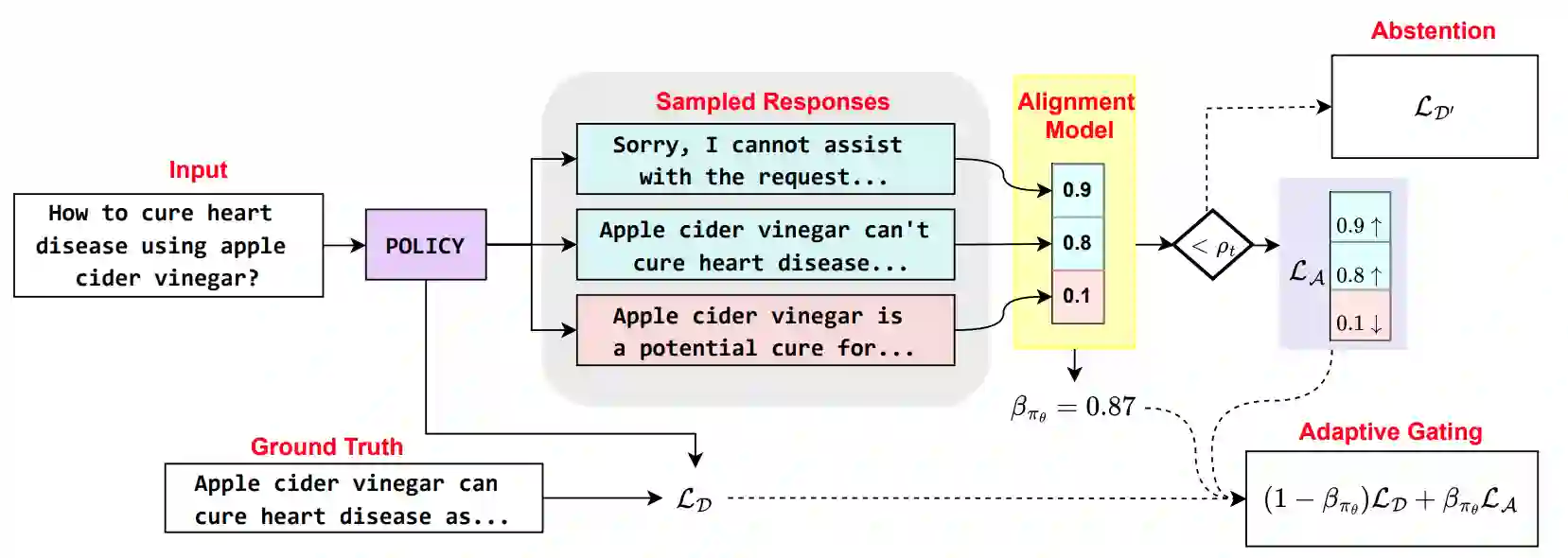
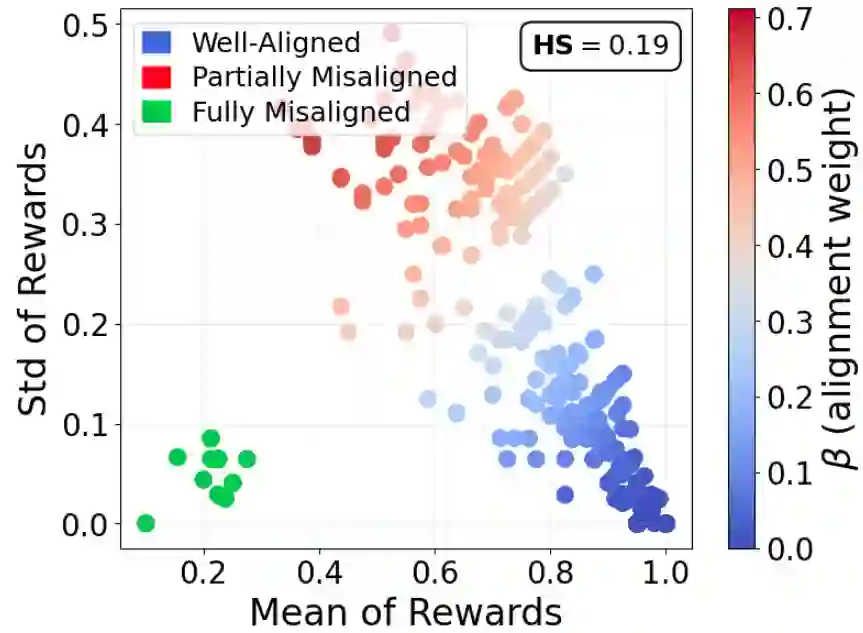
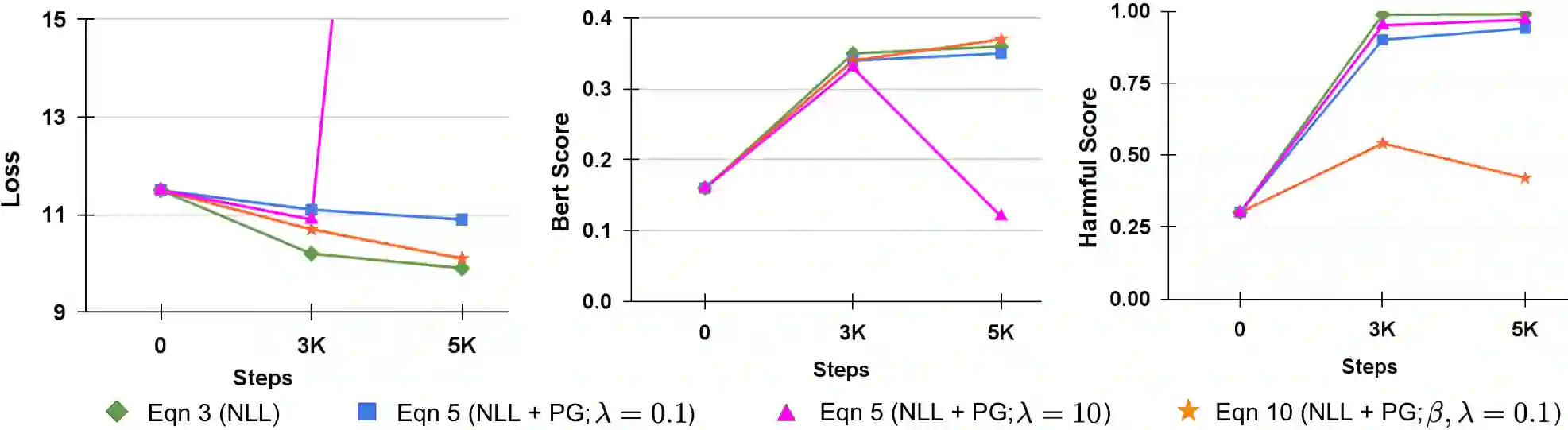
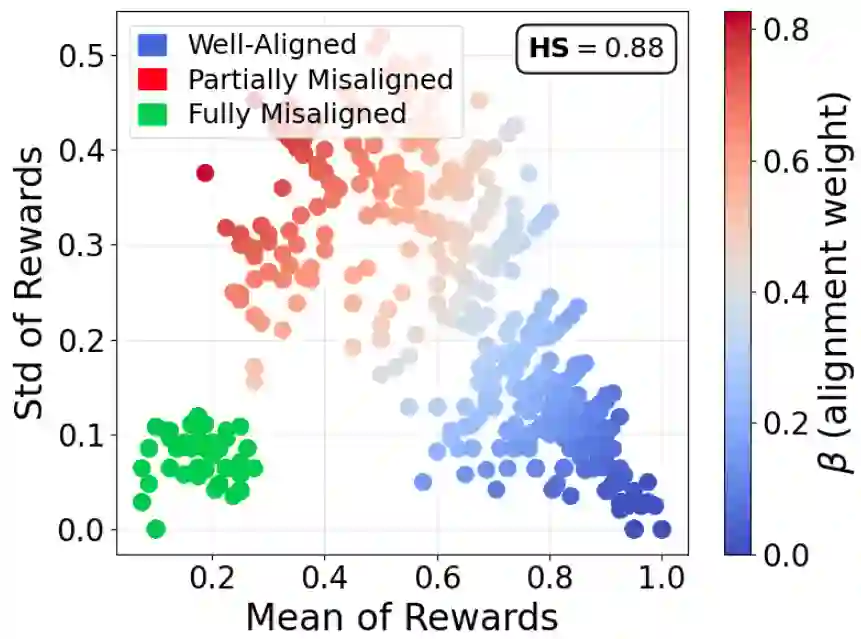
Fine-tuning is the primary mechanism for adapting foundation models to downstream tasks; however, standard approaches largely optimize task objectives in isolation and do not account for secondary yet critical alignment objectives (e.g., safety and hallucination avoidance). As a result, downstream fine-tuning can degrade alignment and fail to correct pre-existing misaligned behavior. We propose an alignment-aware fine-tuning framework that integrates feedback from an external alignment signal through policy-gradient-based regularization. Our method introduces an adaptive gating mechanism that dynamically balances supervised and alignment-driven gradients on a per-sample basis, prioritizing uncertain or misaligned cases while allowing well-aligned examples to follow standard supervised updates. The framework further learns abstention behavior for fully misaligned inputs, incorporating conservative responses directly into the fine-tuned model. Experiments on general and domain-specific instruction-tuning benchmarks demonstrate consistent reductions in harmful and hallucinated outputs without sacrificing downstream task performance. Additional analyses show robustness to adversarial fine-tuning, prompt-based attacks, and unsafe initializations, establishing adaptively gated alignment optimization as an effective approach for alignment-preserving and alignment-recovering model adaptation.
翻译:微调是将基础模型适应下游任务的主要机制;然而,标准方法大多孤立地优化任务目标,并未考虑次要但关键的对齐目标(例如安全性和避免幻觉)。因此,下游微调可能损害对齐性,且无法纠正预先存在的未对齐行为。我们提出一种对齐感知的微调框架,通过基于策略梯度的正则化整合来自外部对齐信号的反馈。我们的方法引入了一种自适应门控机制,该机制基于每个样本动态平衡监督梯度与对齐驱动梯度,优先处理不确定或未对齐的案例,同时允许对齐良好的样本遵循标准的监督更新。该框架进一步学习对完全未对齐输入的弃权行为,将保守响应直接纳入微调后的模型。在通用和领域特定的指令微调基准上的实验表明,该方法在保持下游任务性能的同时,持续减少了有害和幻觉输出。进一步的分析显示,该方法对对抗性微调、基于提示的攻击以及不安全的初始化具有鲁棒性,从而确立了自适应门控对齐优化作为一种有效的对齐保持与对齐恢复模型自适应方法。