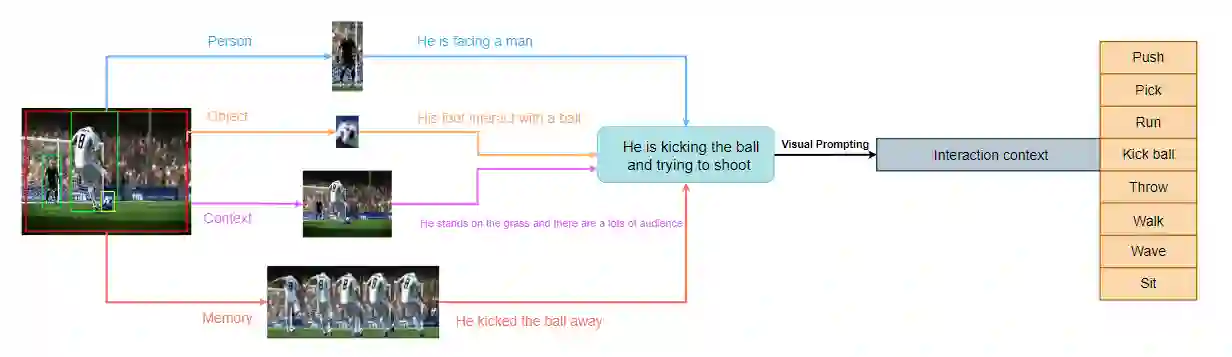
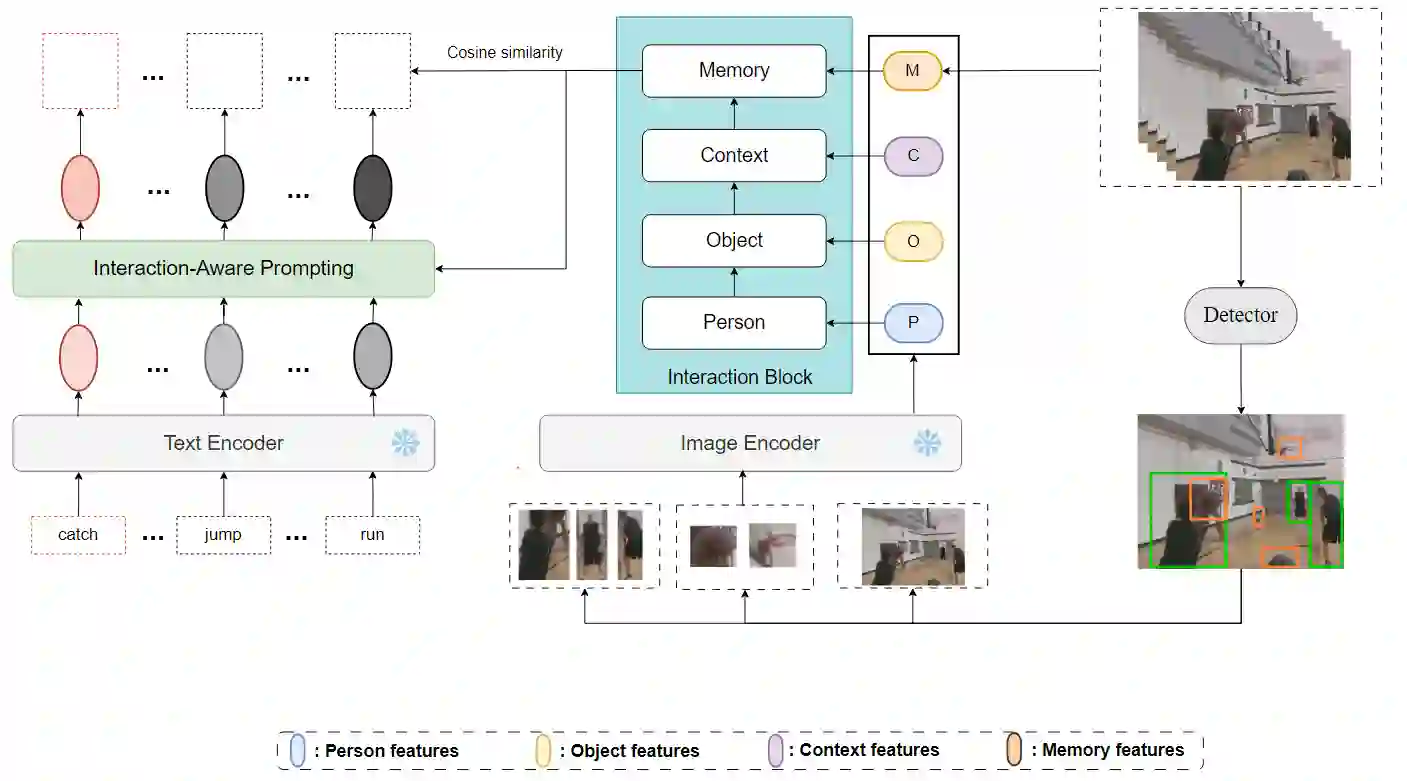
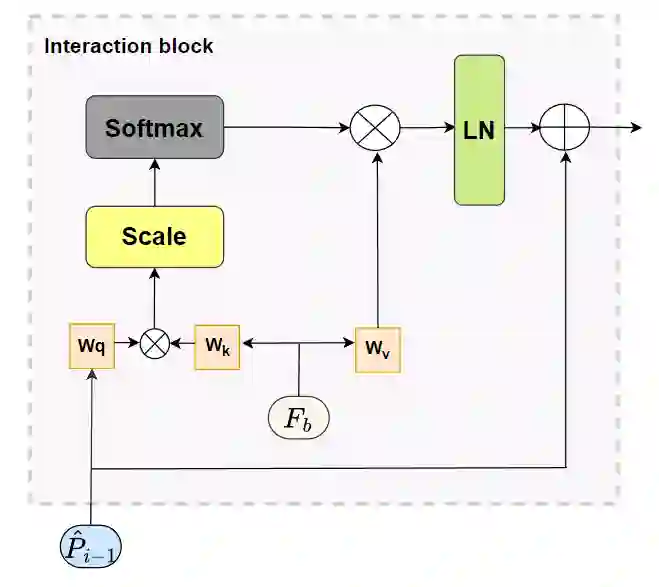
The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be available at https://github.com/webber2933/iCLIP.
翻译:时空动作检测的目标是确定视频中每个人物动作发生的时间和地点,并分类对应的动作类别。现有方法大多采用全监督学习,需要大量训练数据,这使得实现零样本学习非常困难。本文提出利用预训练的视觉-语言模型提取具有代表性的图像和文本特征,并通过不同的交互模块建模这些特征之间的关系以获得交互特征。此外,我们利用该特征对每个标签进行提示,以获取更合适的文本特征。最后,计算每个标签的交互特征与文本特征之间的相似度来确定动作类别。在J-HMDB和UCF101-24数据集上的实验表明,所提出的交互模块和提示方法能使视觉-语言特征更好地对齐,从而在零样本时空动作检测中达到优异的精度。相关代码将在https://github.com/webber2933/iCLIP 公开。