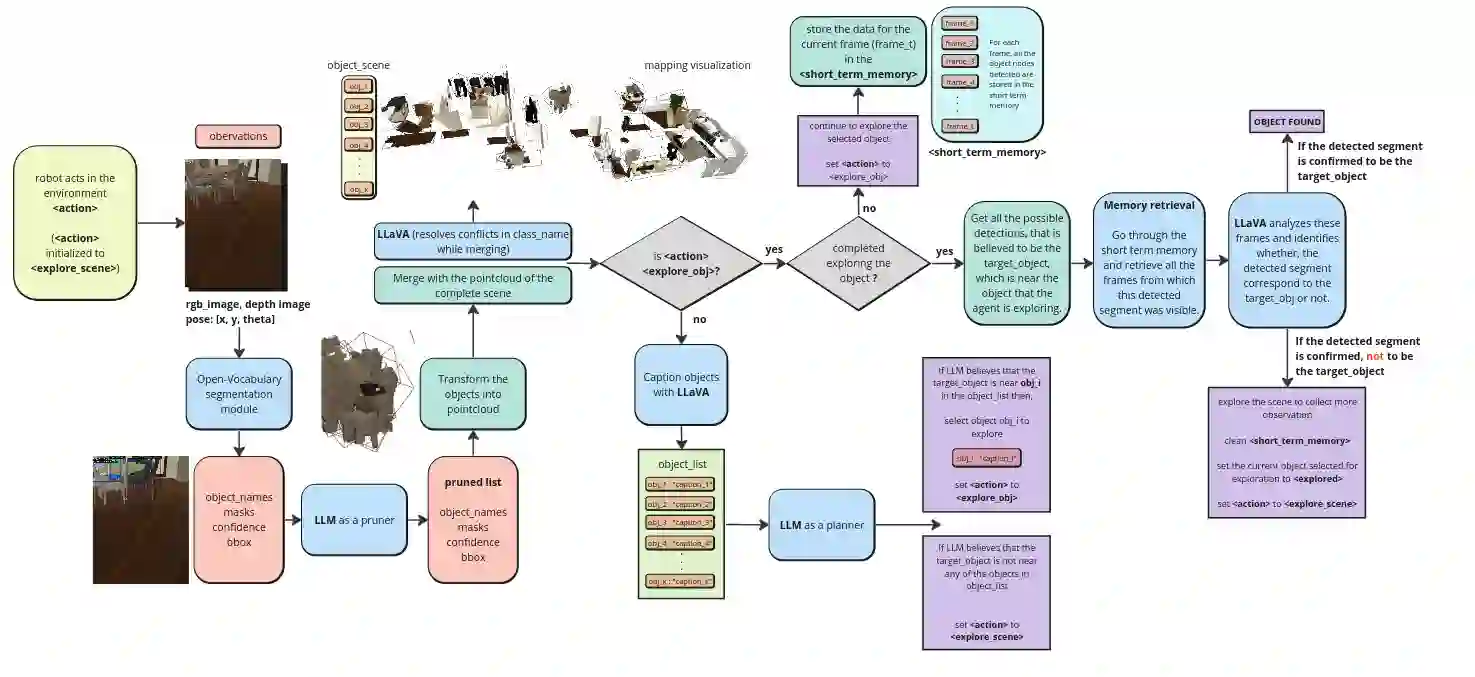
Recent advancements in Generative AI, particularly in Large Language Models (LLMs) and Large Vision-Language Models (LVLMs), offer new possibilities for integrating cognitive planning into robotic systems. In this work, we present a novel framework for solving the object goal navigation problem that generates efficient exploration strategies. Our approach enables a robot to navigate unfamiliar environments by leveraging LLMs and LVLMs to understand the semantic structure of the scene. To address the challenge of representing complex environments without overwhelming the system, we propose a 3D modular scene representation, enriched with semantic descriptions. This representation is dynamically pruned using an LLM-based mechanism, which filters irrelevant information and focuses on task-specific data. By combining these elements, our system generates high-level sub-goals that guide the exploration of the robot toward the target object. We validate our approach in simulated environments, demonstrating its ability to enhance object search efficiency while maintaining scalability in complex settings.
翻译:生成式人工智能的最新进展,特别是大语言模型(LLMs)和大视觉语言模型(LVLMs),为将认知规划集成到机器人系统中提供了新的可能性。本研究提出了一种解决物体目标导航问题的新颖框架,该框架能够生成高效的探索策略。我们的方法使机器人能够利用LLMs和LVLMs来理解场景的语义结构,从而在陌生环境中进行导航。为了解决在不使系统过载的情况下表示复杂环境的挑战,我们提出了一种富含语义描述的三维模块化场景表示方法。该表示通过一个基于LLM的机制进行动态剪枝,该机制过滤无关信息并聚焦于任务相关数据。通过结合这些要素,我们的系统生成了高级子目标,以引导机器人向目标物体进行探索。我们在仿真环境中验证了所提出的方法,证明了其能够在保持复杂场景中可扩展性的同时,有效提升物体搜索效率。