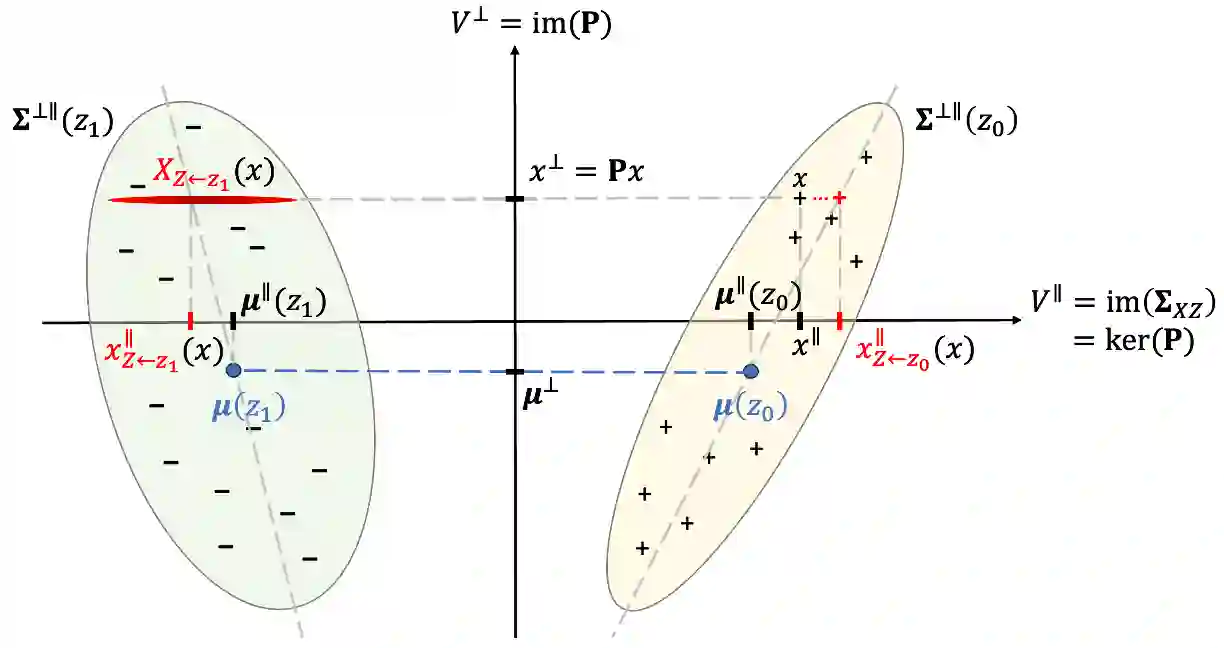
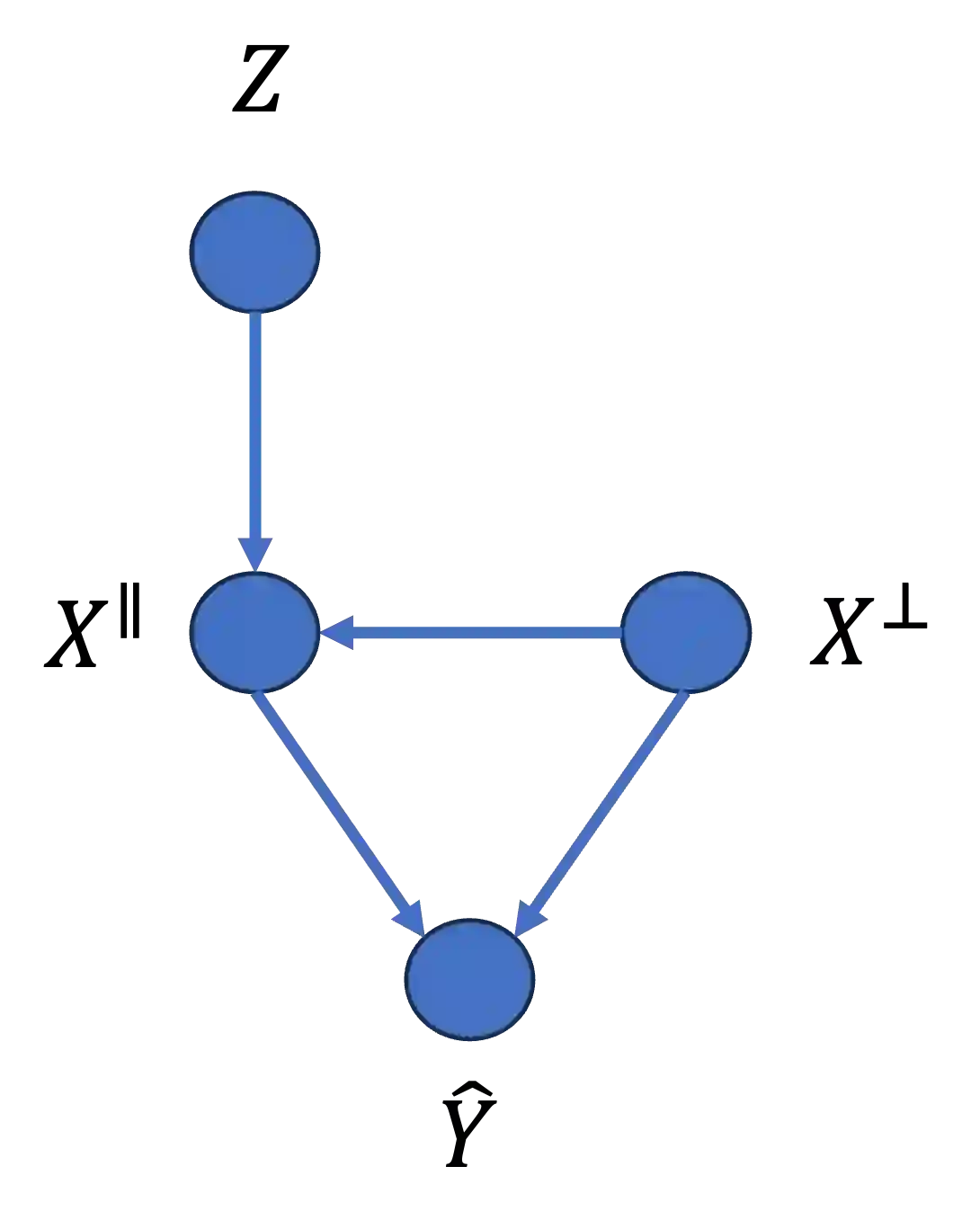
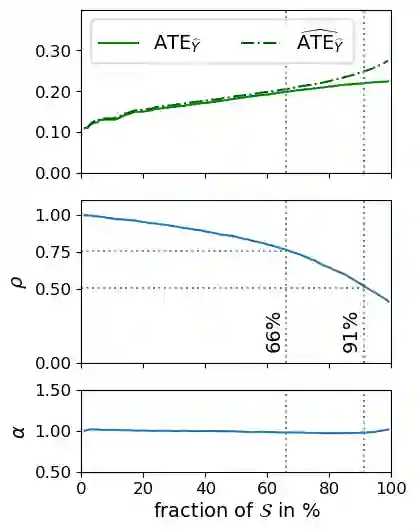
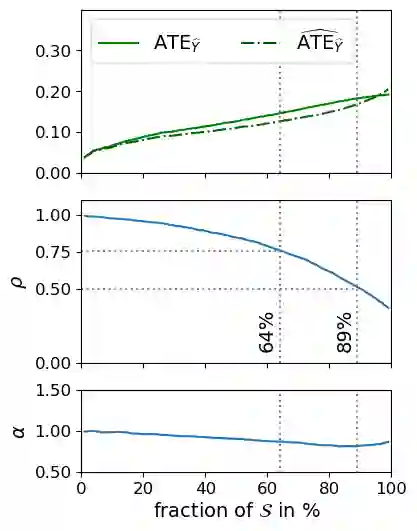
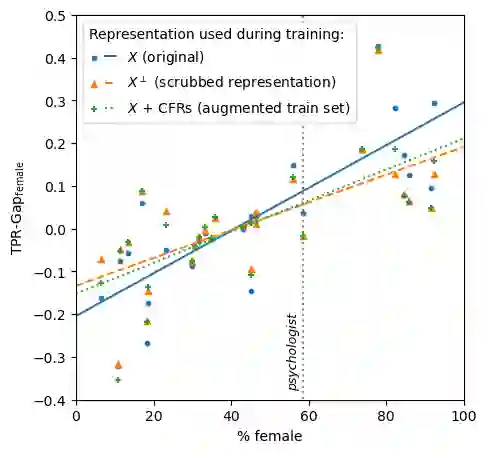
One well motivated explanation method for classifiers leverages counterfactuals which are hypothetical events identical to real observations in all aspects except for one categorical feature. Constructing such counterfactual poses specific challenges for texts, however, as some attribute values may not necessarily align with plausible real-world events. In this paper we propose a simple method for generating counterfactuals by intervening in the space of text representations which bypasses this limitation. We argue that our interventions are minimally disruptive and that they are theoretically sound as they align with counterfactuals as defined in Pearl's causal inference framework. To validate our method, we conducted experiments first on a synthetic dataset and then on a realistic dataset of counterfactuals. This allows for a direct comparison between classifier predictions based on ground truth counterfactuals - obtained through explicit text interventions - and our counterfactuals, derived through interventions in the representation space. Eventually, we study a real world scenario where our counterfactuals can be leveraged both for explaining a classifier and for bias mitigation.
翻译:一种具有充分动机的分类器解释方法利用反事实样本,即除一个类别特征外,所有方面均与真实观测完全一致的假设性事件。然而,在文本场景下构建此类反事实样本面临特殊挑战,因为某些属性值可能无法与真实世界事件保持合理一致。本文提出一种通过在文本表征空间进行干预来生成反事实样本的简洁方法,从而规避了这一局限性。我们论证了所提出的干预方法具有最小干扰性,且与Pearl因果推断框架中定义的反事实概念在理论上高度一致。为验证该方法,我们首先在合成数据集上开展实验,随后在真实反事实数据集上进行验证。这使得我们能够直接比较基于真实反事实(通过显式文本干预获得)与基于表征空间干预所得反事实的分类器预测结果。最终,我们研究了一个真实场景,该场景中的反事实样本既能用于解释分类器,也能用于偏差缓解。