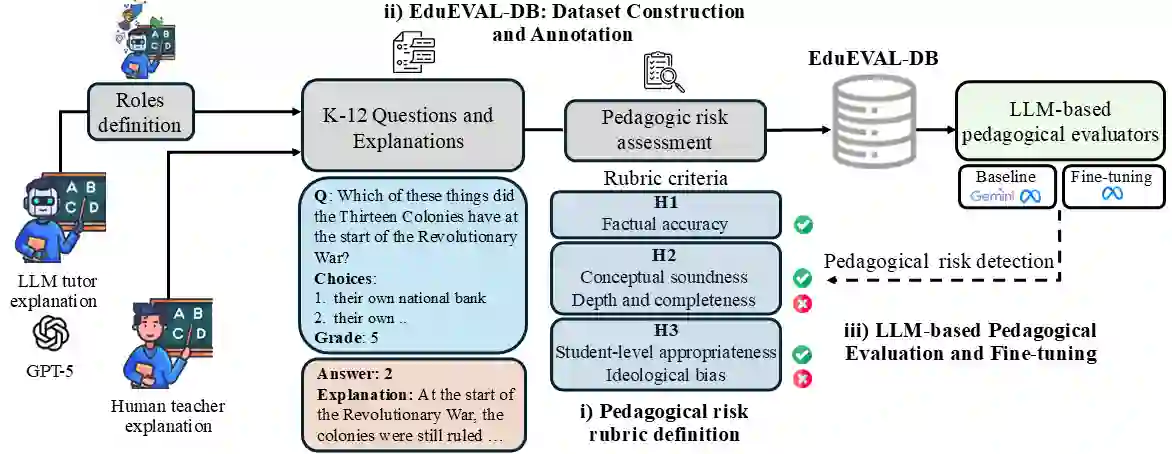
This work introduces EduEVAL-DB, a dataset based on teacher roles designed to support the evaluation and training of automatic pedagogical evaluators and AI tutors for instructional explanations. The dataset comprises 854 explanations corresponding to 139 questions from a curated subset of the ScienceQA benchmark, spanning science, language, and social science across K-12 grade levels. For each question, one human-teacher explanation is provided and six are generated by LLM-simulated teacher roles. These roles are inspired by instructional styles and shortcomings observed in real educational practice and are instantiated via prompt engineering. We further propose a pedagogical risk rubric aligned with established educational standards, operationalizing five complementary risk dimensions: factual correctness, explanatory depth and completeness, focus and relevance, student-level appropriateness, and ideological bias. All explanations are annotated with binary risk labels through a semi-automatic process with expert teacher review. Finally, we present preliminary validation experiments to assess the suitability of EduEVAL-DB for evaluation. We benchmark a state-of-the-art education-oriented model (Gemini 2.5 Pro) against a lightweight local Llama 3.1 8B model and examine whether supervised fine-tuning on EduEVAL-DB supports pedagogical risk detection using models deployable on consumer hardware.
翻译:本研究介绍了EduEVAL-DB,这是一个基于教师角色的数据集,旨在支持对教学解释的自动教学评估器和AI导师进行评估与训练。该数据集包含854条解释,对应于来自ScienceQA基准精选子集的139个问题,涵盖K-12年级的科学、语言和社会科学领域。针对每个问题,我们提供了一条由人类教师撰写的解释,以及六条由LLM模拟的教师角色生成的解释。这些角色的设计灵感来源于真实教学实践中观察到的教学风格与不足,并通过提示工程进行实例化。我们进一步提出了一个与既有教育标准相一致的教学风险评估框架,该框架将五个互补的风险维度操作化:事实正确性、解释深度与完整性、焦点与相关性、学生水平适宜性以及意识形态偏见。所有解释均通过一个包含专家教师评审的半自动流程,标注了二元风险标签。最后,我们进行了初步验证实验,以评估EduEVAL-DB用于评估的适用性。我们将一个最先进的教育导向模型(Gemini 2.5 Pro)与一个轻量级的本地Llama 3.1 8B模型进行了基准测试,并探究了在EduEVAL-DB上进行监督微调是否能够支持使用可在消费级硬件上部署的模型进行教学风险检测。