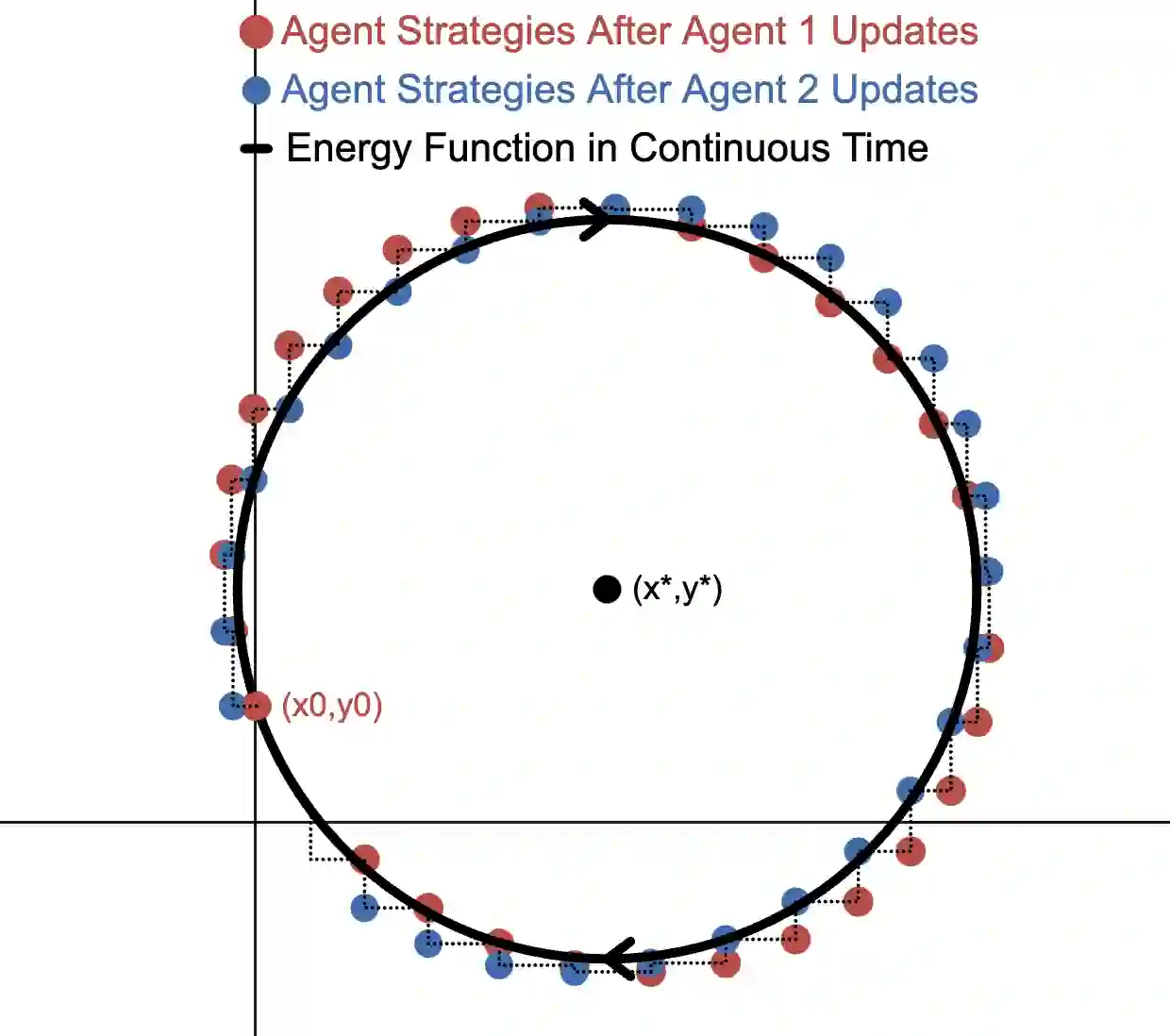
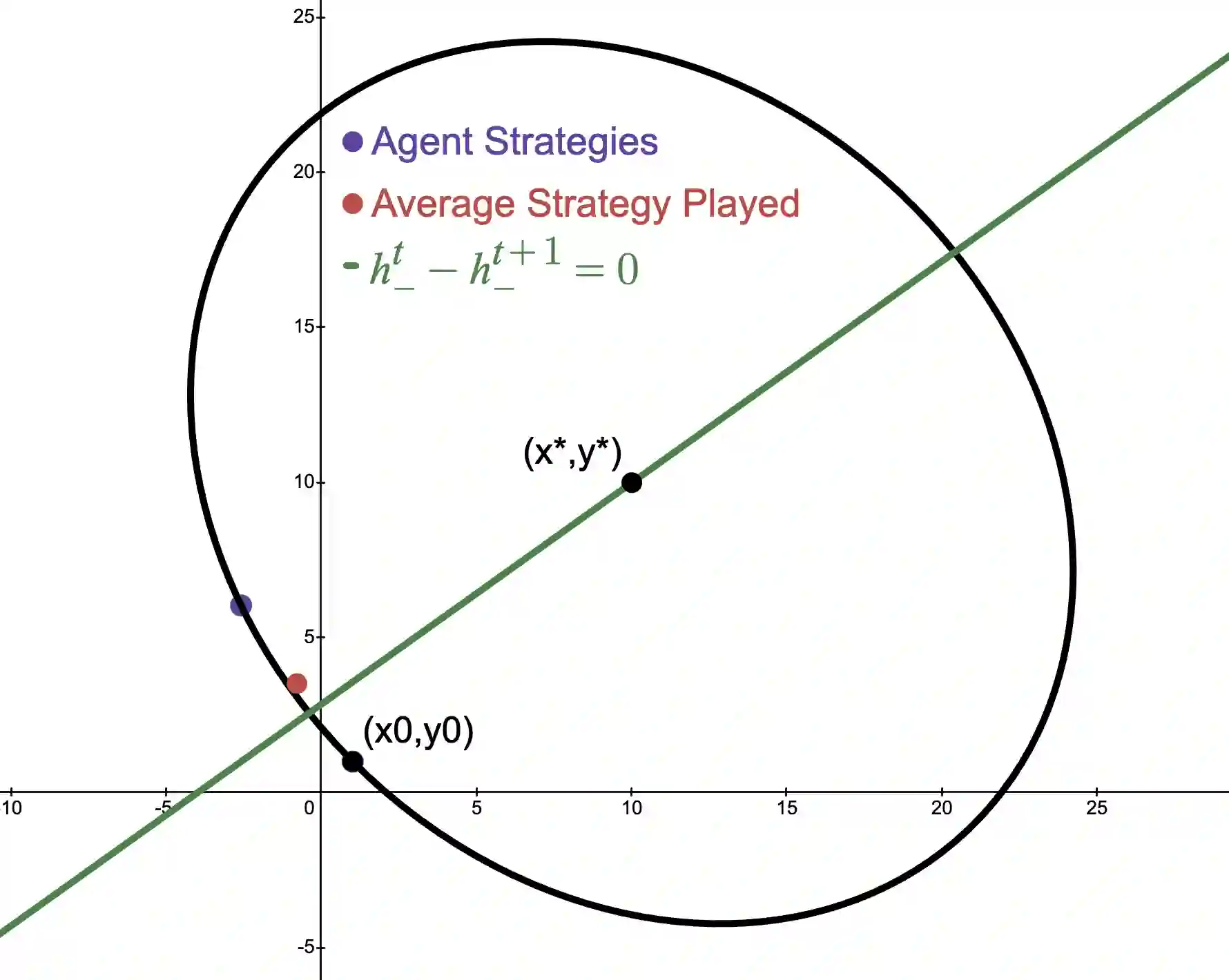
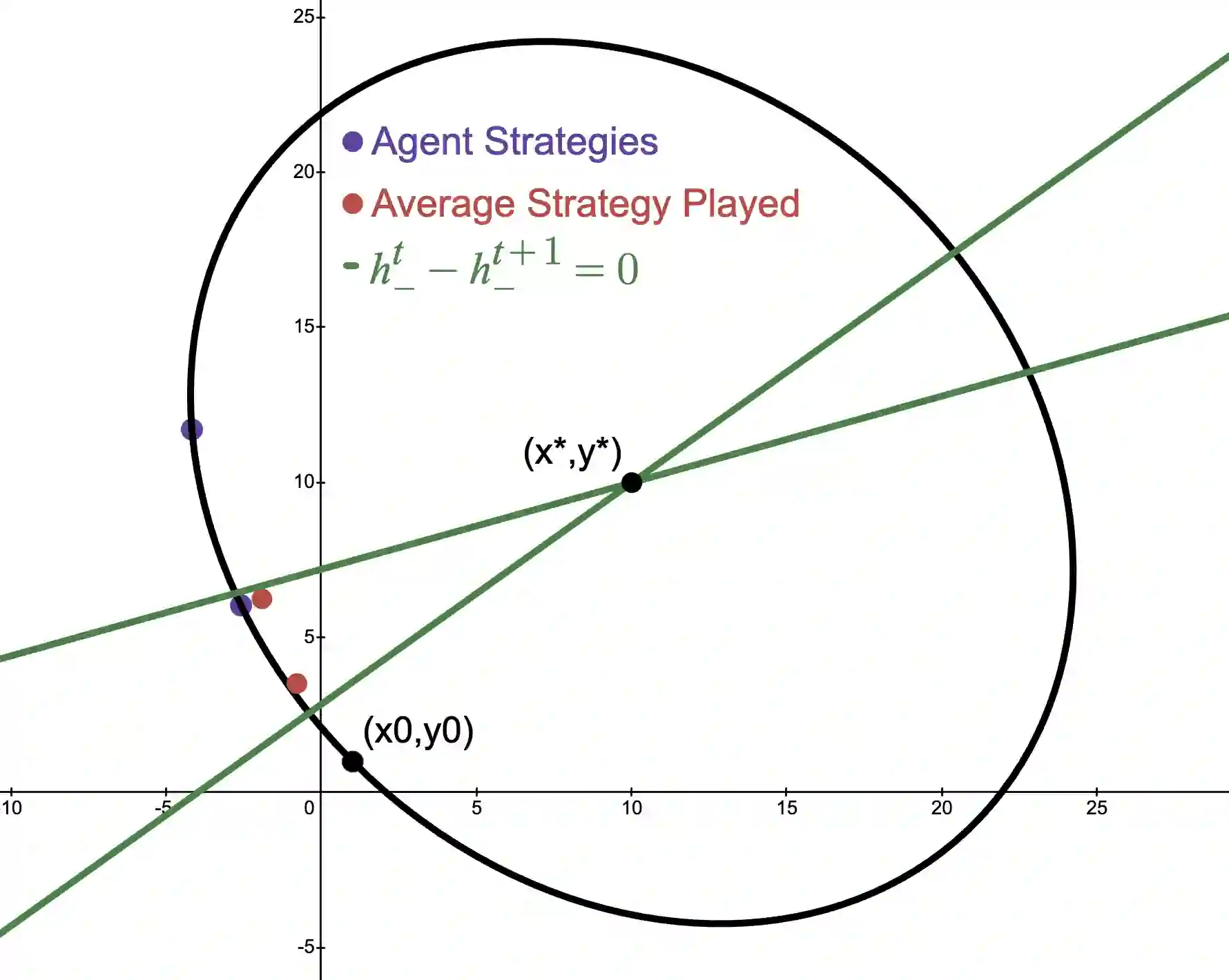
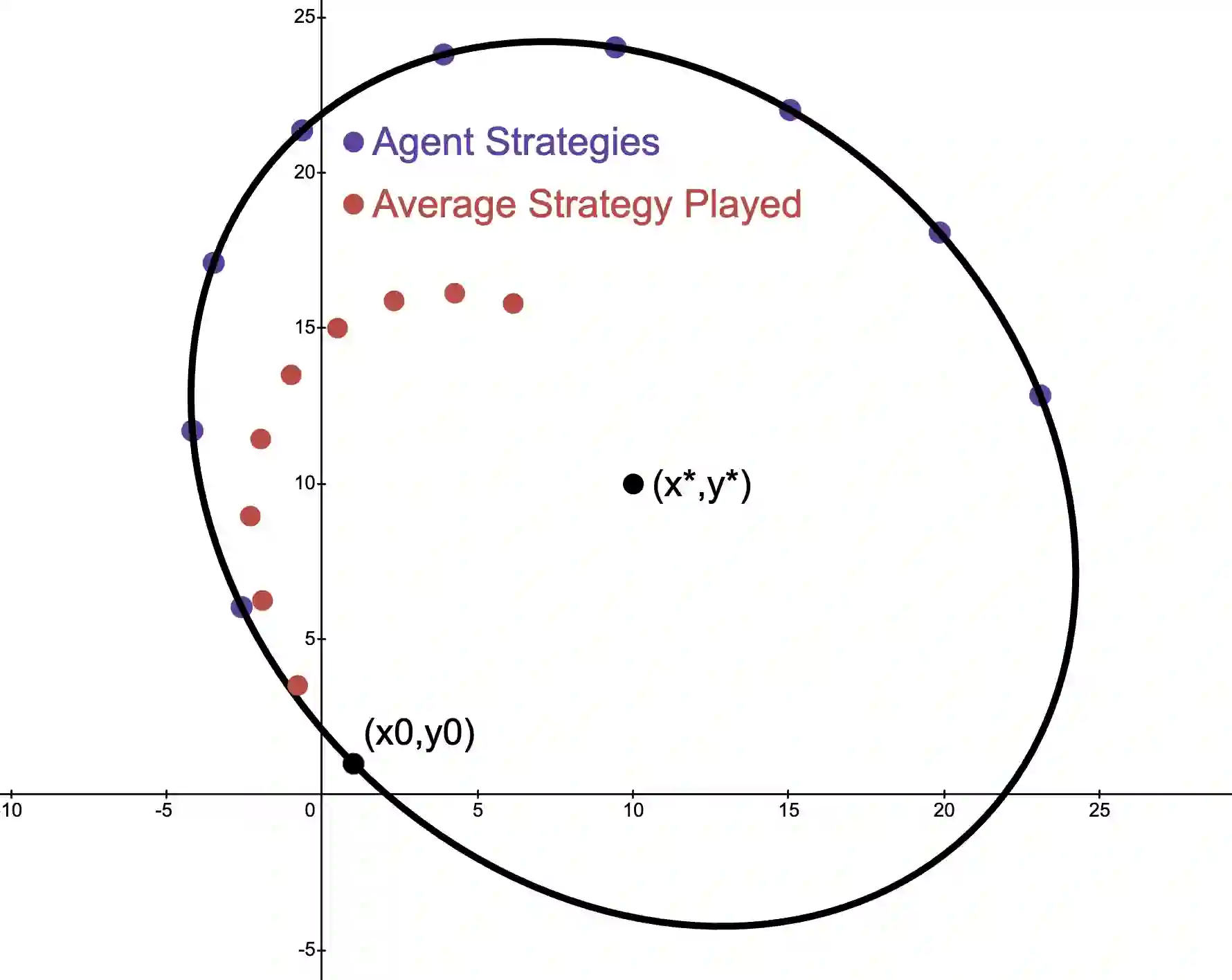
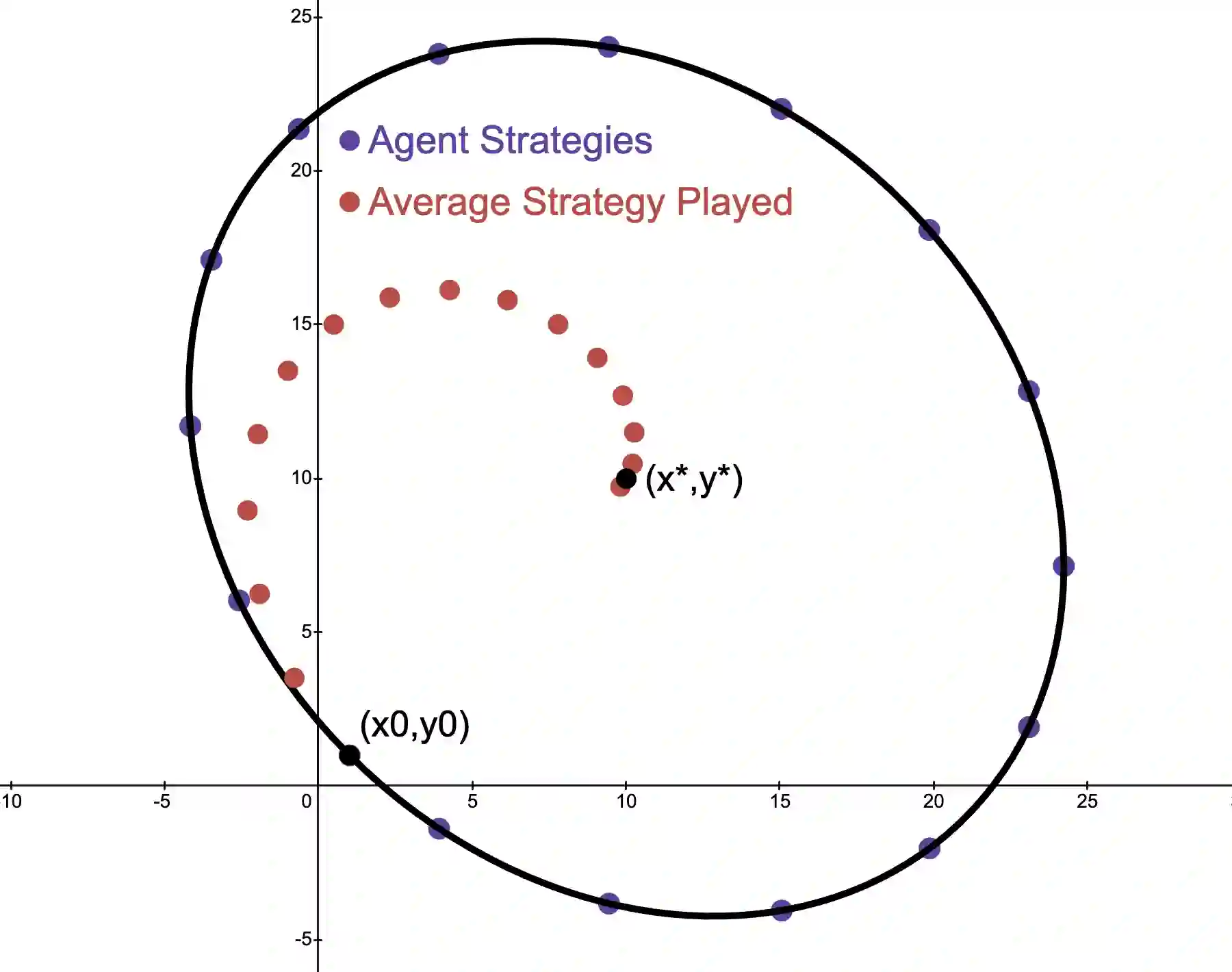
We study online optimization methods for zero-sum games, a fundamental problem in adversarial learning in machine learning, economics, and many other domains. Traditional methods approximate Nash equilibria (NE) using either regret-based methods (time-average convergence) or contraction-map-based methods (last-iterate convergence). We propose a new method based on Hamiltonian dynamics in physics and prove that it can characterize the set of NE in a finite (linear) number of iterations of alternating gradient descent in the unbounded setting, modulo degeneracy, a first in online optimization. Unlike standard methods for computing NE, our proposed approach can be parallelized and works with arbitrary learning rates, both firsts in algorithmic game theory. Experimentally, we support our results by showing our approach drastically outperforms standard methods.
翻译:我们研究零和博弈的在线优化方法,这是机器学习、经济学及众多领域中对抗学习的基础问题。传统方法通过基于遗憾的方法(时间平均收敛)或基于收缩映射的方法(最终迭代收敛)来近似纳什均衡。我们提出一种基于哈密顿动力学的新方法,并证明该方法能在无界设定下(除退化情形外),通过交替梯度下降的有限(线性)次迭代表征纳什均衡集,这在线优化领域尚属首次。与标准纳什均衡计算方法不同,我们提出的方法可并行化且适用于任意学习率,两者均为算法博弈论领域的首次突破。实验结果表明,我们的方法在性能上显著优于标准方法。