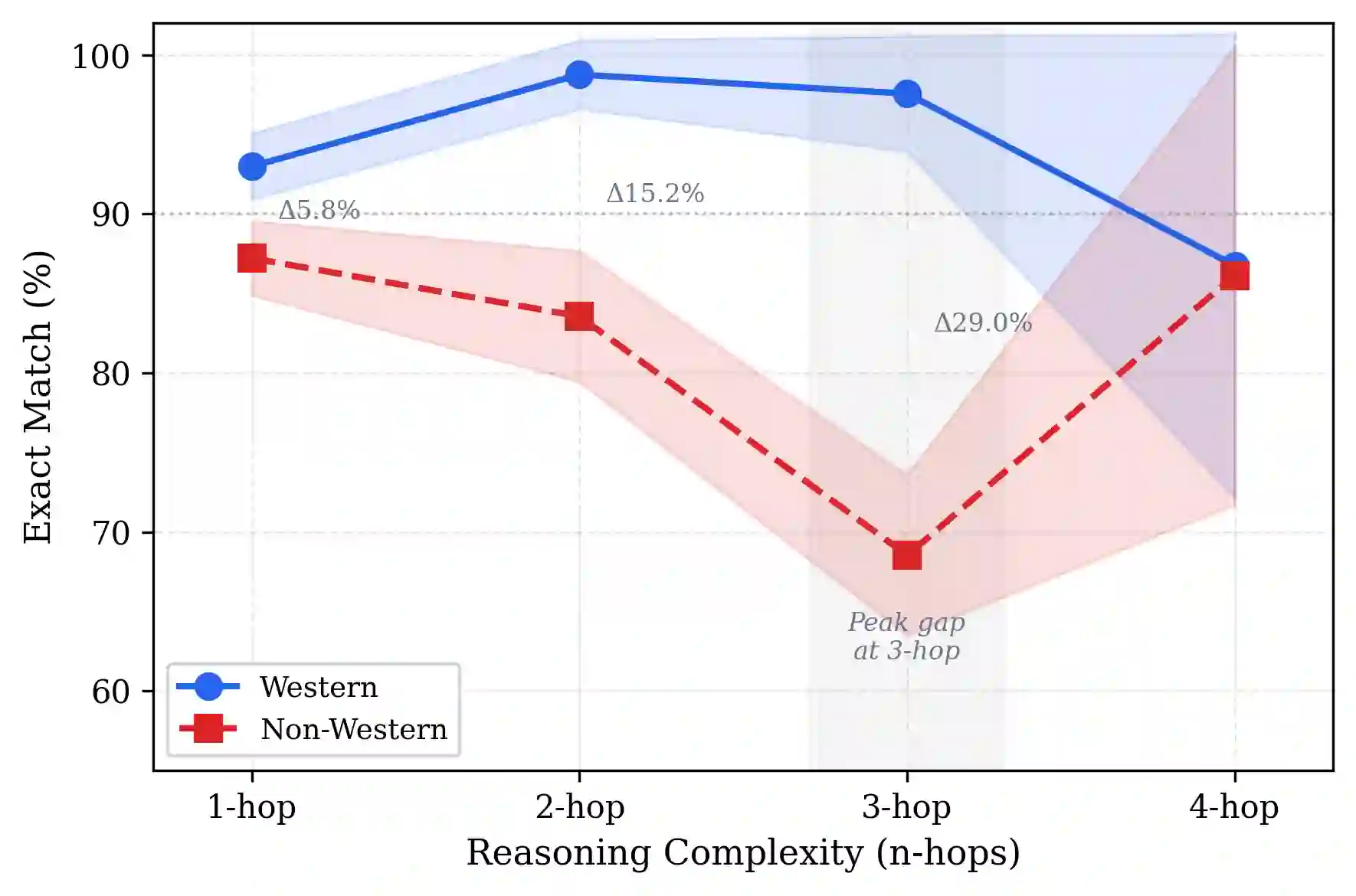
Large language models (LLMs) are increasingly evaluated on their ability to perform multi-hop reasoning, i.e., to combine multiple pieces of information into a coherent inference. We introduce KinshipQA, a benchmark designed to probe this capability through reasoning over kinship relations. The central contribution of our work is a generative pipeline that produces, on demand, large-scale, realistic, and culture-specific genealogical data: collections of interconnected family trees that satisfy explicit marriage constraints associated with different kinship systems. This allows task difficulty, cultural assumptions, and relational depth to be systematically controlled and varied. From these genealogies, we derive textual inference tasks that require reasoning over implicit relational chains. We evaluate the resulting benchmark using six state-of-the-art LLMs, spanning both open-source and closed-source models, under a uniform zero-shot protocol with deterministic decoding. Performance is measured using exact-match and set-based metrics. Our results demonstrate that KinshipQA yields a wide spread of outcomes and exposes systematic differences in multi-hop reasoning across models and cultural settings.
翻译:大型语言模型(LLMs)在多跳推理能力——即整合多条信息形成连贯推断的能力——方面正受到日益增多的评估。本文提出KinshipQA基准,该基准旨在通过对亲属关系的推理来探究这一能力。我们工作的核心贡献是一个生成式流水线,它能够按需生成大规模、真实且文化特定的谱系数据:即满足不同亲属制度下明确婚姻约束的相互关联的家族树集合。这使得任务难度、文化假设和关系深度得以被系统性地控制和调整。基于这些谱系数据,我们构建了需要推理隐含关系链的文本推断任务。我们采用统一的零样本协议和确定性解码策略,在六个最先进的大型语言模型(涵盖开源与闭源模型)上评估了所得基准的性能,并使用精确匹配和基于集合的指标进行度量。结果表明,KinshipQA能够产生广泛的性能分布,并揭示了不同模型及文化背景下多跳推理能力的系统性差异。