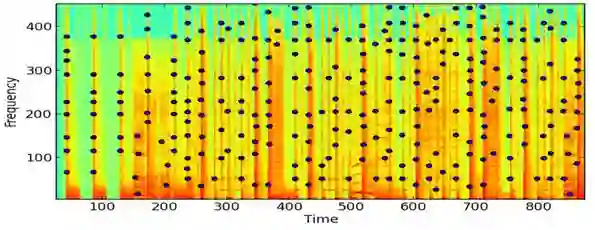
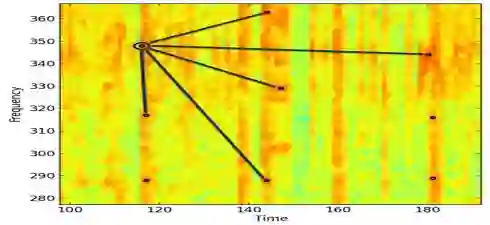
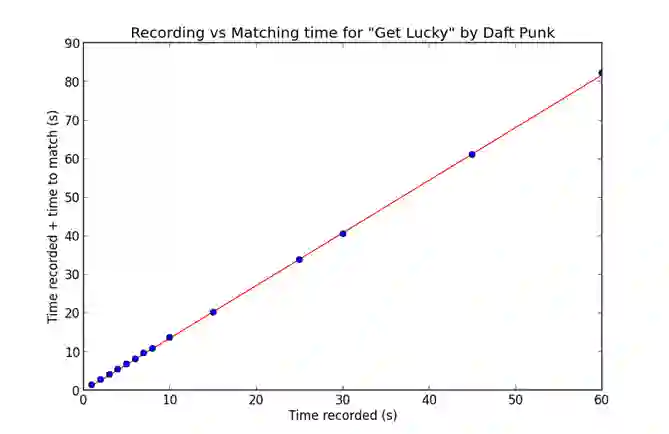
Audio fingerprinting, exemplified by pioneers like Shazam, has transformed digital audio recognition. However, existing systems struggle with accuracy in challenging conditions, limiting broad applicability. This research proposes an AI and ML integrated audio fingerprinting algorithm to enhance accuracy. Built on the Dejavu Project's foundations, the study emphasizes real-world scenario simulations with diverse background noises and distortions. Signal processing, central to Dejavu's model, includes the Fast Fourier Transform, spectrograms, and peak extraction. The "constellation" concept and fingerprint hashing enable unique song identification. Performance evaluation attests to 100% accuracy within a 5-second audio input, with a system showcasing predictable matching speed for efficiency. Storage analysis highlights the critical space-speed trade-off for practical implementation. This research advances audio fingerprinting's adaptability, addressing challenges in varied environments and applications.
翻译:音频指纹识别技术,以Shazam等先驱系统为例,已彻底改变了数字音频识别领域。然而,现有系统在复杂环境下的准确性仍面临挑战,限制了其广泛应用。本研究提出了一种集成人工智能与机器学习的音频指纹算法,旨在提升识别精度。基于Dejavu项目的基础架构,该研究重点构建了包含多种背景噪声和失真的真实场景模拟。信号处理作为Dejavu模型的核心环节,涵盖了快速傅里叶变换、频谱图生成及峰值提取。通过“星座图”概念与指纹哈希技术,实现了歌曲的唯一性识别。性能评估表明,在5秒音频输入内准确率达100%,系统匹配速度具有可预测性,验证了其高效性。存储分析揭示了实际部署中至关重要的空间与速度权衡问题。本研究推动了音频指纹技术在多变环境与应用场景中的适应性突破。