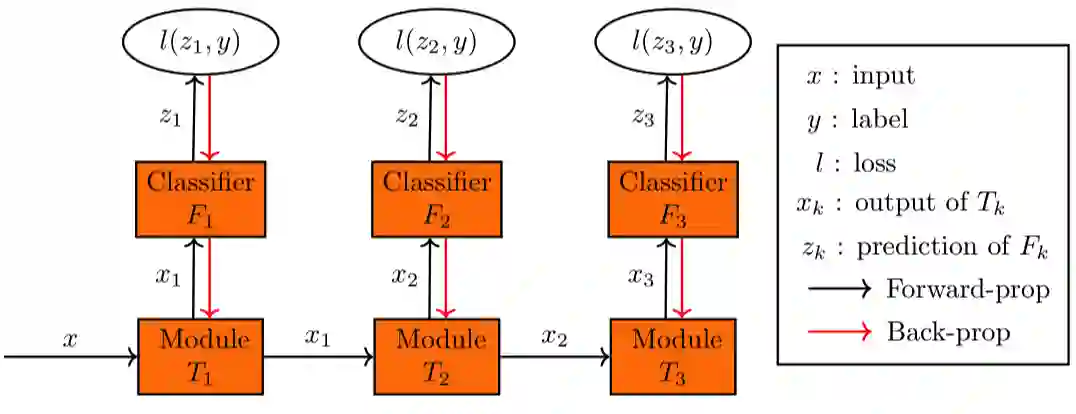
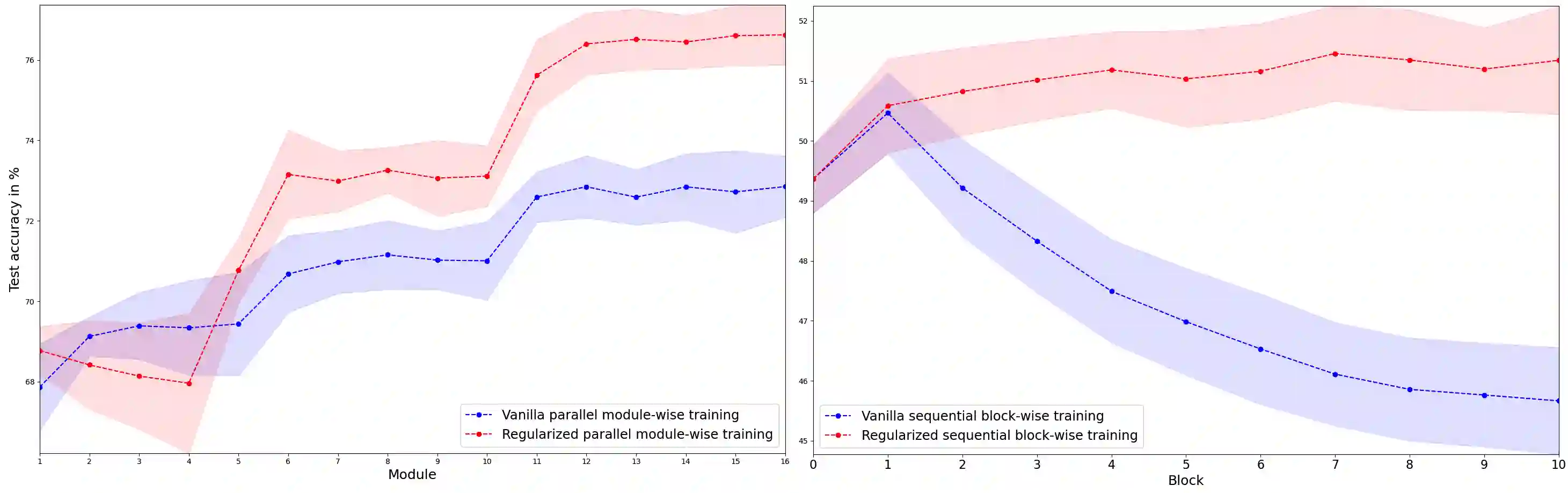
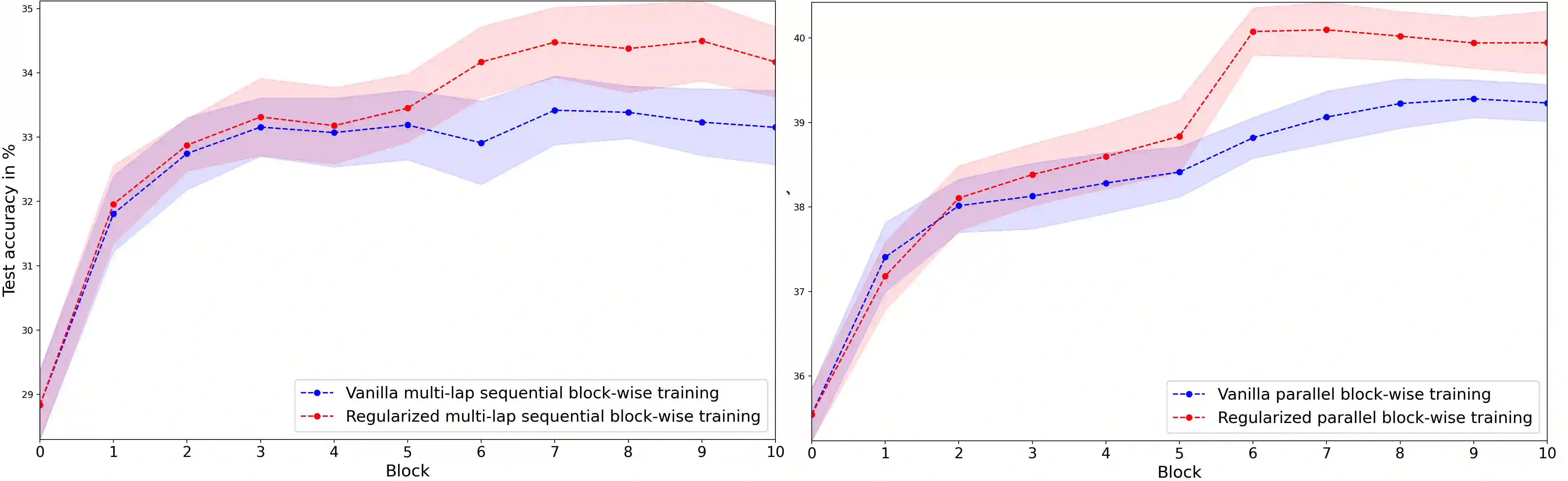
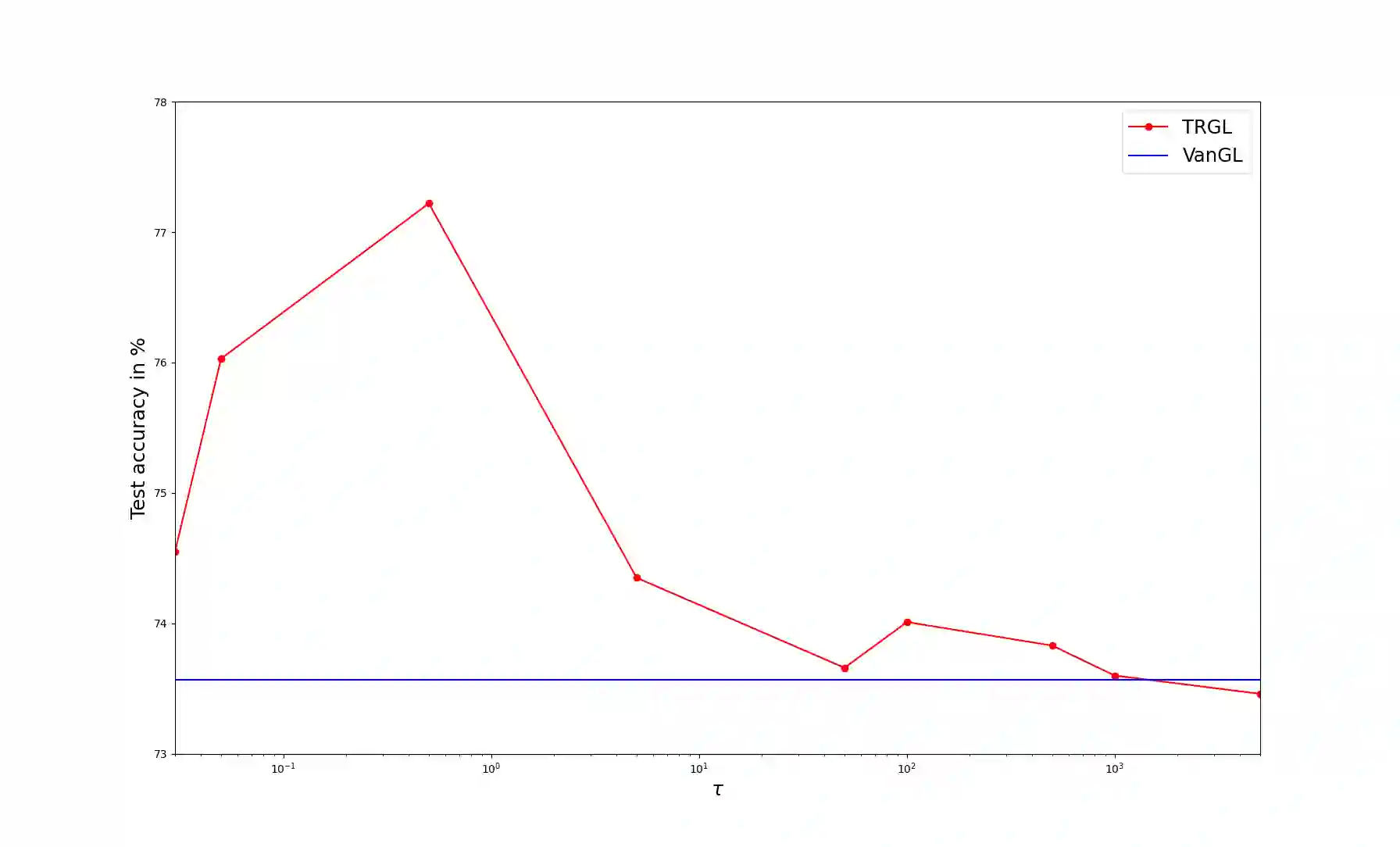
Greedy layer-wise or module-wise training of neural networks is compelling in constrained and on-device settings where memory is limited, as it circumvents a number of problems of end-to-end back-propagation. However, it suffers from a stagnation problem, whereby early layers overfit and deeper layers stop increasing the test accuracy after a certain depth. We propose to solve this issue by introducing a module-wise regularization inspired by the minimizing movement scheme for gradient flows in distribution space. We call the method TRGL for Transport Regularized Greedy Learning and study it theoretically, proving that it leads to greedy modules that are regular and that progressively solve the task. Experimentally, we show improved accuracy of module-wise training of various architectures such as ResNets, Transformers and VGG, when our regularization is added, superior to that of other module-wise training methods and often to end-to-end training, with as much as 60% less memory usage.
翻译:摘要:在内存受限的本地设备环境中,神经网络的贪婪逐层或模块化训练具有显著优势,因为它规避了端到端反向传播的诸多问题。然而,这类方法存在停滞问题:早期层出现过拟合,而深层在达到特定深度后无法继续提升测试准确率。针对该问题,我们提出通过引入基于分布空间梯度流的最小移动方案的正则化方法加以解决。该方法命名为TRGL(传输正则化贪婪学习),我们从理论上证明该方案能使贪婪模块保持正则化特性并逐步解决任务。实验表明,在ResNet、Transformer和VGG等不同架构中引入该正则化后,模块化训练的准确率显著提升,不仅优于其他模块化训练方法,且相比端到端训练可降低高达60%的内存使用量,同时保持相当甚至更优的性能表现。