
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA hinder innovations on query formats and learning algorithms.
翻译:基于人类反馈的强化学习(RLHF)现有算法可能激励出与偏好相悖的响应,因为这些算法依赖的模型假设无关选项的独立性(IIA)。IIA所引发的反常激励阻碍了查询格式与学习算法的创新。

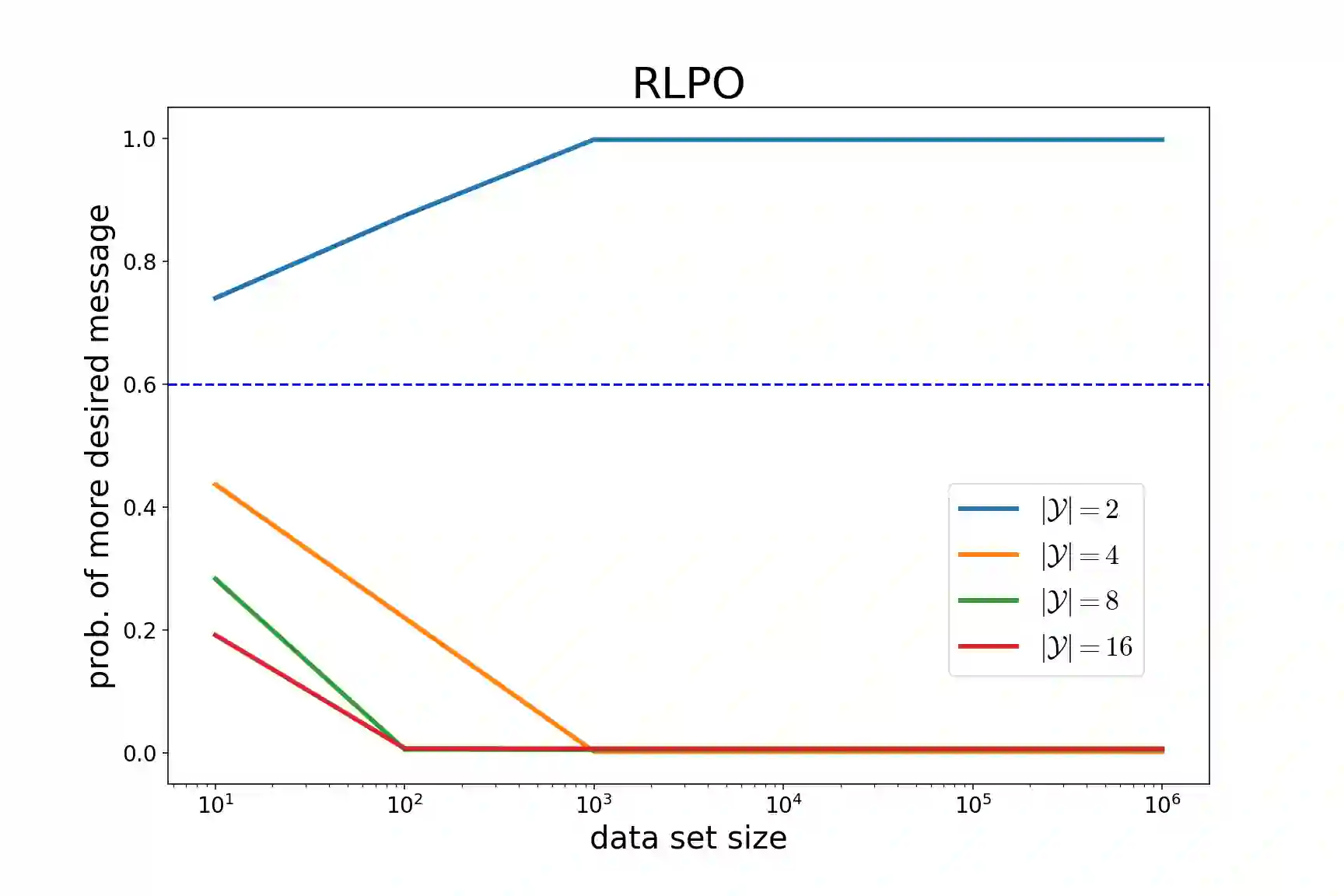
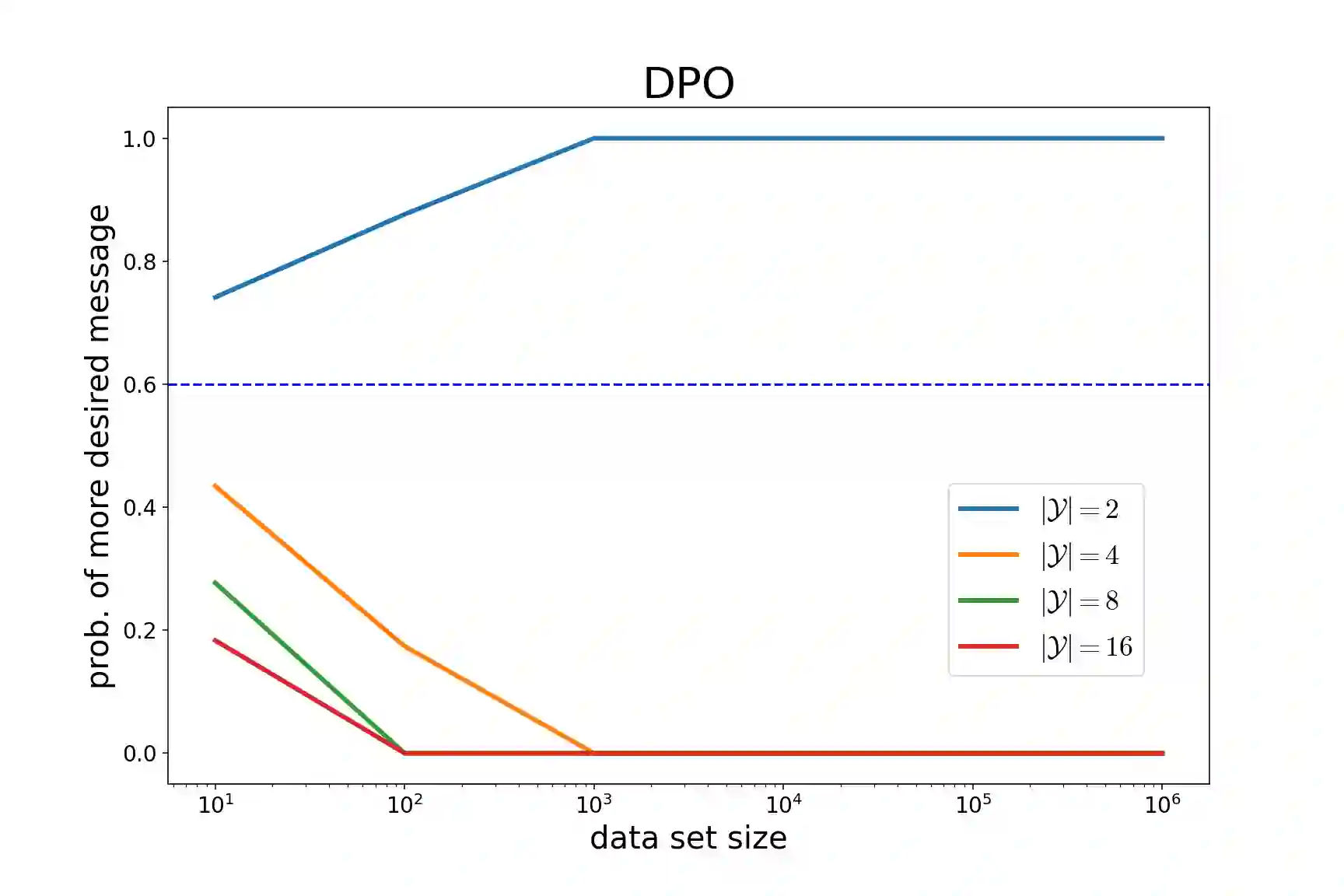
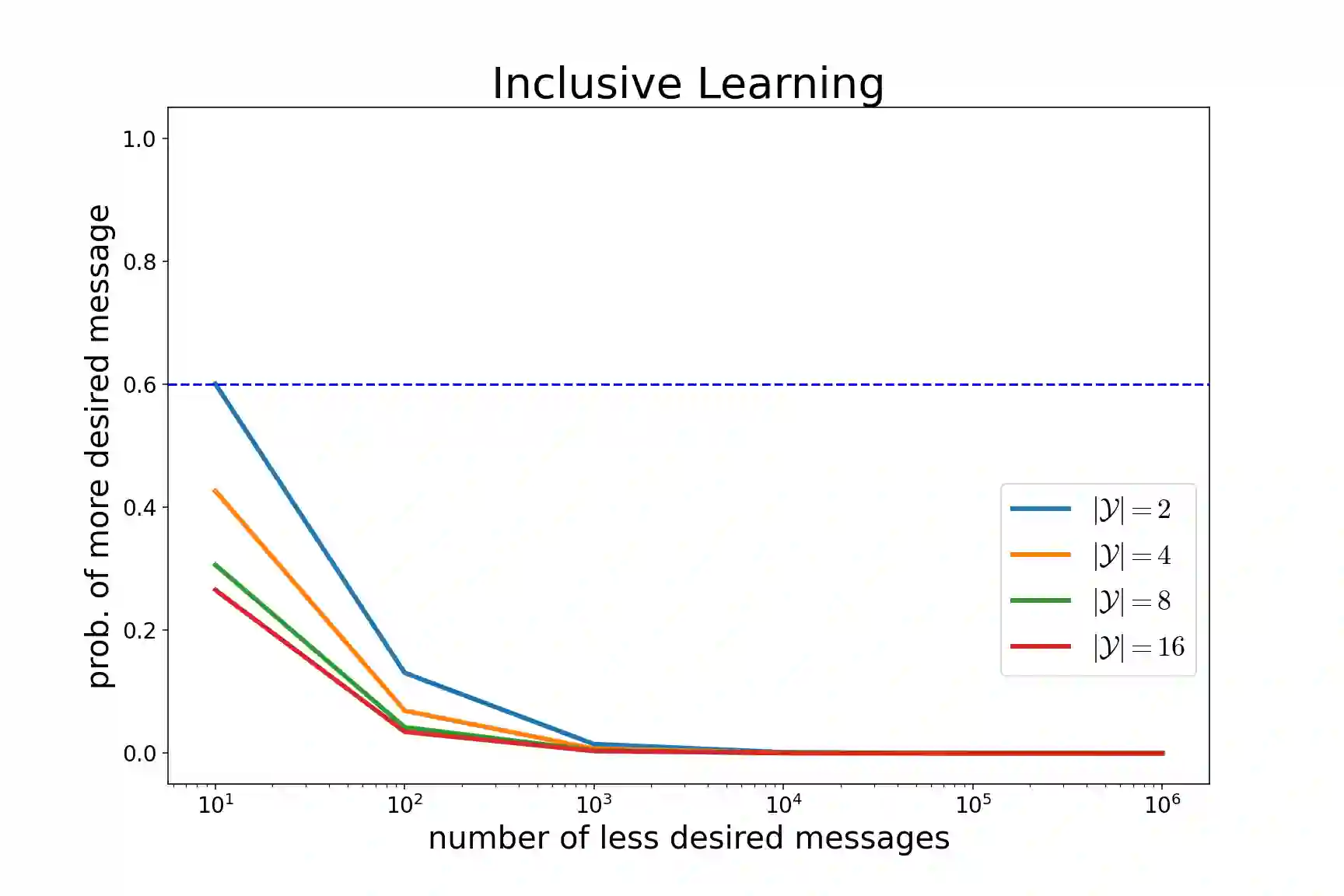
相关内容
专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年3月12日
Arxiv
34+阅读 · 2019年10月24日




最新内容
相关VIP内容
专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2024年3月12日
Arxiv
34+阅读 · 2019年10月24日