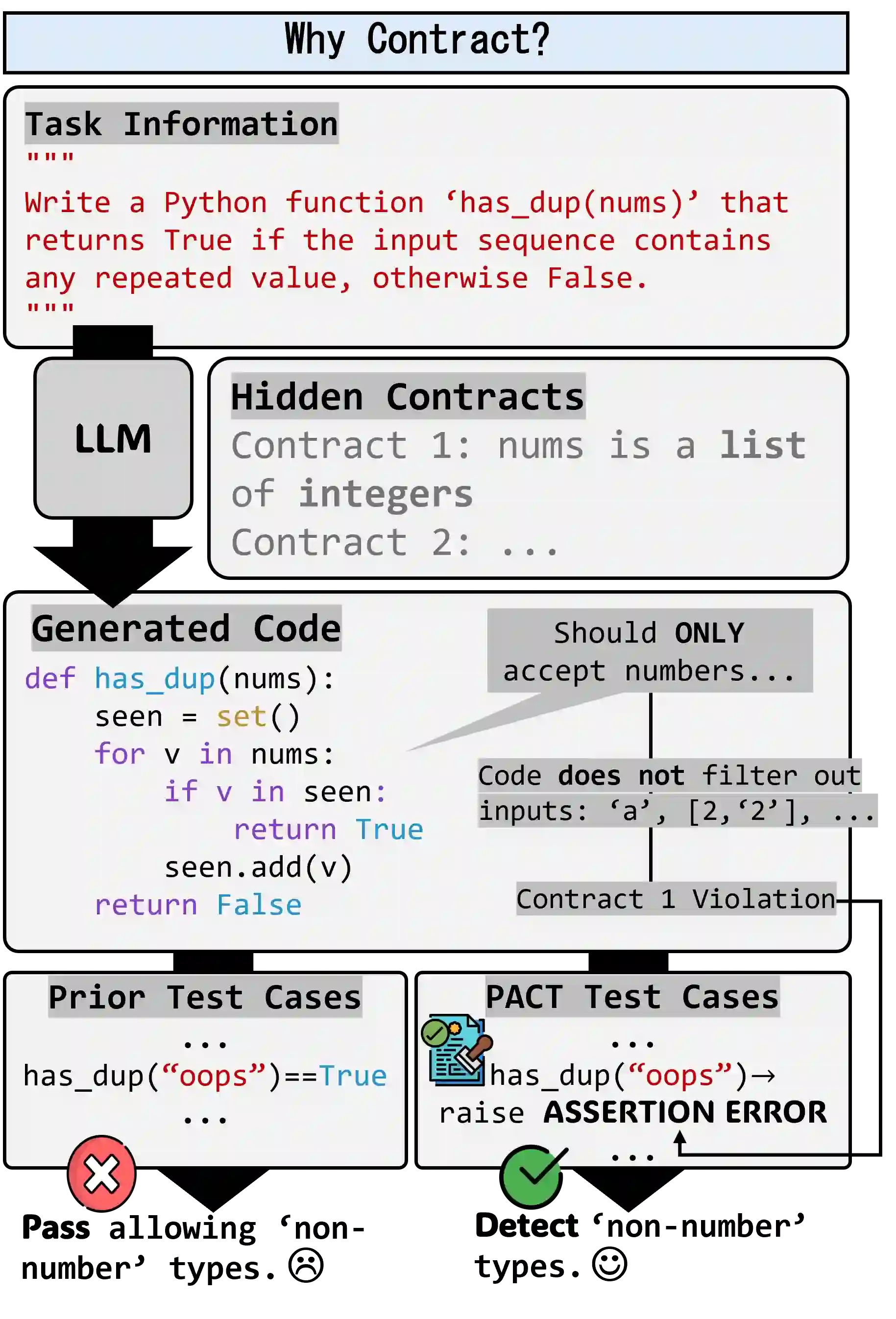
Prevailing code generation benchmarks, such as HumanEval+ and MBPP+, primarily evaluate large language models (LLMs) with pass@k on functional correctness using well-formed inputs. However, they ignore a crucial aspect of real-world software: adherence to contracts-the preconditions and validity constraints that dictate how ill-formed inputs must be rejected. This critical oversight means that existing benchmarks fail to measure, and models consequently fail to generate, truly robust and reliable code snippets. We introduce PACT, a program assessment and contract-adherence evaluation framework, to bridge this gap. PACT is the first framework designed to systematically evaluate and enhance contract-adherence in LLM-generated code snippets alongside functional correctness. PACT's contributions are threefold: First, it provides a comprehensive test-suite corpus focused on contract violations, extending HumanEval+ and MBPP+. Second, it enables a systematic analysis of code generation under varied prompting conditions. This analysis demonstrates that augmenting prompts with contract-violating test cases significantly enhance a model's ability to respect contracts compared to using contract description alone. Finally, it introduces novel metrics to rigorously quantify contract adherence in both test generation and code generation. By revealing critical errors that conventional benchmarks overlook, PACT provides the rigorous and interpretable metrics to evaluate the robustness of LLM-generated code snippets in both functionality and contract-adherence. Our code and data are available at https://github.com/suhanmen/PACT.
翻译:当前主流的代码生成基准测试,如HumanEval+和MBPP+,主要通过pass@k指标,使用格式良好的输入来评估大型语言模型(LLMs)的功能正确性。然而,它们忽略了现实世界软件的一个关键方面:对契约的遵循——即规定必须如何拒绝格式不良输入的前置条件和有效性约束。这一关键疏忽意味着现有基准测试未能衡量,模型也因此未能生成真正健壮和可靠的代码片段。为弥补这一差距,我们引入了PACT,一个程序评估与契约遵循性评估框架。PACT是首个旨在系统性地评估和增强LLM生成代码片段在功能正确性之外的契约遵循性的框架。PACT的贡献有三方面:首先,它提供了一个专注于契约违反的综合测试套件语料库,扩展了HumanEval+和MBPP+。其次,它支持在不同提示条件下对代码生成进行系统性分析。该分析表明,与仅使用契约描述相比,在提示中增加包含契约违反的测试用例能显著增强模型遵守契约的能力。最后,它引入了新颖的指标,以严格量化测试生成和代码生成中的契约遵循性。通过揭示传统基准测试所忽略的关键错误,PACT提供了严谨且可解释的指标,以评估LLM生成代码片段在功能和契约遵循性两方面的健壮性。我们的代码和数据可在https://github.com/suhanmen/PACT获取。